
Note: the code of this post has been tested using Apache Hadoop 2.10.1. Please check out our previous post, Introduction to Apache Hadoop, to configure this version of Hadoop, in case you have not done it yet.
As explained in our previous post, Introduction to Apache Hadoop, Hadoop consists of different components amongst which we want to highlight HDFS, MapReduce and YARN. Simplifying and recalling from the post, HDFS is a distributed file system, MapReduce is a distributed computing engine and YARN is the manager that determines how MapReduce jobs are executed across the cluster.
In our post about Introduction to Apache Hadoop, we set up a HDFS, but no parallel jobs were able to be executed because Apache YARN was not configured, which means that no MapReduce could take place. So let’s do it in this post!
How to create users in YARN
When configuring software services it is good practice to set up users with limited permissions in order to follow proper system administrator practices. Before setting up a user you must choose a location where to place your software distribution in order to give permissions to the corresponding user to be able to operate within such location. You can choose the location which is most suitable to you. As explained in the previous post Introduction to Apache Hadoop, in our case, we have created a folder at the location /opt/hadoop and have created a user called hdoop, which is the owner of such location.
Configuration files
Another system administrator good practice is to copy the configuration files to be changed to a specified directory that can be linked to a Version Control System (VCS). Hence, software updates can be done without losing any configuration due to its independence from the new downloaded software distribution. In the previous post Introduction to Apache Hadoop, we showed how to follow this good practice. With the hdoop user, we created the directory /opt/hadoop/config-files, which is where the configuration files will be moved.
Basic YARN configuration
The first step to take when Apache YARN wants to be used is to let Hadoop know that. MapReduce jobs can be executed using different frameworks. Two of these frameworks are local and yarn. When the former is used, no cluster manager organizes how a job has to be parallelized, hence no parallelism occurs. The latter requires Apache YARN to be running, which will allow for parallel executions.
To change the local framework (which is the default Hadoop configuration) to execute MapReduce jobs using the yarn framework, we have to change the configuration file /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml. As explained in the previous section, whenever a configuration file has to be changed, it is good practice to detach it from the software distribution in order to be able to link it to a VCS. So let’s move this configuration file to /opt/hadoop/config-file and create a symbolic link
mv hadoop/etc/hadoop/yarn-site.xml config-files/
ln -s ~/config-files/yarn-site.xml ~/hadoop/etc/hadoop/yarn-site.xmlThen add the following property to this configuration file:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>The next step is to change the configuration file /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml. Note that if the configuration file mapred-site.xml only exists with the suffix .template, you must create a copy of such file without this suffix. As before, first let’s move this file to out VCS directory
mv hadoop/etc/hadoop/mapred-site.xml.template config-files/mapred-site.xml
ln -s ~/config-files/mapred-site.xml ~/hadoop/etc/hadoop/mapred-site.xmlThen add the following property:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>Believe it or not, if only the most basic configuration is wanted, this is all we need to do before launching YARN.
Running YARN
So let’s launch it. To run YARN, execute the following command:
/opt/hadoop/hadoop/sbin/start-yarn.shYou can access the Hadoop UI, where all MapReduce jobs, managed by YARN, can be seen. To see the UI access the URL http://localhost:8088/cluster:
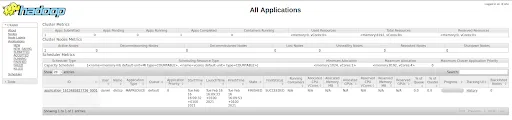
As you can see at the bottom of the image, there is a note that says “No data available in table”. This is because we have not run any job yet. Every time we send a MapReduce job we will see that a row of such execution, also called Application, is created.
Let’s see YARN in action with an example.
Practical example of Apache YARN
To see Apache YARN in action, we will do a straightforward example. We are going to create a text file of 1GB in our local machine, copy it into HDFS and then copy the file already in HDFS into another folder inside HDFS.
Create a text file
Let’s first create such a text file with the following command:
dd if=/dev/zero of=filename.big bs=1 count=1 seek=1073741823Check in your current location if a file named filename.big has been properly created.
The next step is to copy this file to your HDFS. In our case we built a demo HDFS at localhost. You can do the same as us or use any other HDFS distribution such as S3 from AWS or Azure Data Lake Gen 2 among others. If you want to go for our approach, please refer to our previous article about Introduction to Apache Hadoop where a local HDFS is launched.
To make sure that our HDFS is running, let’s access the URL http://localhost:50070. The following UI must be displayed:
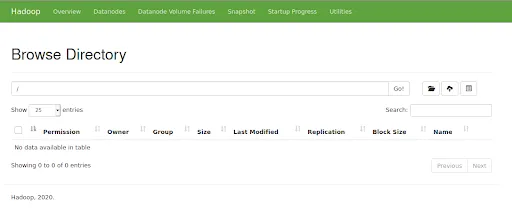
Copy the file to HDFS
Let’s now copy the text file created locally into HDFS with the following command:
hdfs dfs -copyFromLocal filename.big hdfs:///Note that it is assumed that the path of the binaries of Hadoop are appended to the PATH environment variable. The executed command did not run a MapReduce job, so no parallelism took place.
Given that we already have data in HDFS, from now on we will only work with data in this distributed file system. Let’s copy the file that already exists in HDFS into a folder called copied. But first we have to create such directory:
hdfs dfs -mkdir hdfs:///copiedAt this point, the root of your HDFS must look as follows:
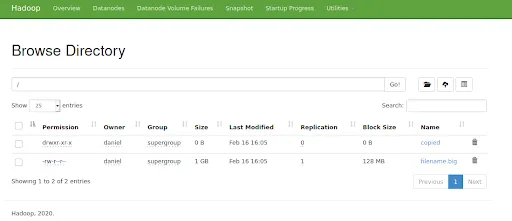
Note that the file filename.big and the folder copied have been created.
Now, let’s copy the file filename.big to the directory copied. There are two ways of doing this:
- One way is to execute the copy without MapReduce and, hence, without YARN. Execute the following command to copy in this way:
hdfs dfs -cp hdfs:///filename.big hdfs:///copied/
If you check the Hadoop UI, you will see that no application has been submitted. This is because no MapReduce job has been executed, so no parallelism takes place.
- The other way of copying this text file is to run a MapReduce job, where the task is run in parallel and managed by Apache YARN. To achieve this, execute the following command:
hadoop distcp hdfs:///filename.big hdfs:///copied/
Verifying the result
Either way, the file is copied into the folder copied. Therefore, if we list the items inside this folder, we will see the following output:

The difference of the second approach with respect to the first one is that a MapReduce task has been managed by YARN. To make sure this is true, access again the Hadoop UI:
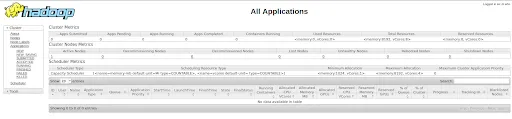
Note that, where earlier we had the message “No data available in table”, now we have a submitted application with final status SUCCEEDED.
Great! We are done with the introduction to Apache YARN. There is much more to know about this cluster manager. In this post we only scratched the surface of it. We intend to do more advanced posts where we will show how to fine tune this tool to increase parallelism, add more memory, and so on. Do not miss our updates!
If you found this post useful, share it with your contacts so that they can also read it and give their opinion. See you in networks!
