
En Damavis somos muy conscientes de la importancia que tiene para nuestros clientes el poder disponer de sus datos en tiempo real. Por este motivo, uno de nuestros puntos fuertes es el desarrollo con herramientas y tecnologías que puedan mover, transformar y visualizar datos en cuestión de segundos.
Una de las tecnologías que usamos para tales casos y de la cual somos expertos es Akka; un framework que funciona sobre Scala y ofrece un modelo de concurrencia basada en actores. No obstante, Akka no será todo lo útil que querríamos para las aplicaciones en tiempo real si no tenemos integrada una herramienta que sea capaz de enviar datos conjuntamente con otra que pueda consumirlos y producirlos. Para ello usamos Kafka y la librería Alpakka Kafka (Alpakka Kafka Documentation), construida sobre Akka Streams (Akka Documentation).
En este artículo explicamos cómo hemos implementado un Akka Stream que consume y produce mensajes de Kafka mediante Alpakka, sin entrar en temas técnicos como Backpressure (Back-pressure Explained), Polling o el funcionamiento interno de Alpakka.
Arquitectura del código
Una arquitectura clean genera una estricta regla de dependencia, lo que significa que la visibilidad de las diferentes capas de abstracción está definida de forma robusta junto a la jerarquía de dependencia.
Para este artículo, dejamos los casos de uso en un Akka Stream y nos centramos en el uso de Alpakka y la conexión con Kafka diferenciando dos capas de abstracción:
- Resource: esta capa contiene la conexión con los recursos externos como, por ejemplo, bases de datos o llamadas HTTP. En este caso, será la conexión con Kafka para consumir y producir mensajes.
- Repositorio: es la capa que accede a los resources para, por ejemplo, obtener un registro y transformarlo, sin tener ningún tipo de lógica de negocio. Actúan como intermediarios entre los casos de uso y los resources.
Estas abstracciones nos permiten crear tests sin la necesidad de acceder a servicios externos. Esto se hace mediante mocks que, en este caso, se usarán en los resources de Kafka.
Akka Stream
Hemos creado una sencilla aplicación que, dado un mensaje de entrada en JSON con múltiple integers, los suma y envía un nuevo mensaje con el resultado final.
Los mensajes de entrada tendrán el siguiente formato:
{ "values": [0,2,4,6,8,10] }y los de salida:
{ “result”: 30 }El Akka Stream implementado es el siguiente:
Vemos que el stream está compuesto por un Source, que es el encargado de recibir mensajes de un topic de Kafka y parsearlos a la case class Sum. A continuación, se realiza un Map, el cual suma todos los valores del mensaje para mantener el resultado en la case class SumResult. Por último, emitiremos el resultado en Kafka.
Vemos que el stream tiene una variable llama commitableMessage
Commitable Message
¿Qué es un Commitable Message? Para simplificarlo, vamos a considerar que cada aplicación que use Alpakka es un consumidor de un topic de Kafka. Además, vamos a suponer que el paralelismo de nuestra aplicación es el de procesar un único registro a la vez.
Cada vez que un mensaje es consumido, se debe hacer commit para poder consumir el siguiente mensaje. No obstante, solo queremos hacer commit cuando sabemos que el registro se ha procesado correctamente al menos una vez (https://doc.akka.io/docs/alpakka-kafka/current/atleastonce.html).
Por este motivo, se hará commit cuando se produzca un nuevo mensaje en Kafka o cuando se realice un Passthrough, es decir, cuando no se quiera emitir un nuevo mensaje pero se quiera hacer commit.
Hemos creado una case class llamada CommitableMessage para poder gestionar esto de una manera ágil:
case class CommitableMessage[T](msg: T, offset: CommittableOffset)Básicamente, dentro del commitableMessage está el mensaje que estamos procesando y el offset al que se hará commit.
Hasta ahora es sencillo, ¿verdad?
Consumiendo mensajes de Kafka con Alpakka
Para consumir de un topic de Kafka se utiliza un Source de Akka Stream que, gracias al Backpressure, sabe cuándo leer un mensaje y enviarlo “downstream” por el Akka Stream. Aunque existen varios tipos de Sources para consumir mensajes, en este caso utilizamos un Consumer.committableSource para hacer commit del offset y mantener el control del momento en el que queremos hacerlo.
Para ello, creamos un trait llamado KafkaConsumerResource que tiene la función getSource, la cual devuelve un Source:
Su implementación se hace en la clase KafkaResourceImpl:
Un ejemplo de la configuración que debemos pasar a la clase anterior la podemos encontrar en el siguiente enlace: https://github.com/akka/alpakka-kafka/blob/master/core/src/main/resources/reference.conf
El resource anterior únicamente se encarga de conectar con Kafka, internamente hacer Polling, y emitir un mensaje downstream. Una vez se haya leído un mensaje, queremos parsear el JSON. Esto se hace en un repositorio llamado KafkaDataRepositoryImpl con las siguientes funciones:
Como podemos ver, pasamos de un ConsumerMessage.CommittableMessage de String a nuestro propio CommittableMessage del tipo T, que en nuestro caso es la case class Sum.
Produciendo mensajes de Kafka con Alpakka
Existen tres formas de producir mensajes con Alpakka:
- Emitiendo un único mensaje: ProducerMessage.single()
- Emitiendo múltiples mensajes: ProducerMessage.multi()
- Dejar que un registro pase sin emitir ningún mensaje: ProducerMessage.passThrough
En este ejemplo vamos a ver cómo enviar un único mensaje si nos llega una instancia de la case class SumResult o cómo dejar que no se produzca ningún mensaje. Ambas formas hacen commit al offset del mensaje consumido.
Creamos un nuevo trait de un resource llamado KafkaProducerResource con la función getProducerFlow, que devuelve un Flow de ProducerMessage.Results al pasarle un ProducerMessage.Envelope:
Su implementación se añade en la anterior clase KafkaResourceImpl:
Una vez creado el resource, pasemos al repositorio. En el anterior repositorio KafkaDataRepositoryImpl implementamos las siguientes funciones:
La función ProducerMessage.single es la encargada de generar el ProducerMessage.Envelope que se pasa al resource. Como podéis ver, si nos llega una instancia de la case class SumResult se genera un single message y, en caso contrario, se hace un pass-through.
Ahora que ya tenemos todas las funciones del repositorio KafkaDataRepositoryImpl implementadas, cabe decir que este extiende de un trait llamado KafkaDataRepository y que es así:
Finalmente, tanto los resources como el repositorio explicados se ven de la siguiente forma:
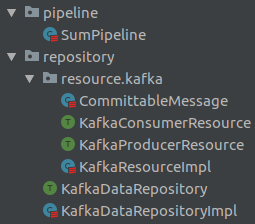
Una vez hecha la implementación, la realización de tests sobre este Akka Stream se hace más fácil permitiendo, por ejemplo, realizar mocks sobre las conexiones de Kafka. Pero esta parte la abordaremos en un próximo artículo.
Referencias
LightBend Blog – https://www.lightbend.com/blog/alpakka-kafka-flow-control-optimizations
Si te ha parecido útil este post, visita la categoría Data Engineering de nuestro blog para ver artículos similares y compártelo con tus contactos para que ellos también puedan leerlo y opinar. ¡Nos vemos en redes!
