
2021 ha sido un año donde han ocurrido muchas cosas y muy rápido en Damavis. En este último post antes de la llegada de 2022, haremos un resumen de los contenidos publicados en nuestro blog a lo largo de todos estos meses.
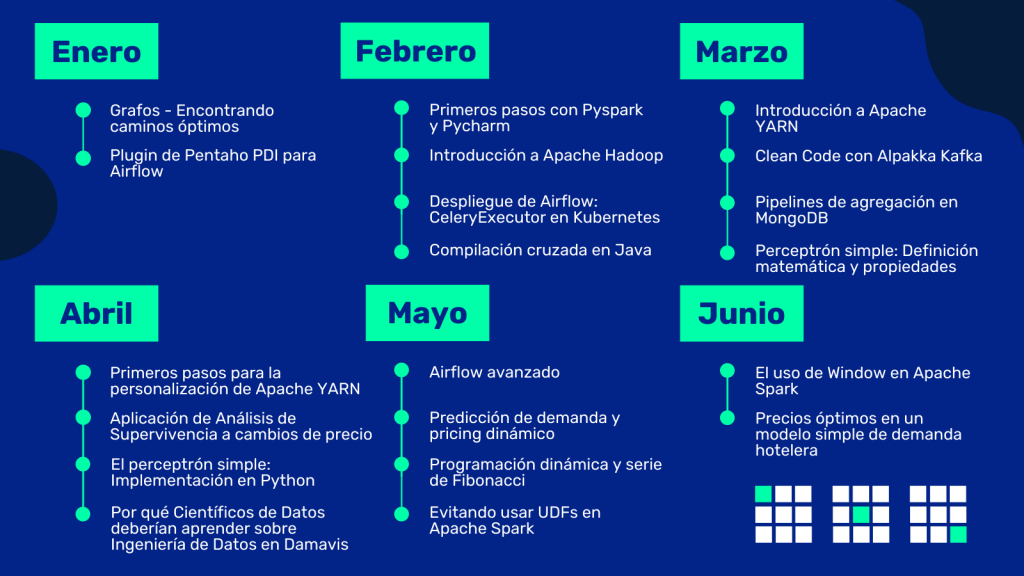
Los contenidos del Blog de Damavis en el primer semestre del año
En Enero vimos cómo podemos abordar proyectos de optimización de reglas de compra / venta, ahorro de combustible de flotas, distribución de mercancías o la optimización de espacios de almacén, mostrando para ello un simple ejemplo de optimización de rutas con grafos.
También publicamos con licencia libre nuestro Plugin de Pentaho PDI para Airflow, con el que muchas empresas pueden orquestar sus flujos de datos en batch desde Airflow.
En Febrero mostramos cómo realizar los primeros pasos con PySpark y PyCharm. Vimos una interesante introducción a Apache Hadoop y los pasos para configurarte un nodo local para hacer tus primeras pruebas. Realizamos un despliegue de CeleryExecutor en Kubernetes, sobre Airflow. Y tratamos con versiones antiguas de código, explicando cómo realizar una Compilación cruzada en Java.
En Marzo nos pusimos manos a la obra con una introducción a Apache Yarn, aprovechando el conocimiento ya explicado en el mes anterior. Repasamos las buenas prácticas del Clean Code con Alpakka Kafka con un ejemplo de Akka Stream. También tocamos la temática de bases de datos, explicando los Pipelines de Agregación en MongoDB. Y profundizamos en el mundo de las redes neuronales con la definición matemática de un perceptrón simple.
Al llegar el mes de Abril tratamos los primeros pasos de la personalización de Apache Yarn. Entramos en el mundo del Análisis de Supervivencia a cambios de precios y cómo este proceso puede aportar mucho valor en sistemas de caché. Pusimos sobre la mesa por qué consideramos que un Científico de Datos debería aprender sobre Ingeniería de Datos. Y con lo aprendido durante el mes anterior, realizamos una implementación en Python de un Perceptrón Simple.
Durante Mayo realizamos un ejercicio de Airflow Avanzado, tratando dependencias entre tareas y sensores Cross-Dag. Nos adentramos en el apasionante mundo de la Predicción de demanda y Pricing dinámico. Repasamos un ejemplo de Programación Dinámica trabajando con la serie de Fibonacci. Y vimos cómo y cuándo evitar usar UDFs en Apache Spark.
Junio nos permitió hablar del uso de Window en Apache Spark, viendo las funciones tanto analíticas como de agregación que podemos utilizar con esta interesante práctica. Y publicamos la definición del problema de un sistema de precios óptimos sobre un modelo simple de demanda hotelera.
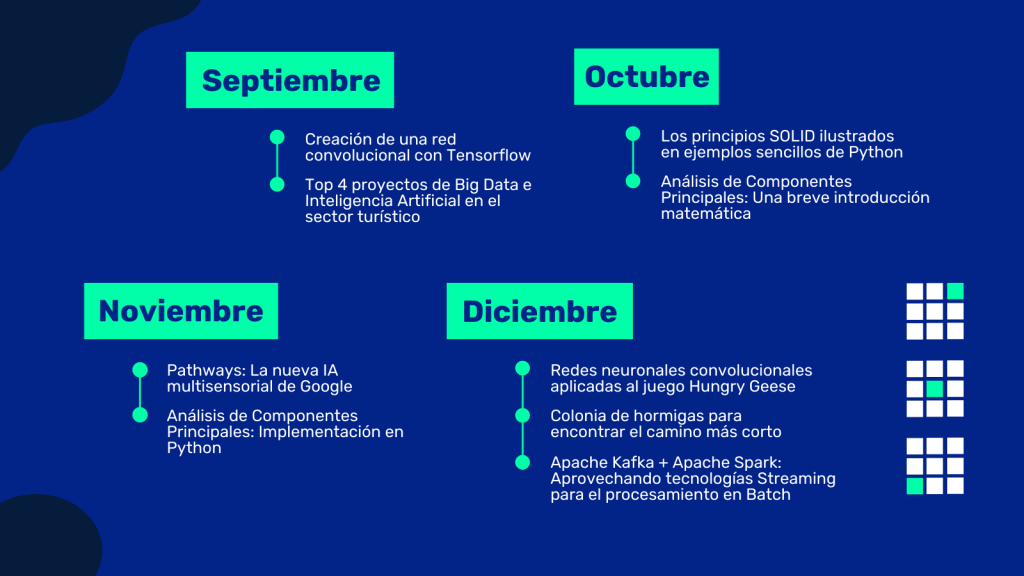
Segunda mitad de 2021 en nuestro Blog
En Julio y Agosto nos tomamos unas merecidas vacaciones en las publicaciones técnicas del blog, pero volvimos a la carga en Septiembre con la creación de una red convolucional con TensorFlow y hablamos sobre los Top 4 proyectos de Big Data e Inteligencia Artificial en el sector turístico.
Durante Octubre abordamos los temas como los principios SOLID con sencillos ejemplos en Python y una introducción matemática a los PCA (análisis de componentes principales).
Ya en la carrera hacia el final de año durante Noviembre, vimos Pathways, la nueva IA multisensorial de Google, y cómo estos avances pueden aportar mucho valor a los nuevos proyectos de Inteligencia Artificial que realicemos. Y profundizamos en el mundo de las PCA con una implementación en Python.
Y para cerrar el año, en Diciembre hemos hablado de redes neuronales convolucionales, vimos cómo podemos utilizar la inteligencia colectiva para encontrar caminos cortos con un ejemplo de hormigas artificiales. Y hemos visto cómo utilizar Apache Kafka y Apache Spark con tecnologías Streaming para el procesamiento en Batch.
Es evidente que durante este 2021 el equipo de Damavis ha crecido tanto en número como en los conocimientos que adquirimos, así que utilizamos entre otras cosas este blog para compartir nuestra experiencia y aproximarla a todo aquel que quiera adentrarse en el mundo de Big Data y la Inteligencia Artificial.
