
Batch processing is a methodology widely used in the world of Big Data. Throughout this post, we will analyse how technologies typically used for streaming -such as Apache Kafka and Apache Spark– can ve leveraged for batch data processing.
What is an ETL/ELT process?
An ETL/ELT process is the cornerstone ob a Big Data project. The key activities involved in implementing it include collecting, ingesting, integrating, processing, storing and analysing large volumes of information. Combining these tasks that provides a solid foundation for subsequent descriptive and predictive analytics, with specific projects and use cases.
There are a multitude of tools and technologies that work together and the choice of each one depending on the specific characteristics of the problem is what determines the viability of a project, both in terms of budget and efficiency of the solution.
In this post we will focus on the information processing component. This part is of special interest due to the large amount of information together with the different origin and format of the data. This set of tasks has the responsibility to homogenize and enrich the raw data to answer different questions with value for the business unit.
With the management of large volumes of data, there is no predefined technique for processing. However, there are different paradigms, which we will explain in more detail in future blog posts, to carry out these processes, each with specific characteristics and a wide technological stack of its own.
Differences between batch processing and streaming
The batch processing paradigm is based on performing transformations periodically on a finite subset of the information. As a basic example it could be the ingest and transformation of a business component on a daily basis. This paradigm is useful in situations where there is a large volume of information, gaining great importance the use of programming models such as MapReduce and distributed information processing.
On the other hand, we can find the Streaming processing paradigm. While the previous one is processed periodically, in this case the data are processed at the moment they are ingested immediately. This means that the volume of data being processed is smaller since it can be done both in “real-time” and in “micro-batches” (very small periods of time). The use of this paradigm is useful in situations where it is required that the information is usable for decision making in a short period of time, examples of use can be the monitoring of logs or fraud detection.
Finally, we can highlight the Lambda paradigm, attributed to Nathan Marz in 2012. Based on three layers (Batch, Speed and Serving), it offers a hybrid solution. Furthermore, it is increasingly being used in the industry due to the flexibility it provides.
How processing works in Apache Kafka
Entering the streaming processing technologies, Apache Kafka appears as an open-source tool for message distribution that allows to publish, store logs, as well as to consume them in real time.
The way Apache Kafka works is that producer applications publish events in different data streams called topics. The consumer applications can subscribe to the different topics to obtain and process the events. Each topic is partitioned, so that when an event is published, the record is stored in one of the partitions as shown in the following figure.
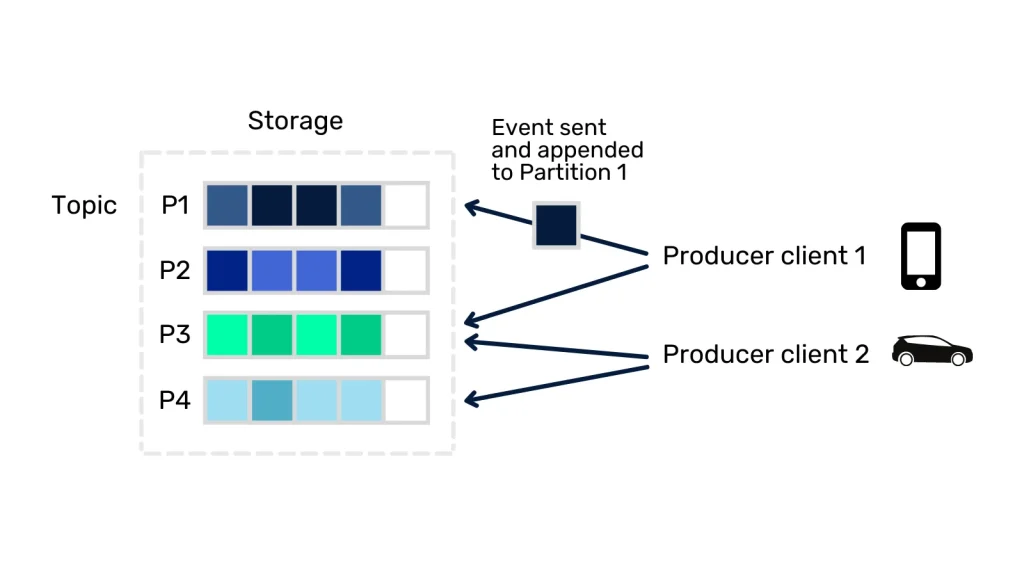
One of the major problems to be solved by messaging systems is the management of which messages have been consumed. Kafka guarantees that any consumer will always read the events in the same order in which they were written, this is achieved from the offsets. The offset is a simple integer used by Kafka to contain the position of the last record that has been consumed. This allows us to avoid that the same event is sent to the same consumer.
Example of architecture using Kafka and Spark
We can imagine a scenario with Apache Kafka architecture where raw data is transformed from Apache Spark jobs.
In this case, there may be situations that require the raw data to be reprocessed. An example may be the detection of a bug in the Spark job by the development team or the need to implement an unplanned transformation, these may be reasons that cause reprocessing to be necessary. In this context, a solution must be obtained that allows the events to be consumed from a specific moment in time.
How to fix the problem
The optimal solution will depend on the version of Apache Spark you are using.
In former versions to Spark 3.0 a search for the offset corresponding to the target timestamp must be performed. This can be done using the offsets_for_times (timestamps) function of the kafka-python library. Returning a dictionary with the partitions and the nearest offset to the corresponding timestamp.
KafkaConsumer.offsets_for_times({TopicPartition: Int})
The result can be entered into the Spark consumer with the startingOffsets/endingOffsets option.
def read(self, topic, start_offset, end_offset) -> DataFrame:
return self.spark.read.format("kafka") \
.option("kafka.bootstrap.servers", “bootstrap_server”) \
.option("subscribe", “topic_example”) \
.option("startingOffsets", start_offset) \
.option("endingOffsets", end_offset) \
.load()As we can see, this process requires new programmatic development to obtain the corresponding offsets, adding unwanted complexity to the problem.
From Spark 3.0, a build-in solution appears by using specific parameters in the read configuration. This solution allows delegating the responsibility of finding the corresponding offsets to Spark, so the need to add code disappears, simplifying the solution considerably.
Solution in Spark 3.0.0
def read(self, topic, start_offset, end_offset) -> DataFrame:
return self.spark.read.format("kafka") \
.option("kafka.bootstrap.servers", “bootstrap_server”) \
.option("subscribe", “topic_example”) \
.option("startingOffsetsByTimestamp", start_timestamp) \
.option("endingOffsetsByTimestamp", end_timestamp) \
.load()The parameters startingOffsetsByTimestamp/endingOffsetsByTimestamp in json string format being """ {"topicA":{"0": 1000, "1": 1000}, "topicB": {"0": 2000, "1": 2000}} “""
Solution in Spark 3.2.0
def read(self, topic, start_offset, end_offset) -> DataFrame:
return self.spark.read.format("kafka") \
.option("kafka.bootstrap.servers", “bootstrap_server”) \
.option("subscribe", “topic_example”) \
.option("startingTimestamp", start_timestamp) \
.option("endingTimestamp", end_timestamp) \
.load()The parameters startingTimestamp/endingTimestamp being in string format representing a timestamp.
Conclusion
As we can see, with higher versions of Apache Spark 3.0.0 we can efficiently reprocess information from a specific timestamp, giving greater versatility to the tool and allowing the efficient consumption of information in batches. In this way, we have a solution that allows periodic data processing on a scalable and flexible technical architecture, which would also support the paradigm of information streaming processing.
If you found this article interesting, we encourage you to visit the Data Engineering category of our blog to see posts similar to this one and to share it in networks with all your contacts. Don’t forget to mention us to let us know your opinion @Damavisstudio. See you soon!
