
¿Qué es y cómo funciona Apache Airflow?
Uno de los procesos de trabajo de un data engineer es el conocido ETL (Extract, Transform, Load). Este proceso permite a las organizaciones tener la capacidad de cargar el dato desde diferentes fuentes, aplicar un tratamiento adecuado y cargarlos en un destino que sea aprovechable para tomar estrategias de negocio.
Esta serie de procesos deben ser automatizados y orquestados según las necesidades de la empresa. Además, persiguen el objetivo de reducir costes, acelerar los procesos y eliminar posibles errores humanos.
Entre las alternativas catalogadas como software libre disponibles para la orquestación de flujos de trabajo (workflows) aparece Apache Airflow. Gracias a esta herramienta, podemos planificar y automatizar diferentes pipelines.
La automatización de un pipeline ETL se puede realizar mediante el uso de grafos dirigidos acíclicos (DAG). Principalmente, Apache Airflow se compone de un webserver, usado como interfaz de usuario, y un scheduler, encargado de planificar las ejecuciones y comprobar el estado de las tasks pertenecientes al DAG.
En el scheduler aparece un mecanismo llamado Exectutor. Su función es programar las tasks para que sean ejecutadas por los workers (nodos de trabajo) que forman parte del DAG.
Cada tarea constituye un nodo dentro del grafo y es definido en forma de operator. Existen numerosos operadores predefinidos e incluso se pueden desarrollar operadores propios en caso de ser necesario.
Despliegue de Kubernetes con Airflow
Gracias a que esta plataforma se despliega en función de su arquitectura, puede llegar a ser altamente escalable y eficiente en coste.
La forma inicial de montaje de un entorno con Airflow suele ser Standalone. Consiste en hacer uso de un SequentialExecutor, que usa un SQLite como backend, con lo que conlleva una pérdida de posibilidad de paralelismo. Este modo ejecuta un solo proceso en la misma máquina que el Scheduler y permite la ejecución de una sola task simultáneamente, tal como su nombre indica.
En entornos de producción con cargas y tráfico de datos de mayor magnitud, el modo Standalone no es una opción recomendable. Nos será de gran ayuda poder paralelizar las tareas que se ejecuten dentro de nuestro flujo de trabajo y para ello haremos uso del CeleryExecutor.
Como vemos, Airflow ofrece una gran flexibilidad. No obstante, una de las limitaciones es que en tiempo de ejecución el usuario está limitado a las dependencias y los frameworks que existen en el nodo de trabajo.
Cómo funciona CeleryExecutor en Kubernetes
Es en este punto donde aparece una alternativa utilizando Kubernetes. Se trata de una plataforma para la orquestación y administración de cargas de servicios, permitiendo de una forma más fácil desplegar y escalar aplicaciones sin la necesidad de tener la limitación de dependencias comentada.
La opción que cubriremos en este post es usando CeleryExecutor y aplicando el operador KubernetesPodOperator. CeleryExecutor planifica las tareas, las envía a una cola de mensajería (RabbitMQ, Redis…) y los workers se encargan de ejecutarlas. Estos elementos son independientes y pueden estar en máquinas diferentes del clúster:
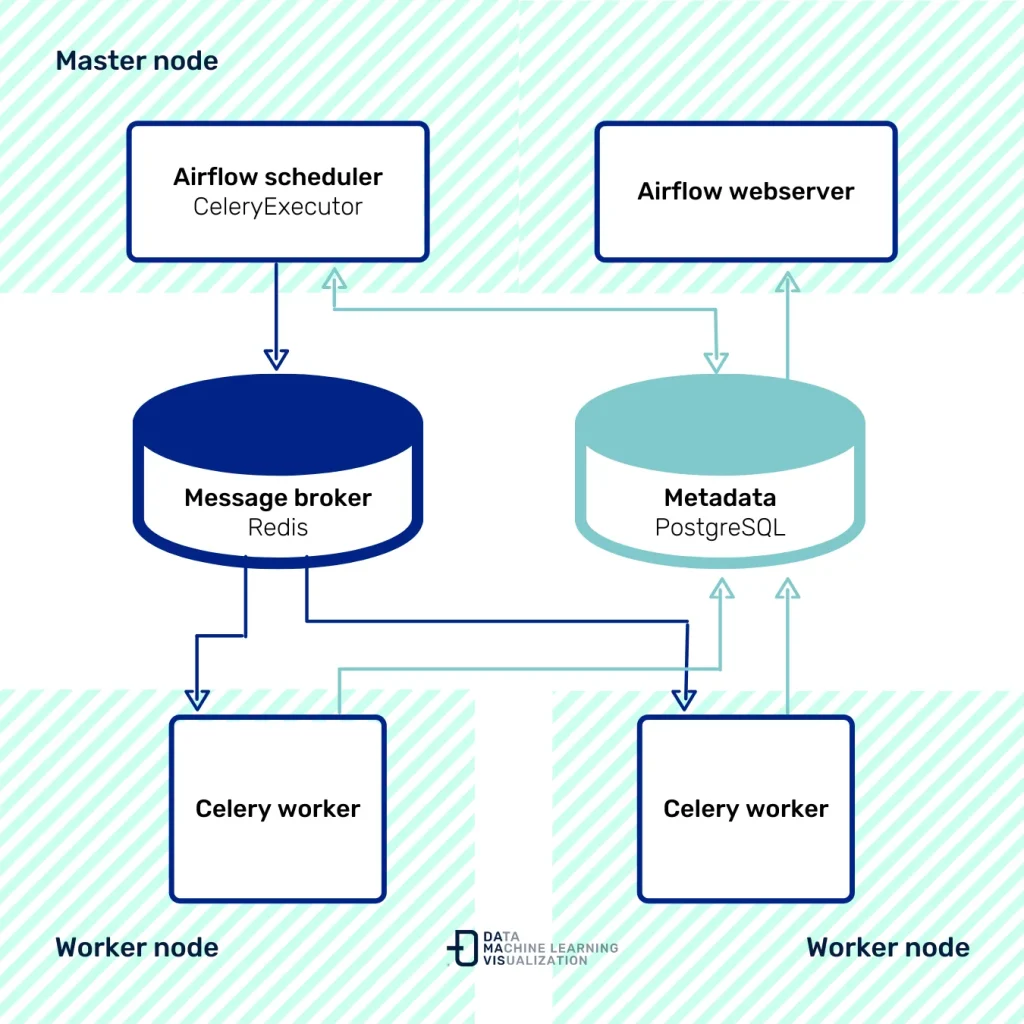
La escalabilidad es una gran ventaja en este caso, ya que se pueden añadir más workers en caso de ser necesario. KubernetesPodOperator nos ofrece la flexibilidad de que cada task ejecutada con este operador se despliegue en un Pod de Kubernetes.Cada task estará dentro de un contenedor independiente de Docker con todas las dependencias y configuración necesaria para su ejecución.
De esta forma, las tareas son independientes del nodo de trabajo en el que se ejecutan.
Airflow estará desplegado en un cluster de Kubernetes. Con esto conseguimos que el proceso pueda escalar tanto vertical como horizontalmente, dependiendo de las necesidades del momento.
Para el despliegue utilizaremos Helm, un gestor de paquetes de Kubernetes que permite la configuración, creación y testeo de aplicaciones de Kubernetes.
Una vez explicado el contexto, es hora de ponernos manos a la obra y configurar el despliegue de la infraestructura. ¡Empecemos!
Guía de implementación de Airflow y Kubernetes
En esta guía, asumimos que:
- Dispones de un cluster de Kubernetes en ejecución (Minikube).
- Helm (v3.4.1) y kubectl (v1.18) instalados.
- Tienes el código fuente de los DAGs almacenado en un repositorio de Git. En caso de no tener un repositorio, en este enlace puedes encontrar nuestro repositorio ejemplo para el caso práctico.
Creación del namespace dentro de Kubernetes
La aplicación se despliega dentro de un namespace en Kubernetes:
kubectl create namespace airflowConfiguración del fichero values.yaml para desplegar Airflow
Tenemos que generar una plantilla para desplegar todos los elementos. El ejemplo de plantilla lo puedes encontrar en el fichero values.yaml del repositorio de Helm.
La imagen que usaremos será la imagen oficial proporcionada por Apache.
A continuación, necesitamos definir los siguientes elementos:
- Airflow.
- Flower: herramienta de monitorización de la cola de mensajería.
- Workers: número de trabajadores que asumen la carga de trabajo.
- Redis: cola de mensajería para transmitir la información a los workers.
- PostgreSQL: base de datos que utiliza Airflow como backend.
Un ejemplo de plantilla es el fichero airflow-celery.yaml disponible en este enlace.
Instalación del chart de Helm
Para instalar el chart, antes nos aseguraremos de tener el repositorio añadido en Helm:
helm repo add airflow-stable https://airflow-helm.github.io/charts
helm repo updateCon esto ya podemos lanzar el despliegue:
helm install airflow --namespace airflow airflow-stable/airflow --values ./airflow-celery.yamlSi el despliegue ha salido correctamente, deberíamos ver el siguiente mensaje:
NAME: airflow
LAST DEPLOYED: Fri Jan 29 15:33:06 2021
NAMESPACE: airflow
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Congratulations. You have just deployed Apache Airflow
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
You can watch the status of the service by running 'kubectl get svc -w airflow'Con la ejecución de este comando, tendremos lo siguiente en el cluster:
- 3 Deployments: Scheduler + web IU + redis + flower.
- 1 Persistent volumes: PostgreSQL.
- 1 Pod por Worker definido.
Podemos ver el estado de los servicios con el siguiente comando:
kubectl get service --namespace=airflowNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
airflow-flower ClusterIP 10.107.148.59 <none> 5555/TCP 29m
airflow-postgresql ClusterIP 10.109.52.69 <none> 5432/TCP 29m
airflow-postgresql-headless ClusterIP None <none> 5432/TCP 29m
airflow-redis-headless ClusterIP None <none> 6379/TCP 29m
airflow-redis-master ClusterIP 10.101.106.143 <none> 6379/TCP 29m
airflow-web ClusterIP 10.96.195.146 <none> 8080/TCP 29m
airflow-worker ClusterIP None <none> 8793/TCP 29mkubectl get deployments --namespace airflowNAME READY UP-TO-DATE AVAILABLE AGE
airflow-flower 1/1 1 1 29m
airflow-scheduler 1/1 1 1 29m
airflow-web 1/1 1 1 29mPara acceder al servicio de Airflow realizamos port-forwarding.
kubectl port-forward service/airflow-web 8080:8080 --namespace airflow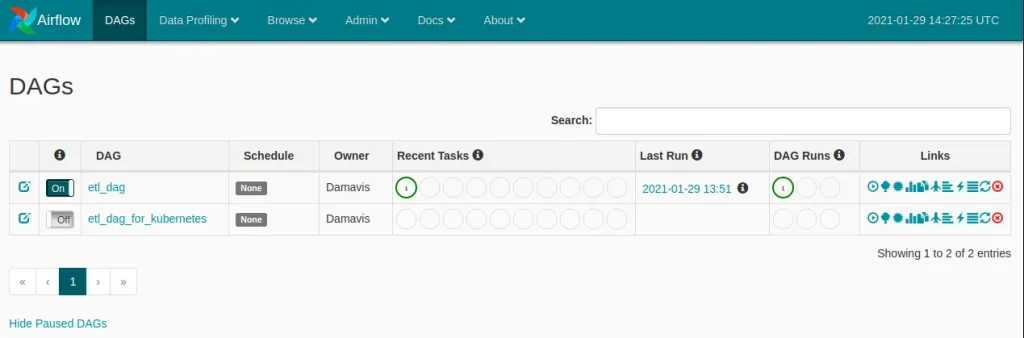
Por otra parte, haciendo port-forwarding del servicio Flower podemos realizar una monitorización de la cola de tareas.
kubectl port-forward service/airflow-flower 5555:5555 --namespace airflow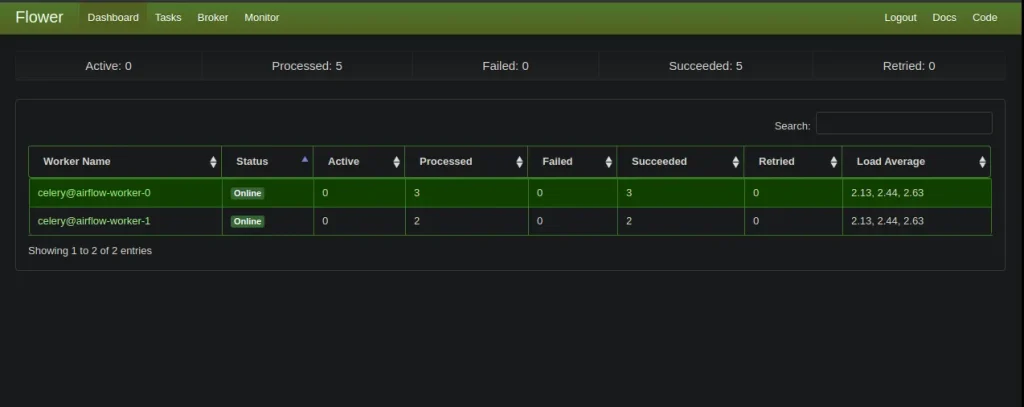
Ejecución de un pipeline con KubernetesPodOperator
El fichero etl_dag_celery.py es un ejemplo básico de un DAG con una operación con este operador.
from airflow import DAG
from datetime import datetime, timedelta
from airflow.contrib.operators import kubernetes_pod_operator
default_args = {
'owner': 'Damavis',
'start_date': datetime(2020, 5, 5),
'retries': 1,
'retry_delay': timedelta(seconds=5)
}
with DAG('etl_dag',
default_args=default_args,
schedule_interval=None) as dag:
extract_tranform = kubernetes_pod_operator.KubernetesPodOperator(
namespace='airflow',
image="python:3.7-slim",
cmds=["echo"],
arguments=["This can be the extract part of an ETL"],
labels={"foo": "bar"},
name="extract-tranform",
task_id="extract-tranform",
get_logs=True
)
extract_tranformEjecutando el workflow en Airflow podemos ver el funcionamiento descrito anteriormente en el dashboard proporcionado por minikube.
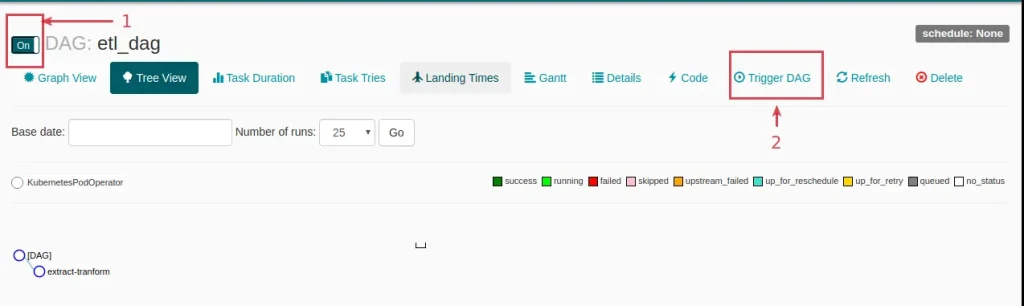
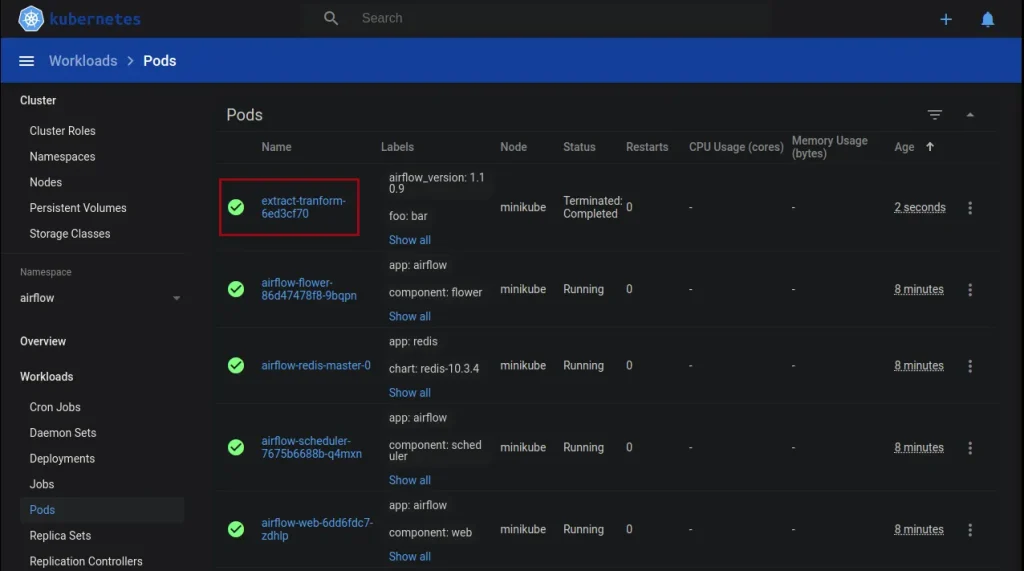
Y con estos pasos tenemos desplegada una infraestructura Airflow sencilla a la vez que versátil con CeleryExecutor en Kubernetes.
Esta estructura nos permite tener una primera aproximación a la escalabilidad, no obstante está limitada al número de workers desplegados. Lo interesante sería que esta escalabilidad fuese determinada por el sistema, y que la red de Pods fueran desplegados por cada tarea aprovechando la potencia de los operadores de Airflow ¿no crees?.
Existe la posibilidad mediante el uso de KubernetesExecutor, pero esto será parte de un siguiente post.
Hasta entonces, si te ha parecido útil este post, puedes pasarte por la categoría Data Engineering de nuestro blog para ver más artículos como este y compartirlo con tus contactos para que ellos también puedan leerlo y opinar. ¡Nos vemos en redes!
