
Configuración básica de un nodo
Nota: el código de este post ha sido probado utilizando Apache Hadoop 2.10.1. Por favor, consulta nuestro post anterior, Introducción a Apache Hadoop, para configurar esta versión de Hadoop en caso de que no lo hayas hecho todavía. Por otro lado, este post asume que ya tienes una configuración básica de Apache YARN en funcionamiento, que puede ser consultada en nuestro post Introducción a Apache YARN.
Introducción a Apache YARN
Después de introducir Apache YARN en nuestro post Introducción a Apache YARN, comentamos que sólo habíamos visto una pequeña parte de lo que se puede hacer con este gestor de clústeres. Así que te debemos una explicación más detallada de esta herramienta. Resumiendo, vimos que YARN es el gestor que determina cómo se ejecutan los jobs de MapReduce en el cluster. En dicho post, sólo añadimos dos propiedades a los archivos de configuración para así hacer una configuración funcional sencilla.
El objetivo de este post es mostrar una configuración más avanzada que permitirá mejorar el rendimiento de YARN. Pero antes de entrar a cambiar varias propiedades necesitamos una comprensión más profunda de la arquitectura de esta herramienta.
Arquitectura de Apache YARN
Seamos sinceros… la primera vez que consultamos la documentación oficial de Apache Hadoop para profundizar en la arquitectura de Apache YARN no lo entendimos del todo. Tuvimos que investigar un poco más para acabar de entender la arquitectura. Personalmente, jugar con las propiedades que se pueden cambiar en los ficheros de configuración fue muy útil para conseguir una mejor asimilación de los diferentes componentes de YARN.
Intentaremos transmitirte el resultado de nuestro proceso de aprendizaje de una manera razonable:
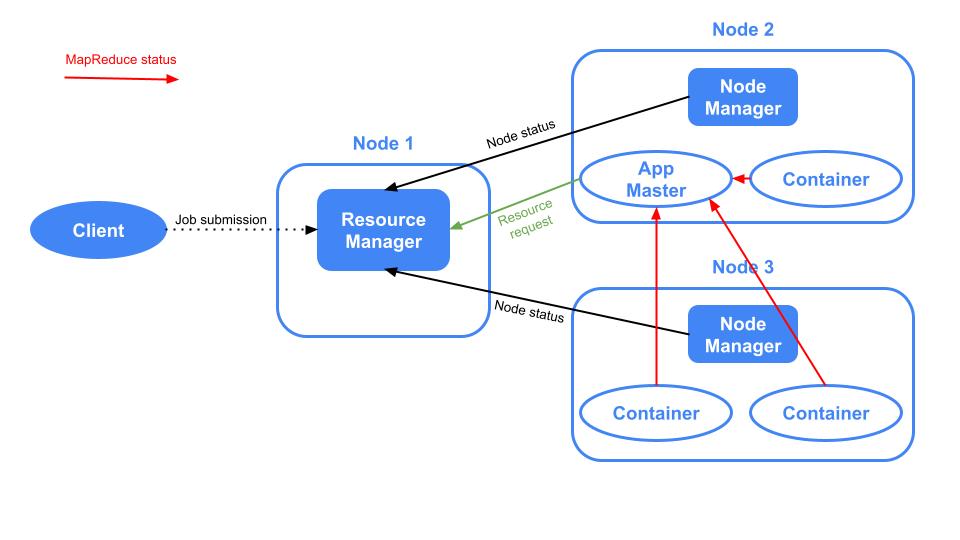
En Apache YARN hay varios componentes. Vamos a presentarlos en un orden que tenga sentido para que puedas relacionarlos a medida que avancemos:
- Resource Manager: sólo hay uno por clúster y se encarga de gestionar el uso de los recursos en todo el clúster.
- Node Manager: hay uno por nodo del cluster y se encarga de gestionar el uso de los recursos en el nodo. Existe una comunicación entre los Node Managers y el Resource Manager ya que este último tiene que saber constantemente cuáles son los recursos disponibles en los nodos.
- Application: es el job que se envía desde el Client al Resource Manager.
- Application Master: es lanzado por el Resource Manager en uno de los nodos y se encarga de orquestar la ejecución de la aplicación y comunicarse con el Resource Manager para hacerlo. Esta comunicación se produce de la siguiente manera:
- El Application Master solicita al Resource Manager los recursos para poder ejecutar la Aplicación.
- El Resource Manager lanza los Containers en los diferentes nodos solicitando estos recursos a los Node Managers.
- Una vez lanzados los Containers, el Application Master envía los jobs para ser ejecutados
- Finalmente, el Application Master comunica al Resource Manager el resultado de la ejecución de los jobs.
- Container: como se ha explicado anteriormente, es una pequeña porción de memoria y CPU creada dentro de un nodo por el Resource Manager. Es donde se ejecuta una parte de una Aplicación.
Aquí hay una imagen de Apache YARN donde se muestran los componentes descritos anteriormente:
Requisitos
Como explicamos en el post anterior Introducción a Apache YARN, en nuestro caso, hemos creado una carpeta en la ubicación /opt/hadoop donde se encuentra la distribución de hadoop y hemos creado un usuario llamado hdoop, que es el propietario de dicha ubicación. Con el usuario hdoop, hemos creado el directorio /opt/hadoop/config-files, que es donde se mueven los ficheros de configuración. Asumimos que has seguido el post anterior Introducción a Apache YARN. Por lo tanto, debes tener los archivos de configuración mapred-site.xml y yarn-site.xml en la carpeta /opt/hadoop/config-files, con una propiedad definida en cada archivo.
Personalización de la configuración
Ya estamos listos para entender las consecuencias de cambiar algunas de las propiedades de YARN que se pueden personalizar.
Hay muchas propiedades que se pueden cambiar y no hay manera de que podamos repasarlas todas en este post, así que hemos escogido algunas de ellas para presentarte las capacidades de personalización que tiene el end user al configurar YARN. Para tener acceso a todas las propiedades que se pueden personalizar, consulta la documentación oficial de Apache YARN (Official Apache YARN documentation)
Vamos a repasar algunas propiedades que se pueden cambiar en el archivo de configuración yarn-site.xml:
yarn.resourcemanager.hostname: Nombre del host del Resource Manager. Valor por defecto 0.0.0.0. En nuestra demostración el valor por defecto no se cambia. Ten en cuenta que dejar el valor por defecto implica que se puede acceder al servicio desde cualquier interfaz de red activa de la máquina. En entornos de producción, hay que estudiar si el valor por defecto puede ser un problema de seguridad.yarn.nodemanager.resource.detect-hardware-capabilities: booleano que especifica si el Node Manager debe habilitar la autodetección de memoria y CPU del nodo. Por defecto esfalso. En nuestra demo está establecido entrue.yarn.nodemanager.resource.pcores-vcores-multiplier: un número que se multiplica por el número físico de cores, que puede inferirse usando la propiedad anterioryarn.nodemanager.resource.detect-hardware-capabilities, para obtener los cores virtuales, también conocidos por vcores, que son las unidades de CPU que componen los Containers. Por defecto es 1.0. En nuestra demo está configurado a 3.0.yarn.nodemanager.resource.cpu-vcores: especifica el número de CPUs virtuales que un Node Manager puede utilizar para crear containers cuando el Resource Manager solicita la construcción de containers. Por defecto es -1. Cuando es -1 yyarn.nodemanager.resource.detect-hardware-capabilitiesestrue, el número de vcores se determina automáticamente a partir del hardware. En nuestra demo esta propiedad no se modifica.yarn.nodemanager.resource.system-reserved-memory-mb: memoria en MB que se reserva para el sistema (memoria no dedicada a YARN). Por defecto es -1, lo que implica que se calcula como el 20% de(system memory - 2*HADOOP_HEAPSIZE). En nuestra demo se establece en 2048.yarn.scheduler.minimum-allocation-mb: Asignación mínima en MBs para cada solicitud de container en el Resource Manager. Por defecto es de 1024 MB. En nuestra demostración se establece en 512.yarn.scheduler.maximum-allocation-mb: Asignación máxima en MBs para cada solicitud de container en el Resource Manager. Por defecto es de 8192 MB. En nuestra demostración se establece en 2048.yarn.scheduler.minimum-allocation-vcores: Número mínimo de cores virtuales que el Resource Manager asigna a cada solicitud de container realizada por el Application Master. Por defecto es 1. No se tiene en cuenta si se utiliza el scheduler que viene por defecto. Dado que el scheduler por defecto no se modifica, esta propiedad no se establece en nuestra demo.yarn.scheduler.maximum-allocation-vcores: Número máximo de cores virtuales que el Resource Manager asigna a cada solicitud de container hecha por el Application Master. Por defecto es 4. No se tiene en cuenta si se utiliza el scheduler por defecto. Dado que el scheduler por defecto no se modifica, esta propiedad no se establece en nuestra demo.
Las propiedades de YARN en acción
Nuestra máquina local, que es donde estamos lanzando Apache YARN tiene 6 CPUs físicas y 16 GBs de RAM. Las propiedades anteriores se han añadido al archivo de configuración yarn-site.xml. Vamos a iniciar Apache YARN ejecutando:
/opt/hadoop/hadoop/sbin/start-yarn.shEjecutaremos un job de MapReduce para ver Apache YARN en acción. Por ejemplo, crearemos un archivo en nuestra máquina local, lo copiaremos a nuestro HDFS y luego copiaremos el archivo desde el HDFS a otra ubicación de HDFS usando MapReduce (aquí asumimos que se está ejecutando una instancia local del HDFS):
dd if=/dev/zero of=filename.big bs=1 count=1 seek=1073741823
hdfs dfs -copyFromLocal filename.big hdfs:///
hdfs dfs -mkdir hdfs:///copied
hadoop distcp hdfs:///filename.big hdfs:///copied/Entra en el navegador http://localhost:8088/cluster para ver la interfaz de usuario:
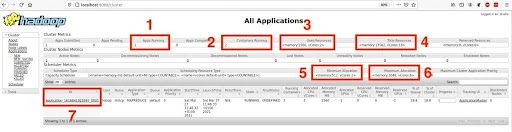
Queremos destacar siete atributos diferentes que se observan en la UI, lo que nos permitirán ver las consecuencias de haber cambiado algunas de las propiedades de YARN:
- Atributo 1: especifica el número de aplicaciones que se están ejecutando. El 1 que se observa corresponde a la ejecución de la copia del archivo de una ubicación de HDFS a otra ubicación de HDFS.
- Atributo 2: el número de containers que se están ejecutando es 2.
- Atributo 3: memoria y cores virtuales utilizados. Como puedes ver, se utilizan dos vcores, uno para cada container. Como se explica en la sección de propiedades, aunque hubiéramos cambiado las dos propiedades
yarn.scheduler.minimum-allocation-vcoresyyarn.scheduler.minimum-allocation-vcoresno se habrían tenido en cuenta porque estamos utilizando el scheduler por defecto. Por otro lado, se utilizan 2560 MB de RAM, que corresponden a 1024 MB asignados a un contenedor más 1536 MB asignados al otro contenedor (esto no se puede ver en la captura de pantalla pero se puede ver fácilmente pinchando en el enlace del cuadro 7 y luego en los ID de los contenedores), cuyos valores están dentro de los rangos especificados en las propiedadesyarn.scheduler.minimum-allocation-mbyyarn.scheduler.maximum-allocation-mb. - Atributo 4: memoria máxima y cores virtuales que pueden ser utilizados por YARN. Ten en cuenta que los cores virtuales son 18, que se corresponden con el número de cores físicos, que es 6, multiplicado por el valor de la propiedad
yarn.nodemanager.resource.pcores-vcores-multiplier(lo ponemos a 3). Recuerda que el número de CPUs físicos se ha calculado correctamente porque el valor de la propiedadyarn.nodemanager.resource.detect-hardware-capabilitiesse ha establecido entrue. - Atributo 5: muestra el valor que asignamos a las propiedades
yarn.scheduler.minimum-allocation-mbyyarn.scheduler.minimum-allocation-vcores. - Atributo 6: muestra los valores por defecto de las propiedades
yarn.scheduler.maximum-allocation-mbyyarn.scheduler.maximum-allocation-vcores. - Atributo 7: ID de la aplicación que se está ejecutando. Pulsando sobre él, se pueden observar más detalles sobre la ejecución.
Conclusión
Una vez más, hay mucho más que saber sobre Apache YARN, como la CLI y la configuración del scheduler. Esta ha sido una breve introducción sobre cómo empezar a personalizar este gestor de clusters. Si te ha resultado útil, ¡no olvides compartirlo con tus contactos!
¡Nos vemos en redes!
