
El procesamiento en batch (o por lotes) es una metodología que se utiliza ampliamente en el mundo del Big Data. A lo largo de este post, analizaremos cómo se pueden aprovechar tecnologías con las que habitualmente se trabajan datos en streaming (tiempo real), como Apache Kafka y Apache Spark, para procesar datos en batch.
¿Qué es un proceso ETL/ELT?
Un proceso ETL/ELT es la pieza central de un proyecto Big Data. El conjunto de actividades fundamentales para llevarlo a cabo pasa por recopilar, ingestar, integrar, tratar, almacenar y analizar grandes volúmenes de información. La unión de estas tareas permite tener una base sólida para realizar proyectos y casos de uso concretos tanto de analítica descriptiva como predictiva.
Existen multitud de herramientas y tecnologías que trabajan de manera conjunta para llevar a cabo este proceso. No obstante, la elección de cada una de ellas va en función de las características concretas del problema. Dichas características determinan la viabilidad de un proyecto, tanto a nivel de presupuesto como de eficiencia de la solución.
En este post, nos centraremos en abordar el componente de procesamiento de la información. Esta parte cobra especial interés debido a la gran cantidad de datos que se generan diariamente, además de los distintos orígenes y formato de los mismos. La misión de este conjunto de tareas es la de homogeneizar y enriquecer los datos brutos para dar respuesta a preguntas que surgen en la unidad de negocio.
Con la gestión de grandes volúmenes de datos no existe una técnica predefinida para realizar el tratamiento. Sin embargo, existen diferentes paradigmas, que explicaremos detenidamente en futuros posts del blog, para llevar a cabo estos procesos. Cada uno de ellos con características concretas y un amplio stack tecnológico propio.
Diferencias entre procesamiento en batch y en streaming
El paradigma de procesamiento en batch (por lotes) se basa en la realización de las transformaciones de manera periódica sobre un subconjunto finito de información. Como ejemplo básico, podría ser la ingesta y transformación de un componente de negocio de forma diaria. Este paradigma es útil en situaciones donde existe un gran volumen de información. Además, cobra gran importancia el uso modelos de programación como el MapReduce y el procesamiento distribuido de la información.
Por otro lado, podemos encontrar el paradigma de procesamiento en Streaming. A diferencia del anterior, en este caso los datos son procesados en el momento en el que son ingestados de forma inmediata. Esto hace que el volumen de datos en procesamiento sea menor ya que se puede realizar tanto en “real-time” como en “micro-batches” (periodos de tiempo muy pequeños). El uso de este paradigma es útil en situaciones en las que se requiere que la información sea aprovechable para tomar decisiones en un corto periodo de tiempo. Por ejemplo, para la monitorización de logs o la detección de fraude.
Por último, podemos destacar el paradigma Lambda, atribuido a Nathan Marz en 2012. A partir de tres capas (Batch, Speed y Serving), proporciona una solución híbrida. Además, cada vez está siendo más utilizada en la industria debido a la flexibilidad que proporciona.
Cómo funciona el procesamiento en Apache Kafka
Entrando en las tecnologías del procesamiento en streaming aparece Apache Kafka como herramienta open-source de distribución de mensajes que permite publicar, almacenar registros, así como consumirlos en tiempo real.
El funcionamiento de Apache Kafka consiste en que las aplicaciones productoras (producers) publican eventos en diferentes flujos de datos llamados topics. Las aplicaciones consumidoras (consumers) pueden subscribirse a los diferentes topics para obtener y procesar los eventos. Cada topic está particionado, de forma que cuando se publica un evento, el registro queda almacenado en una de las particiones tal y como se muestra en la siguiente figura.
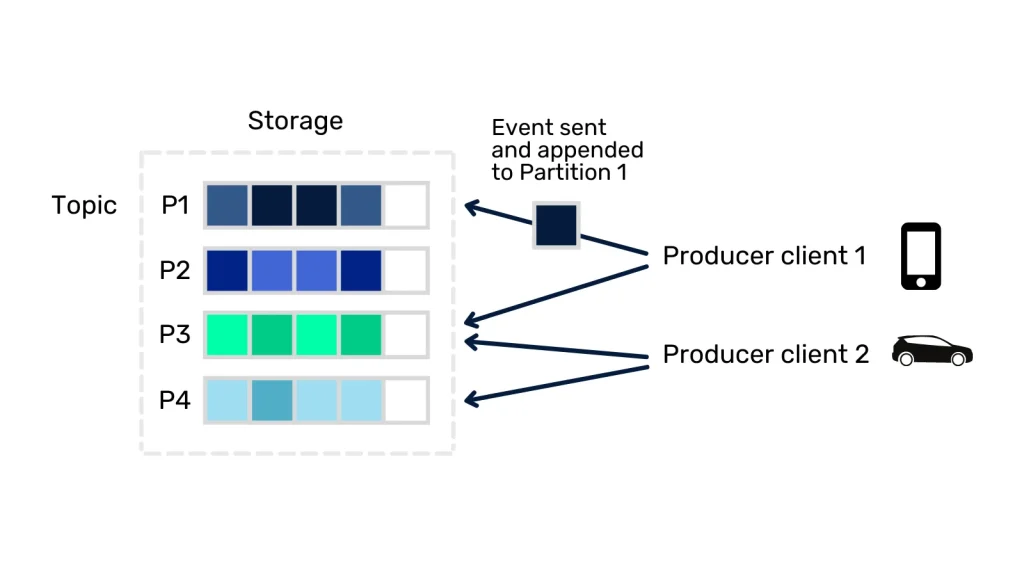
Uno de los grandes problemas a resolver por los sistemas de mensajería es la gestión de qué mensajes han sido consumidos. Kafka nos garantiza que cualquier consumidor siempre realizará la lectura de los eventos en el mismo orden en el que fueron escritos, esto se consigue a partir de los offsets. El offset no deja de ser un integer simple usado por Kafka para contener la posición del último registro que ha sido consumido. Esto nos permite evitar que el mismo evento sea enviado al mismo consumidor.
Ejemplo de arquitectura con Kafka y Spark
Podemos imaginar un escenario con arquitectura con Apache Kafka donde se transforman los datos crudos a partir de trabajos con Apache Spark.
En este caso, pueden darse situaciones que exijan que los datos crudos sean procesados de nuevo. Un ejemplo puede ser la detección de un bug en el trabajo de Spark por parte del equipo de desarrollo o la necesidad de implementar una transformación no planificada. Estos pueden ser motivos que provocan que sea necesario el reprocesamiento. En este contexto se debe obtener una solución que permita consumir los eventos a partir de un momento específico del tiempo.
Cómo solucionar el problema
La solución óptima dependerá de la versión de Apache Spark que se esté usando.
En versiones anteriores a Spark 3.0 se debe realizar una búsqueda del offset correspondiente al timestamp objetivo. Esto se puede realizar mediante la función offsets_for_times (timestamps) propia de la librería kafka-python. Devolviendo un diccionario con las particiones y el offset más cercano al timestamp correspondiente.
KafkaConsumer.offsets_for_times({TopicPartition: Int})
El resultado se puede introducir en el consumidor de Spark con la opción startingOffsets/endingOffsets.
def read(self, topic, start_offset, end_offset) -> DataFrame:
return self.spark.read.format("kafka") \
.option("kafka.bootstrap.servers", “bootstrap_server”) \
.option("subscribe", “topic_example”) \
.option("startingOffsets", start_offset) \
.option("endingOffsets", end_offset) \
.load()Como vemos, este proceso requiere de nuevo desarrollo programático para la obtención de los offsets correspondientes, añadiendo una complejidad no deseada al problema.
A partir de la versión Spark 3.0 aparece una solución build-in mediante el uso de parámetros específicos en la configuración de lectura. Esta solución permite delegar la responsabilidad de encontrar los offsets correspondientes a Spark, por lo que la necesidad de realizar código añadido desaparece, simplificando notablemente la solución.
Solución en Spark 3.0.0
def read(self, topic, start_offset, end_offset) -> DataFrame:
return self.spark.read.format("kafka") \
.option("kafka.bootstrap.servers", “bootstrap_server”) \
.option("subscribe", “topic_example”) \
.option("startingOffsetsByTimestamp", start_timestamp) \
.option("endingOffsetsByTimestamp", end_timestamp) \
.load()Siendo los parámetros startingOffsetsByTimestamp/endingOffsetsByTimestamp en formato json string """ {"topicA":{"0": 1000, "1": 1000}, "topicB": {"0": 2000, "1": 2000}} """
Solución en Spark 3.2.0
def read(self, topic, start_offset, end_offset) -> DataFrame:
return self.spark.read.format("kafka") \
.option("kafka.bootstrap.servers", “bootstrap_server”) \
.option("subscribe", “topic_example”) \
.option("startingTimestamp", start_timestamp) \
.option("endingTimestamp", end_timestamp) \
.load()Siendo los parámetros startingTimestamp/endingTimestamp en formato string representando un timestamp.
Conclusión
Como podemos ver, con versiones superiores de Apache Spark 3.0.0 podemos realizar el reprocesamiento de la información de forma eficaz a partir de un timestamp específico, dando mayor versatilidad a la herramienta y permitiendo de forma eficaz la consumición de la información en lotes. De esta forma, contamos con una solución que permite el procesado de los datos de manera periódica sobre una arquitectura técnica escalable y flexible, que también soportaría el paradigma de procesamiento en streaming de la información.
Si te ha parecido interesante este artículo, te animamos a visitar la categoría Data Engineering de nuestro blog para ver post similares a este y a compartirlo en redes con todos tus contactos. No olvides mencionarnos para poder conocer tu opinión @Damavisstudio. ¡Hasta pronto!
