
A veces puede resultar un poco agobiante entender el papel de las tecnologías open source más comunes utilizadas en contextos de Big Data.
Por ejemplo, probablemente la mayoría de vosotros ha oído hablar de herramientas como Apache Hadoop, Apache Spark, Apache Hive, Apache Sqoop, etc. Pero, ¿cómo saber cuándo utilizar una u otra? ¿Dependen entre sí?
Pues bien, en la mayoría de los casos, la respuesta es sí. A través de una serie de artículos escritos por Damavis sobre el Ecosistema Hadoop, intentaremos que todo quede más claro. No sólo aportando definiciones teóricas, sino poniéndonos manos a la obra configurando y ejecutando las herramientas explicadas.
Para introducirse en el mundo de Big Data tenemos que empezar desde abajo. ¿Cuál es la herramienta base? Por supuesto es Apache Hadoop.
¿Qué es Apache Hadoop?
Apache Hadoop es un framework open source utilizado para almacenar y procesar Big Data de forma distribuida y tolerante a fallos. Hay varios módulos que componen Apache Hadoop. Los que queremos destacar son:
- Hadoop Distributed File System, también conocido como HDFS. Es la forma en la que Hadoop almacena los datos de forma distribuida y con tolerancia a fallos. ¿Cómo se consigue la tolerancia a fallos? Sencillamente, mediante la replicación. Los datos se copian entre los distintos nodos, de modo que en caso de fallo de uno de ellos, sus datos pueden obtenerse a partir de su replicación en otros nodos. Ten en cuenta que este módulo trata sobre el almacenamiento de datos.
- Hadoop MapReduce, que es el módulo encargado de aplicar el modelo de programación MapReduce para procesar datos de forma distribuida. Por lo tanto, el objetivo de este módulo es realizar el procesamiento de datos.
- Apache Yarn, que es el componente encargado de gestionar los trabajos y recursos del cluster. Esta herramienta responde a preguntas como, ¿cómo debe distribuirse una tarea en el clúster? ¿Qué nodos deben participar en esta tarea? ¿Cómo debe redistribuirse el trabajo en caso de fallo de un nodo? Y otras acciones que veremos en posts dedicados sobre esta tecnología. Por lo tanto, el objetivo de este módulo es realizar la gestión del clúster.
Dado que en este post analizaremos la configuración en un único nodo, no profundizaremos en la configuración y uso de Apache Yarn. Esto se debe a que para lanzar un HDFS y realizar MapReduce jobs en una configuración de un solo nodo no es necesario configurar un gestor de cluster como Apache Yarn.
¡No te pierdas nuestro próximo post de esta serie, donde explicaremos cómo usar Hadoop con Yarn!
Configuración básica de Hadoop
Al configurar los servicios de software, una buena praxis es la de configurar usuarios con permisos limitados para seguir las prácticas propias del administrador del sistema. Por eso, lo primero que haremos será realizar este proceso.
Cómo configurar un usuario
Antes de configurar un usuario, debes elegir una ubicación donde colocar tu distribución de software para dar permisos al usuario correspondiente y poder operar dentro de dicha ubicación. Puedes elegir la que más te convenga. En nuestro caso, crearemos una carpeta en la ubicación /opt/hadoop y un usuario llamado hdoop, que será el propietario de dicha ubicación. Los pasos a realizar son:
- En primer lugar, cambia al usuario principal (root) →
sudo su - A continuación, crea el archivo
/opt/hadoop → mkdir /opt/hadoop - Crear el usuario sin contraseña
hdoopcuya home será/opt/hadoop→adduser --home /opt/hadoop --disabled-password hdoop - Haz que el usuario
hdoopsea el propietario de su archivo home →chown -R hdoop /opt/hadoop - Finalmente, cambia al usuario
hdoop→su hdoop - Ejecuta
cdpara ir a la home del usuariohdoop.
Archivos de configuración
Otra buena práctica de los administradores de sistemas es copiar los archivos de configuración que se van a cambiar en un directorio específico que puede estar vinculado a un sistema de control de versiones (VCS). De este modo, las actualizaciones de software pueden realizarse sin perder ninguna configuración debido a su independencia de la nueva distribución de software descargada. Para seguir esta buena praxis, con el usuario hdoop, crea el directorio /opt/hadoop/config-files, que es donde se moverán los archivos de configuración.
Pasos para la configuración
En primer lugar, vamos a descargar Hadoop, descomprimirlo y crear un enlace simbólico a un directorio donde no se especifique la versión (esto último es simplemente para facilitar la actualización de Hadoop en caso de que sea necesario en el futuro).
Para obtener Apache Hadoop, ejecuta los siguientes comandos:
wget https://ftp.cixug.es/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
tar -xf hadoop-2.10.1.tar.gz
rm hadoop-2.10.1.tar.gz
ln -s hadoop-2.10.1 hadoopPara poder utilizar Apache Hadoop necesitamos asegurarnos de que Java 8 está instalado en la máquina. Ejecuta java -version para comprobarlo. Si no es así, instala Java 8 ejecutando los siguientes comandos con el usuario principal (root):
apt update
apt install openjdk-8-jdk -yPara que Hadoop funcione, sólo hay que establecer una variable de entorno, que es JAVA_HOME. Esta asignación se puede hacer en el archivo /opt/hadoop/hadoop/etc/hadoop/hadoop-env.sh.
Como se ha explicado en la sección anterior, siempre que haya que cambiar un archivo de configuración, es buena práctica separarlo de la distribución de software para poder enlazarlo con un VCS. Así que vamos a mover este archivo de configuración a /opt/hadoop/config-file y crear un enlace simbólico:
mv hadoop/etc/hadoop/hadoop-env.sh config-files/
ln -s ~/config-files/hadoop-env.sh ~/hadoop/etc/hadoop/hadoop-env.shAhora puedes cambiar la variable de entorno JAVA_HOME. Su valor debe ser:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64Como estamos ejecutando Hadoop en un solo nodo, no hay necesidad de replicar los datos entre los nodos, que es el comportamiento por defecto. El archivo de configuración que hay que cambiar es /opt/hadoop/hadoop/etc/hadoop/hdfs-site.xml. Como antes, primero vamos a mover este archivo a nuestro directorio VCS:
mv hadoop/etc/hadoop/hdfs-site.xml config-files/
ln -s ~/config-files/hdfs-site.xml ~/hadoop/etc/hadoop/hdfs-site.xmlPara eliminar la replicación, añade la siguiente propiedad al archivo de configuración:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>Ubicación del HDFS
El siguiente paso es especificar la ubicación donde el HDFS debe ser construido. Como estamos ejecutando todo localmente, vamos a construir HDFS en localhost.
Para que esto ocurra, debemos cambiar el archivo de configuración /opt/hadoop/hadoop/etc/hadoop/core-site.xml. De nuevo, primero vamos a mover este archivo al directorio VCS y crear un enlace simbólico:
mv hadoop/etc/hadoop/core-site.xml config-files/
ln -s ~/config-files/core-site.xml ~/hadoop/etc/hadoop/core-site.xmlLa propiedad que hay que añadir es la siguiente:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>Por último, como al construir HDFS hay que hacer una conexión a localhost, necesitamos poder hacer ssh a localhost. Para ello, genera nuevos pares de claves de autenticación para ssh sin passphrase y copia tu clave ssh pública en el archivo que contiene las claves ssh autorizadas:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh localhostOtro paso que recomendamos es modificar la variable de entorno PATH para poder ejecutar los comandos de Hadoop desde cualquier ubicación. Para ello, añade el siguiente comando en tu .bashrc en el directorio de inicio:
export PATH=/opt/hadoop/hadoop/bin:$PATHRecuerda ejecutar source .bashrc para aplicar el cambio en la sesión actual.
¡Apache Hadoop ya está configurado!
Comprueba tu configuración
Para asegurarnos de que todo se ha hecho correctamente, vamos a lanzar HDFS y copiar un archivo en él. Para lanzar HDFS ejecuta primero hdfs namenode -format para lanzar el NameNode, que es un servidor maestro que mantiene el mapa de directorios de todos los archivos. A continuación, ejecuta el script ubicado en opt/hadoop/hadoop/sbin/start-dfs.sh. Seguidamente, introduce en tu navegador la URI http://localhost:50070 para poder ver la UI de Hadoop.
Ahora vamos a crear un archivo llamado tmp y copiarlo en nuestro HDFS:
touch tmp
hdfs dfs -copyFromLocal tmp hdfs://Tienes dos maneras de ver si el archivo tmp ha sido copiado a HDFS, ya sea enumerando los archivos desde la línea de comandos:
hdfs dfs -ls hdfs://
O utilizando la UI haciendo clic en Utilities/Browse the file system:
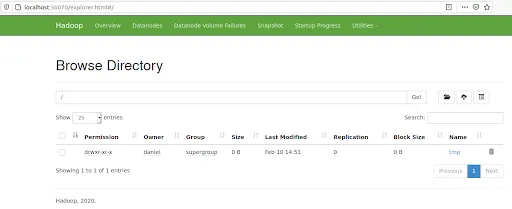
Próximos pasos
La segunda parte de este artículo, continúa en Introducción a Apache YARN donde se utiliza Apache Yarn en nuestro Ecosistema Hadoop, que es la forma correcta de utilizar Hadoop.
Si te ha parecido útil este post, compártelo con tus contactos para que ellos también puedan leerlo y opinar. ¡Nos vemos en redes!
