
At Damavis we are very aware of the importance for our clients to have access to their data in real time. For this reason, one of our strengths is the development of tools and technologies that can move, transform and visualise data in a matter of seconds.
One of the technologies we use for such cases and of which we are experts is Akka; a framework that runs on top of Scala and offers an actor-based concurrency model. However, Akka will not be as useful as we would like for real-time applications if we do not have an integrated tool that is able to send data together with another tool that can consume and produce it. For this we use Kafka and the Alpakka Kafka library (Alpakka Kafka Documentation), built on top of Akka Streams (Akka Documentation).
In this article we explain how we have implemented an Akka Stream that consumes and produces Kafka messages through Alpakka, without going into technical issues such as Backpressure (Back-pressure Explained), Polling or the inner workings of Alpakka.
Code architecture
A clean architecture generates a strict dependency rule, which means that the visibility of the different abstraction layers is robustly defined along with the dependency hierarchy.
For this article, we leave the use cases in an Akka Stream and focus on the use of Alpakka and the connection to Kafka by differentiating between two abstraction layers:
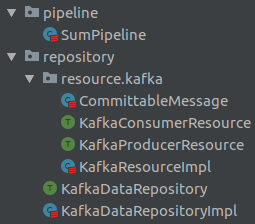
- Resource: this layer contains the connection to external resources such as databases or HTTP calls. In this case, it will be the connection to Kafka to consume and produce messages.
- Repository: is the layer that accesses the resources to, for example, obtain a record and transform it, without having any kind of business logic. They act as intermediaries between the use cases and the resources.
These abstractions allow us to create tests without the need to access external services. This is done through mocks which, in this case, will be used in Kafka’s resources.
Akka Stream
We have created a simple application that, given an input message in JSON with multiple integers, adds them together and sends a new message with the final result.
The input messages will have the following format:
{ "values": [0,2,4,6,8,10] }and the output ones:
{ “result”: 30 }The implemented Akka Stream is as follows:
Notice that the stream is composed of a Source, which is in charge of receiving messages from a Kafka topic and parse them to the case class Sum. Then, a Map is performed, which adds up all the values of the message to keep the result in the case class SumResult. Finally, we will broadcast the result in Kafka.
You can see that the stream has a variable called commitableMessage.
Commitable Message
What is a Committable Message? For simplicity, let’s consider that each application using Alpakka is a consumer of a Kafka topic. Furthermore, let’s assume that the parallelism of our application is to process a single record at a time.
Each time a message is consumed, a commit must be done in order to consume the next message. However, we only want to commit when we know that the log has been processed correctly at least once (https://doc.akka.io/docs/alpakka-kafka/current/atleastonce.html).
For this reason, we will commit when a new message is produced in Kafka or when a Passthrough is performed, i.e. when we don’t want to issue a new message but we want to commit.
To be able to manage this in an agile way, we have created a case class called CommitableMessage:
case class CommitableMessage[T](msg: T, offset: CommittableOffset)Basically, inside the commitableMessage is the message we are processing and the offset to commit to.
So far, so simple, right?
Consuming Kafka’s messages with Alpakka
To consume from a Kafka topic we use an Akka Stream Source that, thanks to Backpressure, knows when to read a message and send it downstream through the Akka Stream. Although there are several types of Sources for consuming messages, in this case we use a Consumer.committableSource to commit the offset and keep control of when we want to do it.
To do this, we create a trait called KafkaConsumerResource that has the function getSource, which returns a Source:
It is implemented in the KafkaResourceImpl class:
Find an example of the configuration to be passed to the previous class in the following link: https://github.com/akka/alpakka-kafka/blob/master/core/src/main/resources/reference.conf
The above resource is only responsible for connecting to Kafka, internally Polling, and emitting a downstream message. Once a message has been read, we want to parse the JSON. This is done in a repository called KafkaDataRepositoryImpl with the following functions:
As we can see, we go from a ConsumerMessage.CommittableMessage of String to our own CommittableMessage of type T, which in our case is the case class Sum.
Producing Kafka messages with Alpakka
There are three ways to produce messages with Alpakka:
- Broadcasting a single message: ProducerMessage.single()
- Broadcasting multiple messages: ProducerMessage.multi()
- Letting a record pass through without emitting any message: ProducerMessage.passThrough
In this example we are going to see how to send a single message if an instance of the case class SumResult arrives or how to let no message be produced at all. Both ways commit to the offset of the consumed message.
We create a new trait of a resource called KafkaProducerResource with the function getProducerFlow, which returns a Flow of ProducerMessage.Results when passed a ProducerMessage.Envelope:
Its implementation is added in the previous KafkaResourceImpl class:
Once the resource is created, let’s move on to the repository. In the previous repository KafkaDataRepositoryImpl we implemented the following functions:
The ProducerMessage.single function is in charge of generating the ProducerMessage.Envelope that is passed to the resource. As you can see, if we get an instance of the SumResult case class, a single message is generated and, otherwise, a pass-through is made.
Now that we have all the functions of the KafkaDataRepositoryImpl repository implemented, it is worth saying that this extends a trait called KafkaDataRepository and it looks like this:
Finally, both the resources and the repository explained look as follows:
Once the implementation is done, testing this Akka Stream becomes easier, like for example allowing to perform mocks on the Kafka connections. But this part will be covered in a future article.
References
LightBend Blog – https://www.lightbend.com/blog/alpakka-kafka-flow-control-optimizations
If you found this post useful, visit the Data Engineering category of our blog to see similar articles and share it with your contacts so they can also read it and give their opinion. See you in networks!
