In the world of Data Engineering, it is well known that the use of UDFs (User Defined Functions) in Apache Spark (especially with the Python API) can compromise our application performace. For this reason, at Damavis we try to avoid their use as much as possible in favour of using native functions or SQL.
In this article, we will review some of the less common functions of Apache Spark library and how they work through practical examples.
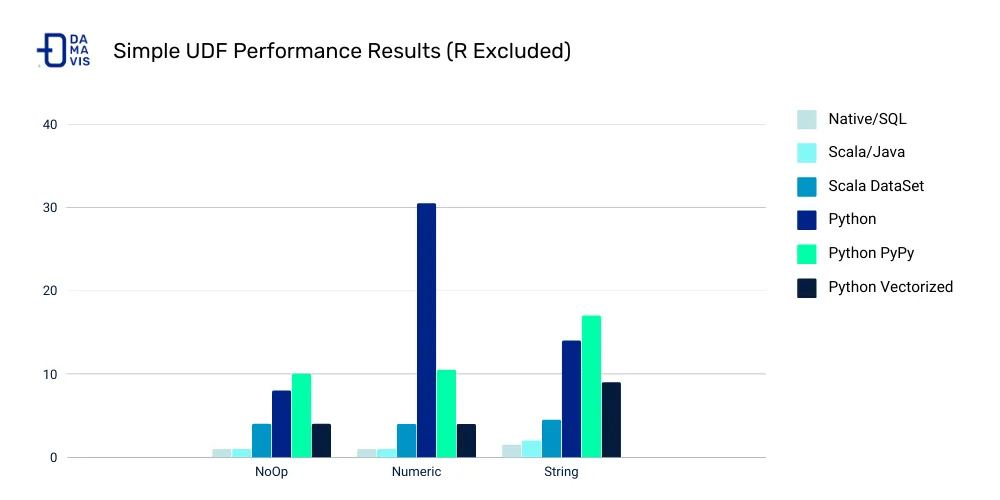
Why avoid using UDFs in Spark?
To put this into context and understand why we avoid using UDFs, we first need to understand the Spark architecture and how the Python API and Apache Spark are integrated. To do this, we will focus on this API because it is the most popular and the one that most penalises the use UDFs (excluding the R API).
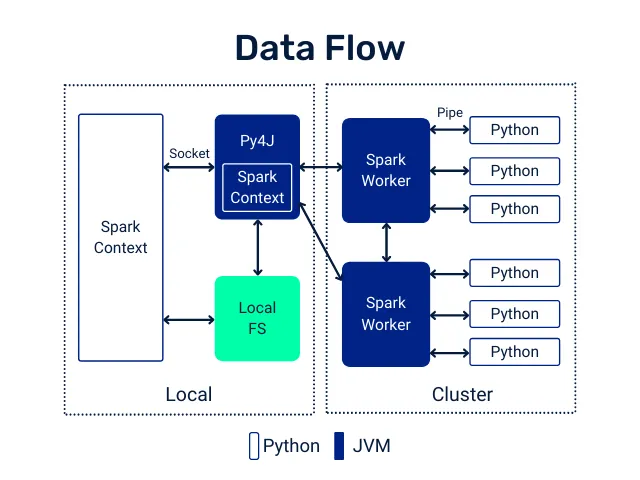
The Apache Spark engine is implemented in Java and Scala, languages that run on the JVM (Java Virtual Machine). The use of the Python API requires an interaction between that JVM and the Python Runtime. All this interaction is possible thanks to a library called py4j, which allows us to call code from the JVM. At the same time, each Spark worker will have a Python Runtime running to, for example, execute UDFs.
When we execute a DataFrame transformation using native or SQL functions, each of those transformations happen inside the JVM itself, which is where the implementation of the function resides. But if we do the same thing using Python UDFs, something very different happens.
First of all, the code cannot be executed in the JVM, it will have to be in the Python Runtime. To make this possible, each row of the DataFrame is serialised, sent to the Python Runtime and returned to the JVM (represented as Pipe in the image). As you can imagine, it is nothing optimal.
There are usually some projects that try to optimise this problem. One of them is Apache Arrow, which is based on applying UDFs with Pandas. However, in this article what we want to do is to try and avoid them whenever it’s possible. Nevertheless, if you want to know more details, you can visit the post on How to optimise UDFs in Python for Arrow in Spark.
Example of transformations on Array-type columns
Next, we are going to see two very specific examples about transformations in Array type columns that have caused us some performance problems and that we have solved by replacing those UDFs.
Filtered Arrays
Sometimes we encounter columns of Array [T] type and we want to apply a filter. Suppose we have the following DataFrame:
+-------+--------------+
|room_id| guests_ages|
+-------+--------------+
| 1| [18, 19, 17]|
| 2| [25, 27, 5]|
| 3|[34, 38, 8, 7]|
+-------+--------------+Let’s imagine that our goal is to add a column with the ages of the adults in each room. One of the obvious options is to use a UDF, let’s see the example:
from pyspark.sql.functions import udf, col
@udf("array<integer>")
def filter_adults(elements):
return list(filter(lambda x: x >= 18, elements))
...
+-------+----------------+------------+
|room_id| guests_ages | adults_ages|
+-------+----------------+------------+
| 1 | [18, 19, 17] | [18, 19]|
| 2 | [25, 27, 5] | [25, 27]|
| 3 | [34, 38, 8, 7] | [34, 38]|
| 4 |[56, 49, 18, 17]|[56, 49, 18]|
+-------+----------------+------------+To avoid the use of this UDF, we will need to refer to a native function called filter. This function has not been available in the pyspark.sql.functions package until version 3.1, so let’s see examples of how to do it in Spark 2.x and Spark 3.1.
# Spark 2.x/3.0
from pyspark.sql.functions import col, expr, lit
df.withColumn('adults_ages',
expr('filter(guests_ages, x -> x >= 18)')).show()
# Spark 3.1
from pyspark.sql.functions import col, filter, lit
df.withColumn('adults_ages',
filter(col('guests_ages'), lambda x: x >= lit(18))).show()
...
+-------+----------------+------------+
|room_id| guests_ages| adults_ages|
+-------+----------------+------------+
| 1| [18, 19, 17]| [18, 19]|
| 2| [25, 27, 5]| [25, 27]|
| 3| [34, 38, 8, 7]| [34, 38]|
| 4|[56, 49, 18, 17]|[56, 49, 18]|
+-------+----------------+------------+Array transformation
In some cases, we may have the need to transform elements within an array, also in a conditional manner. Let’s suppose we have the following DataFrame:
+-----------+----------------------------------------------------------+
|customer_id|monthly_spend |
+-----------+----------------------------------------------------------+
|1 |[18.0, 19.0, 17.0, 19.0, 23.0, 12.0, 54.0, 14.0, 16.0, 19.0, 12.0, 9.0] |
|2 |[25.0, 27.0, 5.0, 100.0, 23.0, 51.0, 200.0, 41.0, 45.0, 68.0, 12.0, 31.0]|
|3 |[34.0, 38.0, 8.0, 7.0, 1.0, 5.0, 2.0, 6.0, 8.0, 9.0, 1.0, 2.0] |
|4 |[56.0, 49.0, 18.0, 17.0, 0.0, 13.0, 64.0, 18.0, 600.0, 12.0, 21.0, 78.0] |
+-----------+----------------------------------------------------------+In this case, we want to apply 10% discount to customers in the months in which they have spent 100 EUR or more. Let’s see how we can do it, first with a UDF:
from pyspark.sql.functions import udf, col
@udf("array<double>")
def apply_discounts(elements):
return list(map(lambda x: x - (x * 0.10) if x >= 100 else x, elements))
df.withColumn('monthly_spend', apply_discounts(col('monthly_spend'))) \
.show(truncate=False)
...
+-----------+----------------------------------------------------------+
|customer_id|monthly_spend |
+-----------+----------------------------------------------------------+
|1 |[18.0, 19.0, 17.0, 19.0, 23.0, 12.0, 54.0, 14.0, 16.0, 19.0, 12.0, 9.0] |
|2 |[25.0, 27.0, 5.0, 90.0, 23.0, 51.0, 180.0, 41.0, 45.0, 68.0, 12.0, 31.0]|
|3 |[34.0, 38.0, 8.0, 7.0, 1.0, 5.0, 2.0, 6.0, 8.0, 9.0, 1.0, 2.0] |
|4 |[56.0, 49.0, 18.0, 17.0, 0.0, 13.0, 64.0, 18.0, 540.0, 12.0, 21.0, 78.0]|
+-----------+----------------------------------------------------------+How can we avoid the use of UDF?
In this case, how can we avoid the use of UDF? The answer is by using the native transform function. This function has also not been available in the pyspark.sql.functions package until version 3.1, so let’s also look at both examples.
# Spark 2.x/3.0
from pyspark.sql.functions import col, lit, expr
df.withColumn(
'monthly_spend',
expr('transform(monthly_spend, x -> CASE WHEN x >= 100 THEN x - (x * 0.10) ELSE x END)')) \
.show(truncate=False)
# Spark 3.1
from pyspark.sql.functions import col, lit, expr, transform, when
df.withColumn(
'monthly_spend',
transform(col('monthly_spend'),
lambda x: when(x >= lit(100), x - (x * lit(0.10))).otherwise(x))) \
.show(truncate=False)
...
+-----------+----------------------------------------------------------+
|customer_id|monthly_spend |
+-----------+----------------------------------------------------------+
|1 |[18.0, 19.0, 17.0, 19.0, 23.0, 12.0, 54.0, 14.0, 16.0, 19.0, 12.0, 9.0] |
|2 |[25.0, 27.0, 5.0, 90.0, 23.0, 51.0, 180.0, 41.0, 45.0, 68.0, 12.0, 31.0]|
|3 |[34.0, 38.0, 8.0, 7.0, 1.0, 5.0, 2.0, 6.0, 8.0, 9.0, 1.0, 2.0] |
|4 |[56.0, 49.0, 18.0, 17.0, 0.0, 13.0, 64.0, 18.0, 540.0, 12.0, 21.0, 78.0]|
+-----------+----------------------------------------------------------+
Conclusion
In the Apache Spark 3.1.0 release, many new SQL functions have been exposed and it may be a good time to review your code if you are upgrading to this new release.
On the other hand, we could create an infinite list of cases where we could replace UDFs with native functions, but with these two examples we can quite well illustrate the strategy we have followed to solve these problems.
Before implementing a UDF, ask yourself these questions:
- Is there a Pyspark function, or combination of functions, that will solve my problem?
- Is there a SQL function for this purpose?
There most likely is, you just need to find them. Remember that if you do not find a function in the Pyspark library, but you know that the function exists in SQL, there is probably a way to call it using pyspark.sql.functions.expr as we have seen in the previous examples.
If you found this post useful, we encourage you to see more similar articles from the Data Engineering category in our blog and to share it with your contacts. See you in networks!
