
En el mundo de la ingeniería de datos, es bien sabido que el uso de UDFs (User Defined Functions) en Apache Spark (sobretodo con la API Python) puede penalizar muchísimo el rendimiento de nuestros aplicativos. Por eso, en Damavis intentamos evitar su uso todo lo posible a favor de las funciones nativas o SQL.
En este articulo, vamos a analizar algunas de las funciones menos comunes de la librería de Apache Spark y cómo funcionan mediante ejemplos prácticos.
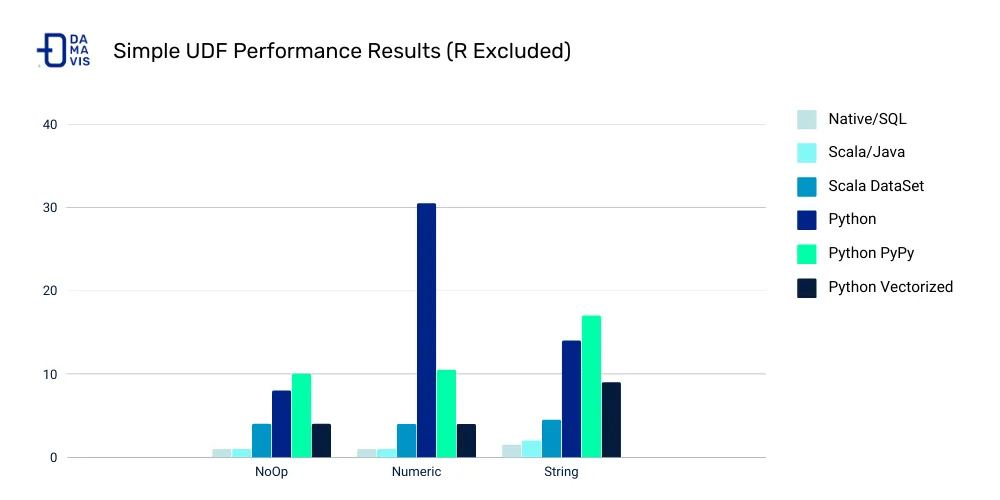
¿Por qué evitar el uso de UDFs en Spark?
Para ponernos en contexto y entender por qué evitamos usar UDFs, tenemos que conocer primero la arquitectura de Spark y cómo se integran la API python y Apache Spark. Para ello, nos centraremos en esta API porque es la más popular y donde más penaliza el uso de UDFs (excluyendo la API R).
El motor de Apache Spark está implementado en Java y Scala, lenguajes que se ejecutan sobre la JVM (Java Virtual Machine). El uso de la API python requiere una interacción entre esa JVM y el Python Runtime. Toda esa interacción es posible gracias a una librería llamada py4j, que nos permite llamar a código de la JVM. Al mismo tiempo, cada worker de Spark tendrá un Python Runtime ejecutándose para, por ejemplo, ejecutar UDFs.
Cuando ejecutamos una transformación de un DataFrame usando funciones nativas o de SQL, cada una de esas transformaciones ocurre dentro de la propia JVM, que es donde reside la implementación de la función. En cambio, si hacemos lo mismo usando UDFs de Python, lo que ocurre es muy distinto.
En primer lugar, ese código no puede ejecutarse en la JVM, sino en el Python Runtime. Para hacerlo posible, cada row del DataFrame es serializado, enviado al Python Runtime y devuelto a la JVM (representado como Pipe en la imagen). Como te puedes imaginar, este proceso no es nada óptimo.
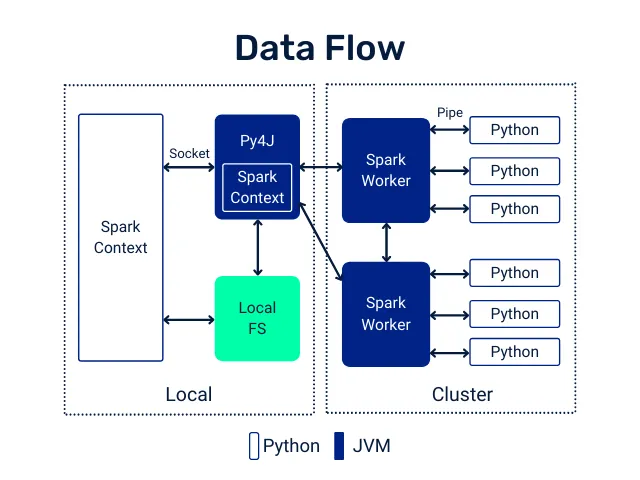
Es habitual la existencia de algunos proyectos que intentan optimizar este problema. Uno de ellos es Apache Arrow, que se basa en aplicar los UDFs con Pandas. Sin embargo, en este artículo lo que queremos hacer es intentar evitarlos siempre que sea posible. No obstante, y si quieres conocer más detalles, puedes visitar el post sobre Cómo optimizar UDFs en Python para Arrow en Spark.
Ejemplo de transformaciones en columnas de tipo Array
A continuación, veremos dos ejemplos muy concretos sobre transformaciones en columnas de tipo Array que nos han podido causar algún problema de rendimiento y que hemos solucionado reemplazando esas UDFs.
Filtrado de arrays
A veces, nos encontramos con columnas de tipo Array[T] y queremos aplicar un filtro. Supongamos que tenemos el siguiente DataFrame:
+-------+--------------+
|room_id| guests_ages|
+-------+--------------+
| 1| [18, 19, 17]|
| 2| [25, 27, 5]|
| 3|[34, 38, 8, 7]|
+-------+--------------+Vamos a imaginar que nuestro objetivo es añadir una columna con las edades de los adultos en cada habitación. Una de las opciones obvias es usar un UDF, veamos el ejemplo:
from pyspark.sql.functions import udf, col
@udf("array<integer>")
def filter_adults(elements):
return list(filter(lambda x: x >= 18, elements))
...
+-------+----------------+------------+
|room_id| guests_ages | adults_ages|
+-------+----------------+------------+
| 1 | [18, 19, 17] | [18, 19]|
| 2 | [25, 27, 5] | [25, 27]|
| 3 | [34, 38, 8, 7] | [34, 38]|
| 4 |[56, 49, 18, 17]|[56, 49, 18]|
+-------+----------------+------------+Para evitar el uso de este UDF, vamos a necesitar llamar a una función nativa llamada filter. Esta función no ha estado disponible en el paquete pyspark.sql.functions hasta la versión 3.1, así que vamos a ver ejemplos de cómo hacerlo en Spark 2.x y en Spark 3.1.
# Spark 2.x/3.0
from pyspark.sql.functions import col, expr, lit
df.withColumn('adults_ages',
expr('filter(guests_ages, x -> x >= 18)')).show()
# Spark 3.1
from pyspark.sql.functions import col, filter, lit
df.withColumn('adults_ages',
filter(col('guests_ages'), lambda x: x >= lit(18))).show()
...
+-------+----------------+------------+
|room_id| guests_ages| adults_ages|
+-------+----------------+------------+
| 1| [18, 19, 17]| [18, 19]|
| 2| [25, 27, 5]| [25, 27]|
| 3| [34, 38, 8, 7]| [34, 38]|
| 4|[56, 49, 18, 17]|[56, 49, 18]|
+-------+----------------+------------+Transformación de arrays
Hay ocasiones en las que puede que tengamos la necesidad de transformar elementos dentro de un array y, además, de forma condicional. Supongamos que tenemos el siguiente DataFrame:
+-----------+----------------------------------------------------------+
|customer_id|monthly_spend |
+-----------+----------------------------------------------------------+
|1 |[18.0, 19.0, 17.0, 19.0, 23.0, 12.0, 54.0, 14.0, 16.0, 19.0, 12.0, 9.0] |
|2 |[25.0, 27.0, 5.0, 100.0, 23.0, 51.0, 200.0, 41.0, 45.0, 68.0, 12.0, 31.0]|
|3 |[34.0, 38.0, 8.0, 7.0, 1.0, 5.0, 2.0, 6.0, 8.0, 9.0, 1.0, 2.0] |
|4 |[56.0, 49.0, 18.0, 17.0, 0.0, 13.0, 64.0, 18.0, 600.0, 12.0, 21.0, 78.0] |
+-----------+----------------------------------------------------------+En este caso, lo que queremos hacer es aplicar un descuento de un 10% a nuestros clientes en los meses en que han gastado igual o más de 100 EUR. Veamos cómo podemos hacerlo, primero con un UDF:
from pyspark.sql.functions import udf, col
@udf("array<double>")
def apply_discounts(elements):
return list(map(lambda x: x - (x * 0.10) if x >= 100 else x, elements))
df.withColumn('monthly_spend', apply_discounts(col('monthly_spend'))) \
.show(truncate=False)
...
+-----------+----------------------------------------------------------+
|customer_id|monthly_spend |
+-----------+----------------------------------------------------------+
|1 |[18.0, 19.0, 17.0, 19.0, 23.0, 12.0, 54.0, 14.0, 16.0, 19.0, 12.0, 9.0] |
|2 |[25.0, 27.0, 5.0, 90.0, 23.0, 51.0, 180.0, 41.0, 45.0, 68.0, 12.0, 31.0]|
|3 |[34.0, 38.0, 8.0, 7.0, 1.0, 5.0, 2.0, 6.0, 8.0, 9.0, 1.0, 2.0] |
|4 |[56.0, 49.0, 18.0, 17.0, 0.0, 13.0, 64.0, 18.0, 540.0, 12.0, 21.0, 78.0]|
+-----------+----------------------------------------------------------+¿Cómo podemos evitar el UDF?
Para esta situación, ¿cómo podemos evitar el UDF? La respuesta es mediante el uso de la función nativa transform. Dicha función no ha estado disponible en el paquete pyspark.sql.functions hasta la versión 3.1, así que veamos ambos ejemplos también.
# Spark 2.x/3.0
from pyspark.sql.functions import col, lit, expr
df.withColumn(
'monthly_spend',
expr('transform(monthly_spend, x -> CASE WHEN x >= 100 THEN x - (x * 0.10) ELSE x END)')) \
.show(truncate=False)
# Spark 3.1
from pyspark.sql.functions import col, lit, expr, transform, when
df.withColumn(
'monthly_spend',
transform(col('monthly_spend'),
lambda x: when(x >= lit(100), x - (x * lit(0.10))).otherwise(x))) \
.show(truncate=False)
...
+-----------+----------------------------------------------------------+
|customer_id|monthly_spend |
+-----------+----------------------------------------------------------+
|1 |[18.0, 19.0, 17.0, 19.0, 23.0, 12.0, 54.0, 14.0, 16.0, 19.0, 12.0, 9.0] |
|2 |[25.0, 27.0, 5.0, 90.0, 23.0, 51.0, 180.0, 41.0, 45.0, 68.0, 12.0, 31.0]|
|3 |[34.0, 38.0, 8.0, 7.0, 1.0, 5.0, 2.0, 6.0, 8.0, 9.0, 1.0, 2.0] |
|4 |[56.0, 49.0, 18.0, 17.0, 0.0, 13.0, 64.0, 18.0, 540.0, 12.0, 21.0, 78.0]|
+-----------+----------------------------------------------------------+Conclusión
En la versión 3.1.0 de Apache Spark se han expuesto muchas nuevas funciones SQL y puede ser buen momento para revisar tu código si vas actualizar a esta nueva versión.
Por otro lado, podríamos crear una lista infinita de casos donde podríamos sustituir UDFs por funciones nativas, pero con estos dos ejemplos podemos ilustrar bastante bien la estrategia que hemos seguido para resolver estos problemas.
Antes de implementar un UDF, hazte estas preguntas:
- ¿Existe una función de Pyspark, o combinación de funciones que resuelva mi problemática?
- ¿Existe una función SQL para este proposito?
Seguramente existan, solo hace falta encontrarlas. Recuerda que si no encuentras una función en la librería de Pyspark, pero sabes que existe la función en SQL, es muy probable que exista la forma de llamarla mediante el uso de pyspark.sql.functions.expr tal y como hemos visto en los ejemplos anteriores.
Si te ha parecido útil este post, te animamos a ver más artículos similares de la categoría Data Engineering en nuestro blog y a compartirlo con tus contactos. ¡Nos vemos en redes!
