
2021 has been a year where many things have happened very quickly at Damavis. In this last post before the arrival of 2022, we will make a summary of the contents published in our blog throughout all these months.
Damavis Blog contents in the first half of the year
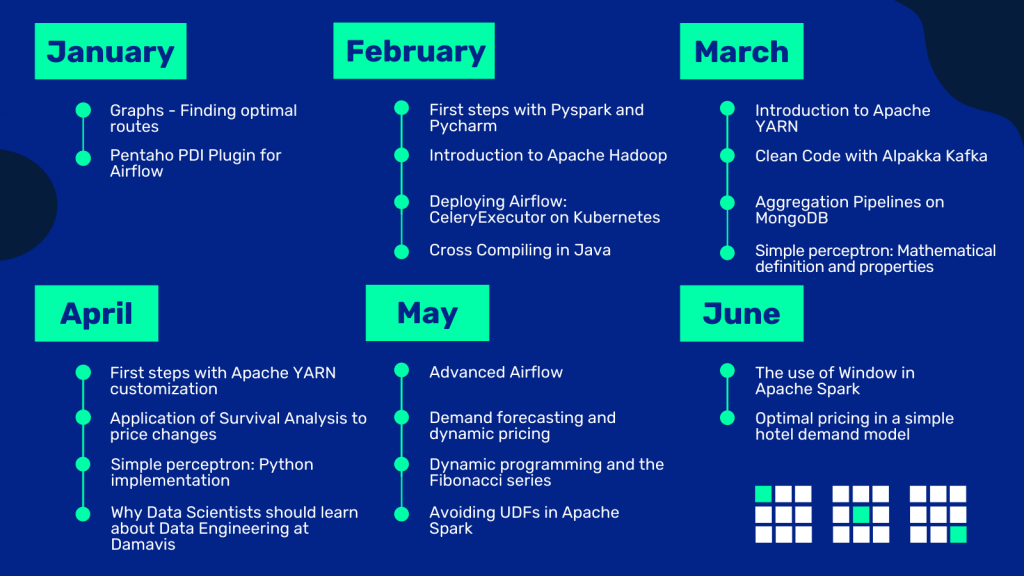
In January we saw how we can approach projects of optimization of purchase / sale rules, fleet fuel savings, distribution of goods or optimization of warehouse space, showing a simple example of route optimization with graphs.
We also released under free license our Pentaho PDI Plugin for Airflow, with which many companies can orchestrate their batch data flows from Airflow.
In February we showed how to take the first steps with PySpark and PyCharm. We saw an interesting introduction to Apache Hadoop and the steps to set up a local node to do your first tests. We did a deployment of CeleryExecutor in Kubernetes, on Airflow. And we dealt with old versions of code, explaining how to perform a Cross Compilation in Java.
In March we got down to work with an introduction to Apache Yarn, taking advantage of the knowledge already explained in the previous month. We reviewed Clean Code best practices with Alpakka Kafka with an Akka Stream example. We also touched on the topic of databases, explaining the Aggregation Pipelines in MongoDB. And we delve into the world of neural networks with the mathematical definition of a simple perceptron.
As April arrived we discussed the first steps of Apache Yarn customization. We went into the world of price change Survival Analysis and how this process can bring a lot of value in caching systems. We put on the table why we believe a Data Scientist should learn about Data Engineering. And with what we learned during the previous month, we made a Python implementation of a Simple Perceptron.
During May we performed an Advanced Airflow exercise, dealing with dependencies between tasks and Cross-Dag sensors. We delved into the exciting world of Demand Forecasting and Dynamic Pricing. We reviewed an example of Dynamic Programming working with the Fibonacci series. And we saw how and when to avoid using UDFs in Apache Spark.
June allowed us to talk about the use of Window in Apache Spark, looking at both analytical and aggregation functions that we can use with this interesting practice. And we published the definition of the problem of an optimal pricing system on a simple model of hotel demand.
Second half of 2021 in our Blog
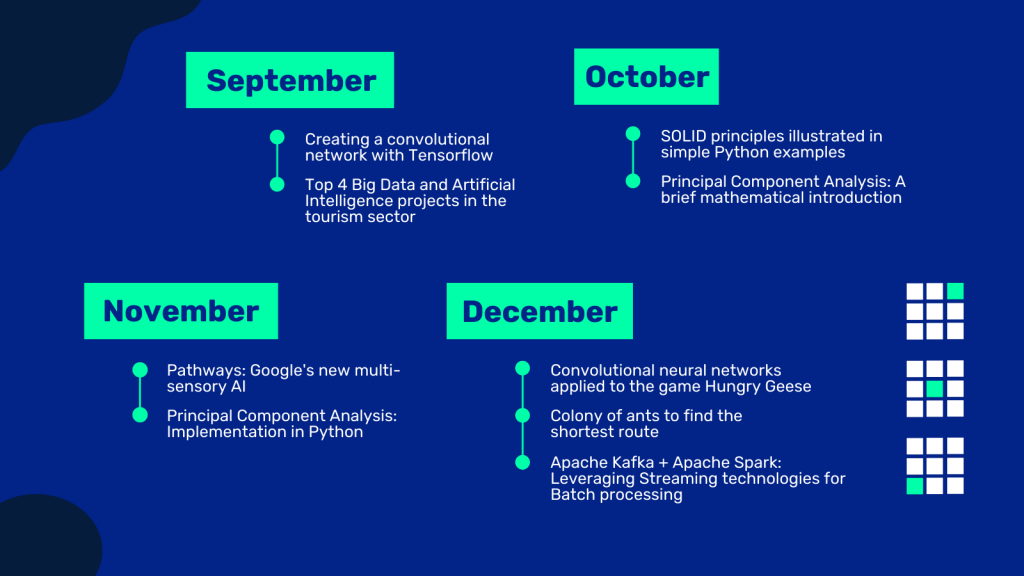
In July and August we took a well-deserved vacation in the technical publications of the blog, but we returned to the load in September with the creation of a convolutional network with TensorFlow and we talked about the Top 4 Big Data and Artificial Intelligence projects in the tourism sector.
During October we addressed topics such as SOLID principles with simple examples in Python and a mathematical introduction to PCA (principal component analysis).
Already in the run up to the end of the year during November, we looked at Pathways, Google’s new multisensory AI, and how these advances can bring a lot of value to the new AI projects we do. And we delved into the world of PCAs with a Python implementation.
And to close the year, in December we talked about convolutional neural networks, we saw how we can use collective intelligence to find short paths with an example of artificial ants. And we have seen how to use Apache Kafka and Apache Spark with Streaming technologies for Batch processing.
It is clear that during this 2021 the Damavis team has grown both in number and in the knowledge we acquire, so we use among other things this blog to share our experience and bring it closer to anyone who wants to get into the world of Big Data and Artificial Intelligence.
