
En este artículo, presentamos la guía definitiva para configurar el entorno de desarrollo de PySpark en PyCharm, una de las opciones más completas.
Apache Spark se ha convertido en la herramienta Big Data por excelencia, nos ayuda a procesar grandes volúmenes de datos de una manera simplificada, en cluster y tolerante a fallos.
A continuación, veremos cómo configurar el entorno de desarrollo de PySpark en PyCharm, que dentro de las diferentes opciones que podemos encontrar en el mercado como IDE de desarrollo, la versión community de PyCharm es de las opciones más completas.
El entorno sobre el que realizaremos la instalación será una máquina Ubuntu con las siguientes dependencias instaladas:
- Python 3.8 (mayor versión actualmente mantenida)
- Java 11
- PyCharm Community
Lo primero que debemos hacer es descargar la versión compilada de Spark. Actualmente, la última versión de Spark es la 3.0.1. Por otra parte, es aconsejable descargar el empaquetado que no contiene las dependencias de Hadoop. De esta forma, podremos desacoplar la versión de Hadoop y la de Spark y combinarlas siempre y cuando sean compatibles.
Instalación de Hadoop y Spark
- Descargamos el empaquetado de Spark y lo descomprimimos en
/opt.
cd ~/
curl -O http://apache.mirror.anlx.net/spark/spark-3.0.1/spark-3.0.1-bin-without-hadoop.tgztar -xvzf spark-3.0.1-bin-without-hadoop.tgzsudo mv spark-3.0.1-bin-without-hadoop /opt2. Ahora, hay que crear un enlace simbólico a la carpeta descomprimida. Este enlace nos permitirá cambiar de versión de Spark manteniendo las variables de entorno.
sudo ln -s spark-3.0.1-bin-without-hadoop spark3. Una vez instalado Spark, debemos proceder con los mismos pasos para la descarga de Hadoop.
cd ~/
curl -O http://apache.mirror.anlx.net/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gztar -xvzf hadoop-3.2.1.tar.gzsudo mv hadoop-3.2.1 /opt sudo ln -s hadoop-3.2.1 hadoop4. Una vez que disponemos de Spark y Hadoop vinculados a nuestras enlaces simbólicos (spark y hadoop respectivamente dentro de /opt), deberemos vincular las variables de entorno necesarias. Esto se hace para que el contexto de nuestras sesiones de terminal reconozcan las dos nuevas herramientas.
Para ello, debemos de añadir la exportación de las siguientes variables de entorno a nuestro bashrc, zshrc o similar que utilicemos como archivo inicializador de sesiones de terminal.
#HADOOP
export HADOOP_HOME=/opt/hadoop
export HADOOP_CLASSPATH=$HADOOP_HOME/share/hadoop/tools/lib/*
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
#SPARK
export SPARK_HOME=/opt/spark
export PATH=$SPARK_HOME/bin:$PATH
export SPARK_DIST_CLASSPATH=$(hadoop --config $HADOOP_CONF_DIR classpath)
export SPARK_DIST_CLASSPATH=$SPARK_DIST_CLASSPATH:$SPARK_HOME/jars/** Nota: Recomendamos tener esta inicialización separada. En Damavis, solemos crear un archivo llamado ~/.spark_profile que se carga desde el archivo rc con la sentencia source ~/.spark_profile.
5. Ahora, al abrir una nueva sesión de terminal deberíamos poder lanzar los siguientes comandos:
hadoop versionspark-shellProyecto de ejemplo con PyCharm
Lo primero que debemos hacer es descargar con Git el siguiente proyecto de ejemplo:
git clone https://github.com/damavis/spark-architecture-demo.gitA continuación, importamos el proyecto descargado con PyCharm y lo abrimos. En este escenario, para ejecutar el proyecto, tenemos dos opciones:
- La primera e inmediata sería la de crear un entorno virtual con conda o virtualenv instalando las dependencias especificadas en el
setup.py. - Ejecutar el código con la configuración de Spark y Hadoop.
En caso de escoger ésta última:
- Añadimos las librerías de PySpark que hemos instalado en el directorio
/opt.
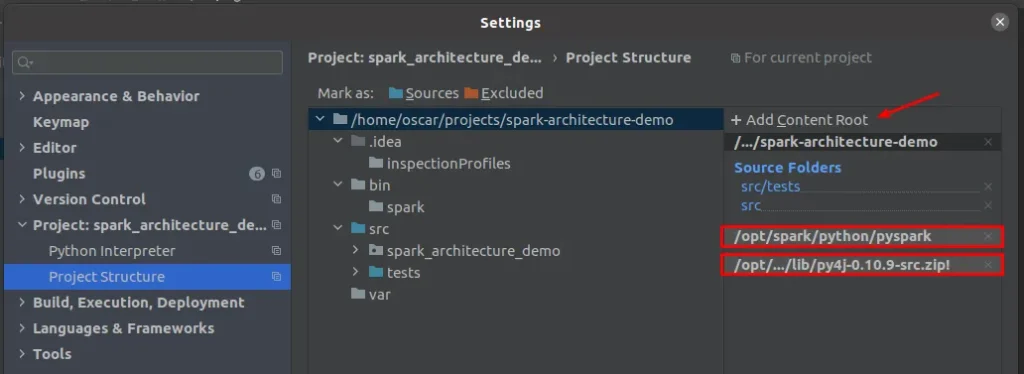
Para ello, debemos abrir settings e ir al apartado de Project Structure. Allí debemos añadir el contenido de los siguientes directorios:
/opt/spark/python/pyspark/opt/spark/python/lib/py4j-0.10.9-src.zip
2. En este momento, podremos ejecutar main que está dentro de src.
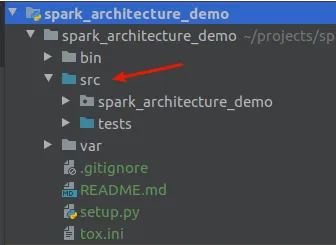
Es recomendable, para no tener que configurar el python_path, establecer la carpeta src como source. Para ello, hacemos clic derecho sobre la carpeta y la marcamos como fuente.
3. Por último, ejecutamos el archivo main.py y establecemos una variable de entorno para poder tanto lanzar como depurar el código PySpark.
PYSPARK_SUBMIT_ARGS=--master local[*] pyspark-shellSi al ejecutar la aplicación hay alguna dependencia de un empaquetado binario, se pueden establecer los argumentos como aparecen dentro de la documentación de Apache Spark. Por ejemplo:
PYSPARK_SUBMIT_ARGS=--master local[*] --packages
org.apache.spark:spark-avro_2.12:3.0.1 pyspark-shellConclusión
Con esta configuración podremos depurar nuestras aplicaciones de PySpark con PyCharm, para así corregir los posibles errores y aprovechar al máximo el potencial de la programación Python con PyCharm.
Si te ha parecido útil este post, pasa por nuestro blog y encuentra más artículos como este en la categoría Data Engineering. No olvides compartirlo con tus contactos para que ellos también puedan leerlo y opinar. ¡Nos vemos en redes!
