
En un post anterior, analizamos desde el punto de vista teórico las principales librerías para ciencia de datos y machine learning que utilizan los data scientists para tratar los datos de una forma eficiente y extraer todo su potencial.
En este artículo, lo llevaremos a la práctica a través de ejemplos sencillos que muestren cómo se trabaja con estas librerías. Para ello, haremos hincapié en lo que ofrecen al usuario interesado en el machine learning.
Machine Learning con Python
Python es uno de los lenguajes de programación más utilizados y extendidos en la actualidad. Además, cuenta con una tendencia alcista en su uso durante los últimos años. Esta afirmación puede verse reflejada de forma clara en el ranking anual usado como referencia para conocer los lenguajes de programación más utilizados. Este índice se conoce como el índice TIOBE.
TIOBE es un indicador de la popularidad de estos lenguajes. Se basa en elementos como el número de ingenieros a lo largo del mundo, cursos o cantidad de proveedores externos. Toda la información recopilada para calcularlo proviene de los motores de búsqueda más conocidos (Google, Bing, Yahoo, Baidu…). Por tanto, el índice no refleja qué lenguaje de programación es mejor o en cuál se han escrito más líneas de código. Lo que muestra es su popularidad general.
Por qué se usa Python en Machine Learning
La notoriedad de Python se debe a la gran cantidad de ventajas y opciones que ofrece respecto a sus competidores. Es un lenguaje de programación de código abierto, por lo que no existen prácticamente limitaciones para su uso. Además, ofrece la posibilidad de colaborar para su mejora formando parte de su amplia comunidad.
Python cuenta con una sintaxis sencilla, legible y fácil de entender. Por eso, es adecuado tanto para aquellos usuarios que comienzan a programar como para los que buscan ahorrar tiempo y recursos a la hora de desarrollar software de forma eficiente. Todo esto, sumado a la gran cantidad de librerías, frameworks y paradigmas que ofrece Python, lo convierten en uno de los lenguajes de programación más polivalentes y versátiles que existen. Es un lenguaje de propósito general apto para la gran mayoría de usuarios a pesar de sus especialidades o intereses.
Por último, que sea de código abierto y la popularidad que ha alcanzado en la actualidad, hacen que posea una gran comunidad sólida. Dicha comunidad está dispuesta a ayudar a los demás usuarios con sus dudas y a que el ecosistema Python siga creciendo y mejorando para todo el mundo.
Estas ventajas, junto con la existencia de un gran número de librerías, herramientas y frameworks adecuados para el procesamiento de datos, convierten a Python en el lenguaje de programación idóneo en tareas relacionadas con el campo del aprendizaje automático y, en general, del campo de la inteligencia artificial y la ciencia de datos.
Librerías de Python más usadas para Machine Learning
Pandas
Pandas es la librería de referencia en Python en lo que a manipulación y análisis de datos se refiere. Es de código abierto y apuesta por un análisis y manejo flexible, eficiente y disponible de uno de los recursos más valiosos para la empresa, el dato.
Para poder llevar a cabo esta tarea, Pandas ofrece principalmente dos estructuras de datos clave. La serie como estructura unidimensional y el DataFrame como estructura bidimensional representada en forma de tabla. Ambas, de forma conjunta, permiten el manejo de la mayoría de conjuntos de datos de una forma intuitiva y sencilla.
Algunas de las utilidades más comunes y relevantes de esta librería son las siguientes:
- El uso del DataFrame como estructura de datos principal permite diverssas operaciones. Por ejemplo, la agrupación, integración, iteración o indexado de datos rápidamente.
- Posee herramientas para realizar operaciones de lectura y escritura de datos manejando diferentes estructuras y formatos de datos.
- Permite el tratamiento de valores perdidos.
- Permite la ejecución de cadenas de operaciones sobre los datos de forma vectorizada.
- Contiene herramientas para el tratamiento y la transformación de series temporales.
- Ofrece una representación unificada de los datos que permite la integración con otras librerías de Python de forma sencilla.
Ejemplo de uso de la librería Pandas
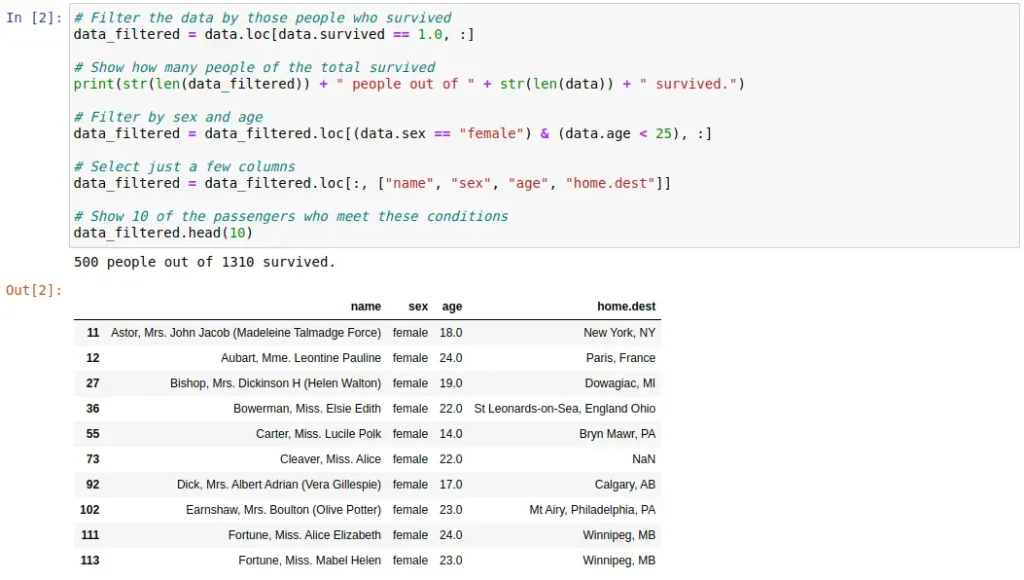
A continuación, se muestran unas celdas de código con un ejemplo de uso sencillo de la librería Pandas. En este ejemplo, primero se lee un conjunto de datos en formato CSV para poder visualizarlo. Posteriormente, se obtiene y muestra un subconjunto de dichos datos que se corresponde con los pasajeros del Titanic que sobrevivieron y cumplen ciertas condiciones.
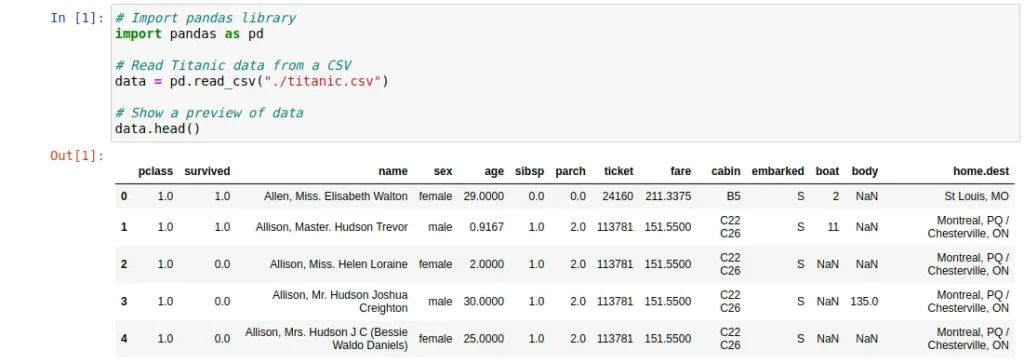
un conjunto de datos.
Numpy
NumPy (Numeric Python) es otra de esas librerías que no pueden faltar en tu arsenal para afrontar problemas de ciencia de datos. Ofrece diferentes herramientas esenciales para la computación científica y el cálculo numérico orientado a matrices.
Esta librería introduce una nueva clase de objeto denominado Array. Un Array no es más que una estructura de datos propia de matrices N-dimensionales para un manejo eficiente. La necesidad de esta nueva representación surge debido a que la manipulación de listas nativas de Python de gran tamaño es muy poco eficiente. En gran parte, esto se debe a la flexibilidad que aportan como estructuras de datos, permitiendo modificar su tamaño de forma dinámica o albergar datos de diferentes tipos en una misma estructura.
Por otro lado, los Arrays de NumPy nos permiten un almacenamiento interno en memoria. Además, ofrecen un manejo eficaz gracias a una representación interna binaria en la que el número de bytes asociados a cada elemento de una matriz es fijo (los datos que conforman dicha matriz son todos del mismo tipo) y se representa únicamente el valor del dato, dejando de lado información añadida o metadatos.
Otro aporte de NumPy con respecto a Python es el soporte que ofrece para invocar funciones de forma vectorizada. Permite cálculos de forma optimizada eliminando bucles y evitando tener que acceder de forma secuencial a cada uno de los elementos que forman la matriz.
Cómo se usa Numpy en Machine Learning
Además de todo esto, NumPy ofrece herramientas y utilidades como las siguientes:
- Indexado y filtrado de los Arrays de forma sencilla y eficiente. Posibilita la obtención de nuevos Arrays que sean un subarray del original y cumplan una determinada condición.
- Operaciones matemáticas sencillas entre Arrays de forma intuitiva y vectorizada, utilizando operadores clásicos como +, -, *, /, …
- Operaciones algebraicas con vectores y matrices. Por ejemplo, el producto escalar de dos vectores, el producto de dos matrices, la transposición de una matriz, cálculo del determinante de una matriz, autovectores de una matriz, etc.
- Métodos integrados para la generación de matrices de datos aleatorios según diferentes distribuciones de probabilidad.
Al igual que hicimos con Pandas, a continuación se pueden observar dos celdas de código que muestran con un ejemplo simple algunas de las funcionalidades que aporta NumPy. Podemos ver desde la definición de Arrays hasta el uso de éstos para realizar distintas operaciones matemáticas y algebraicas.
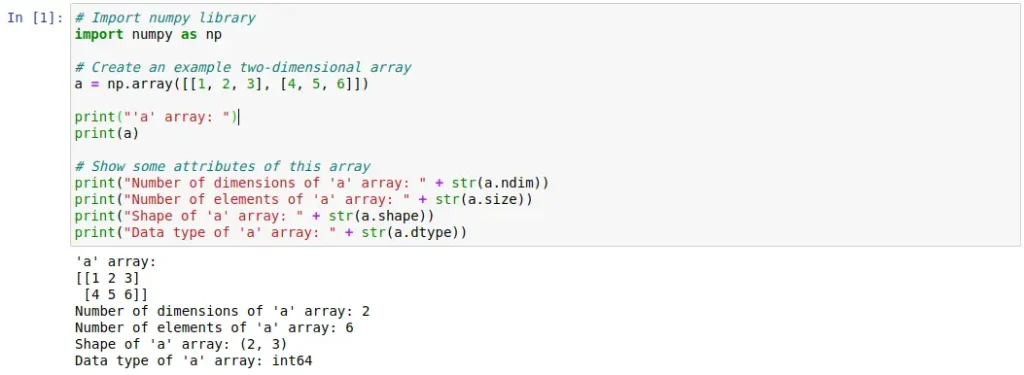
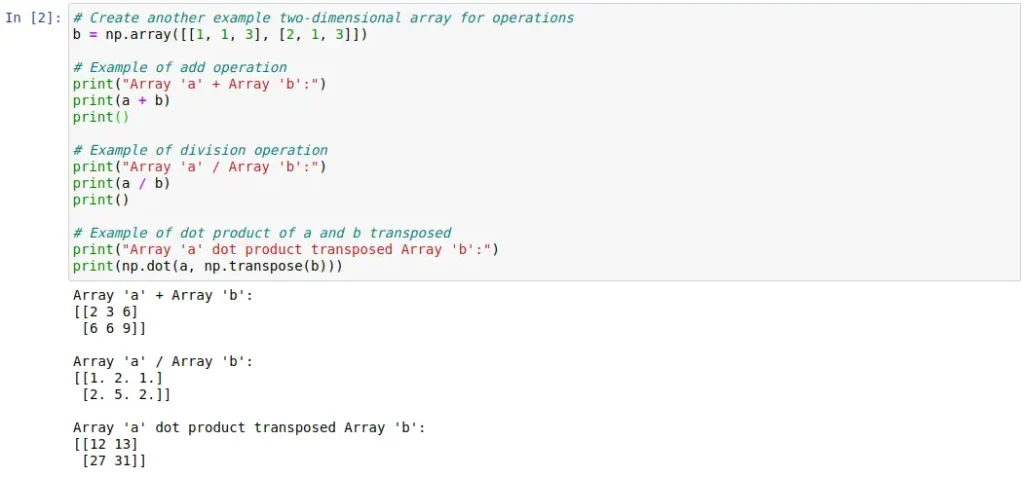
Scikit-learn
La tercera librería que vamos a revisar en este post es Scikit-learn. Se trata de una de las librerías de software libre más utilizada para realizar tareas de machine learning. Esto se debe a la cantidad de algoritmos de clasificación, regresión y agrupación de datos a los que da soporte de forma unificada. Scikit-learn hace posible su entrenamiento y evaluación de forma sencilla. Además, presenta una sintaxis muy simple y abstraída de los detalles de la implementación de dichos algoritmos.
Además, también aporta métodos para el preprocesado y la transformación de los datos previo al entrenamiento de los algoritmos. Esta característica, sumada a la variedad de modelos, permite una experimentación rápida y eficaz.
Algunos de los algoritmos y métodos que ofrece Scikit-Learn son los siguientes:
- Aprendizaje supervisado. Árboles de decisión, support vector machines (SVM), redes neuronales, K-nearest neighbor, naive bayes, regresión lineal, regresión logística, random forest, gradient boosting…
- Aprendizaje no supervisado. K-means, DBSCAN, BIRCH, clustering aglomerativo, OPTICS…
- Preprocesado y transformación. Selección de características, imputación de valores perdidos, label encoder, one hot encoder, normalizado, reducción de la dimensionalidad…
Esta librería también da soporte a la definición de pipelines para concatenar y gestionar en grupo conjuntos de elementos. De esta forma, mantiene la coherencia y la consistencia del proceso de desarrollo de principio a fin. En cuanto a la evaluación de los modelos, Scikit-learn cuenta con implementaciones de las métricas más utilizadas para la mayoría de las tareas de machine learning. Dichas métricas están integradas de una forma simple para la selección de modelos mediante búsqueda de hiperparámetros.
Ejemplo de cómo usar Scikit-learn en modelos de Machine Learning
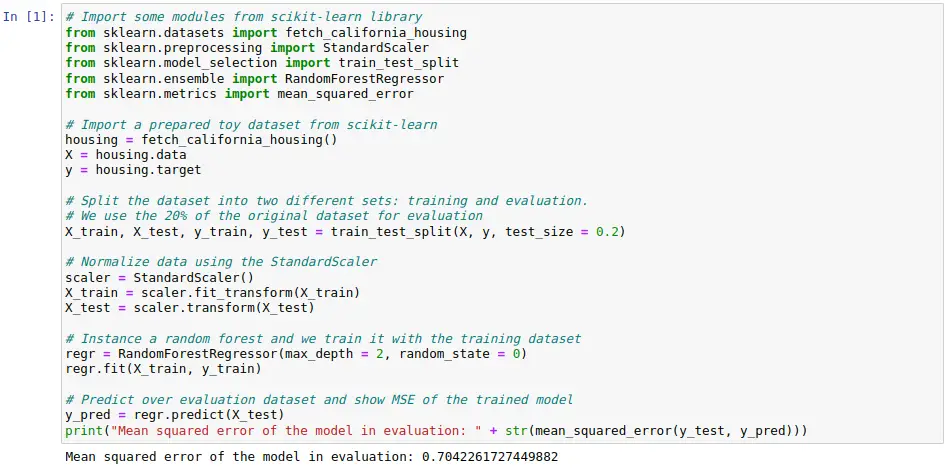
Un ejemplo de cómo instanciar, entrenar y evaluar un modelo de aprendizaje automático usando sólo Scikit-learn puede verse en el siguiente código. Se importa un conjunto de datos de ejemplo, que es dividido en entrenamiento y evaluación, y se normalizan los datos usando un escalado estándar. Después, se entrena un random forest usando sólo el conjunto de entrenamiento. Por último, se evalúa dicho modelo utilizando como métrica el error cuadrático medio sobre el conjunto de evaluación.
Matplotlib
A diferencia del resto, Matplotlib es una librería especializada en la creación de gráficos en dos dimensiones para la visualización de datos. Está construida sobre los Arrays de NumPy y permite una integración sencilla con un gran número de librerías en Python como Pandas.
Algunos de los tipos de gráficos para los que Matplotlib da soporte son los siguientes:
- Histograma
- Gráfico de barras
- Gráfico de sectores
- Caja y bigotes
- Gráfico de violín
- Dispersión
- Áreas apiladas
- Gráfico de líneas
- Mapa de calor
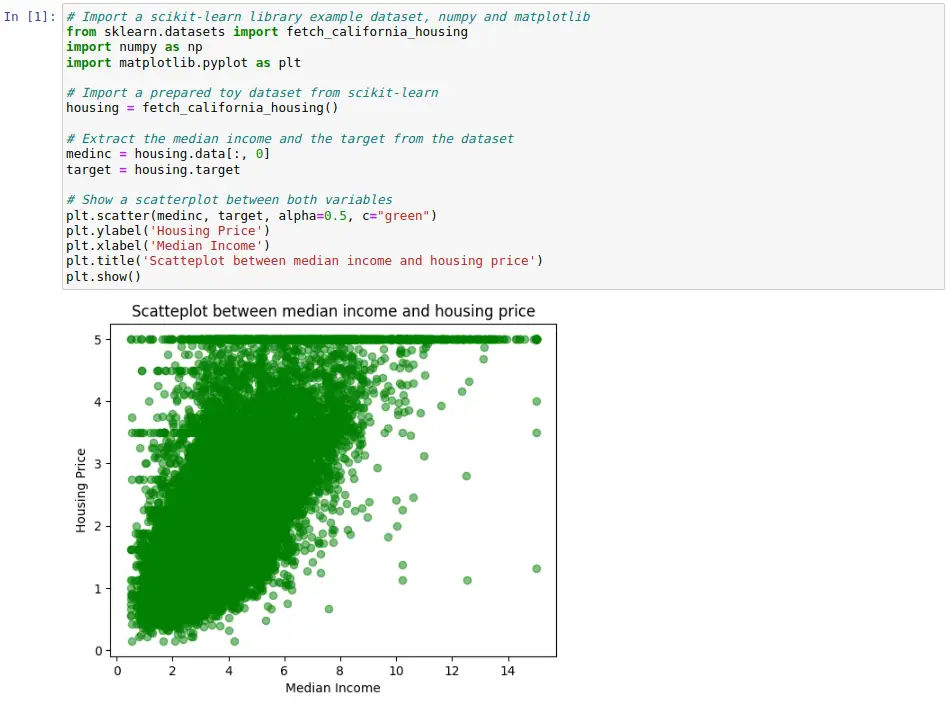
La galería de la página web oficial de Matplotlib contiene muchos ejemplos de todos estos gráficos y algunos más junto con el código asociado en Python para poder generarlos. En este post, hemos incluido una celda de código con la creación de un diagrama de dispersión sencillo mediante Matplotlib. En él, se ha utilizado el mismo conjunto de datos de ejemplo que se usó previamente en el apartado anterior.
Por último, cabe señalar que existen otras librerías orientadas a la creación de gráficos que utilizan Matplotlib como base. Estas librerías facilitan su uso y extienden Matplotlib para crear visualizaciones de buena calidad con la menor intervención posible. Es el caso de la librería Seaborn.
TensorFlow / Keras
Podemos definir TensorFlow como una librería open-source de alto rendimiento orientada al cálculo numérico. Por debajo, usa grafos acíclicos dirigidos (DAG) para representar dichas operaciones, que se suceden unas a otras a la hora de realizar procesos complejos.
Los tensores son objetos matemáticos que actúan como una generalización de números escalares, vectores y matrices de diferentes dimensiones. Son la pieza fundamental para representar los datos en esta librería, concepto del que TensorFlow adquiere parte de su nombre. Esta librería fue desarrollada por Google y posteriormente liberada como código abierto en 2015. En este momento, fue ampliamente adoptada por la industria y la comunidad de investigación debido a la amplia gama de ventajas que ofrece a la hora de afrontar problemas de aprendizaje automático.
El uso de grafos para representar los cómputos a realizar provoca que dichas operaciones sean totalmente independientes del código subyacente, haciendo que estas sean portables entre diferentes dispositivos y entornos. Esto permite, por ejemplo, desarrollar un modelo en Python, almacenarlo en algún formato intermedio y posteriormente cargarlo en un programa de C++ de otro dispositivo para ejecutarlo de una forma más optimizada. De esta forma, puedes usar prácticamente el mismo código para ejecutar un conjunto de operaciones usando únicamente la CPU del ordenador, la tarjeta gráfica (GPU) para acelerar los cálculos, o incluso varias tarjetas gráficas de forma conjunta.
Uso de Keras con Tensorflow
Todas estas ventajas hacen de TensorFlow una plataforma perfecta para el desarrollo de modelos de aprendizaje automático. Especialmente, para la construcción y el entrenamiento de redes neuronales. En este punto aparece Keras, una API diseñada para trabajar con TensorFlow. Keras ofrece abstracciones intuitivas de alto nivel que pretenden simplificar en gran medida el desarrollo de este tipo de algoritmos, minimizando el número de acciones del usuario requeridas para la mayoría de casos de uso más comunes. Además, no sólo es capaz de trabajar y ejecutarse sobre TensorFlow. También puede hacer uso de otras librerías de bajo nivel como Theano o Microsoft Cognitive Toolkit.
El uso de TensorFlow no se limita al desarrollo de modelos de aprendizaje automático. Además, permite realizar todo tipo de tareas en relación a dicho desarrollo como las siguientes:
- Preparación de los datos, desde la carga de estos hasta su preprocesamiento previo a la entrada de los modelos.
- Evaluación y monitorización de la salida de los modelos de forma precisa y sencilla.
- Ejecución de modelos en dispositivos móviles y sistemas embebidos con TensorFlow Lite.
- Despliegue de los modelos en entornos de producción, ayudando a implementar las mejores prácticas para aplicar una metodología MLOps.
- Exploración y uso de modelos previamente entrenados por la comunidad mediante TensorFlow Hub.
Cómo usar TensorFlow y Keras para crear redes neuronales
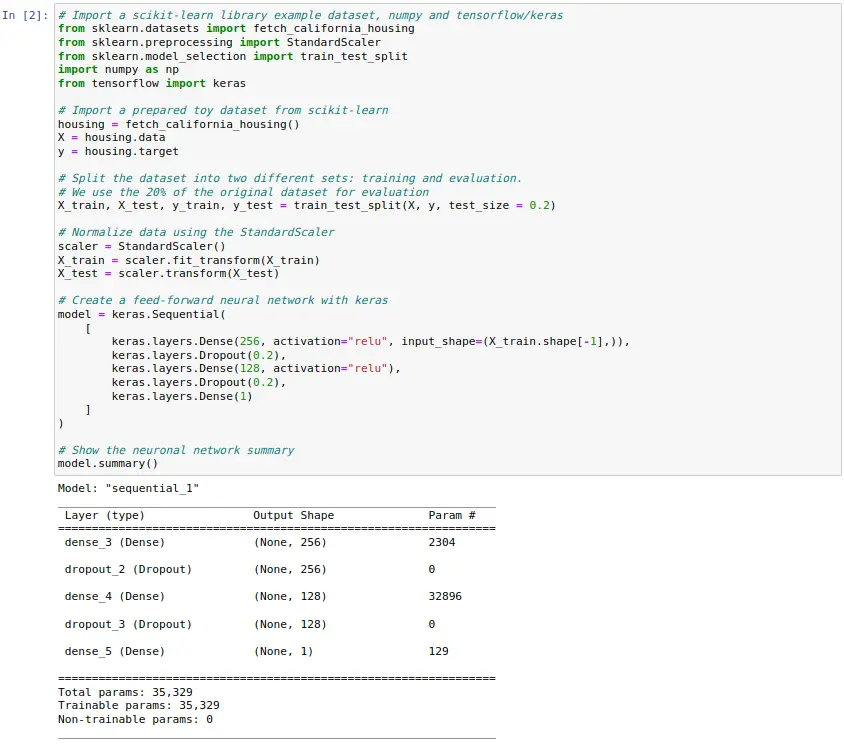
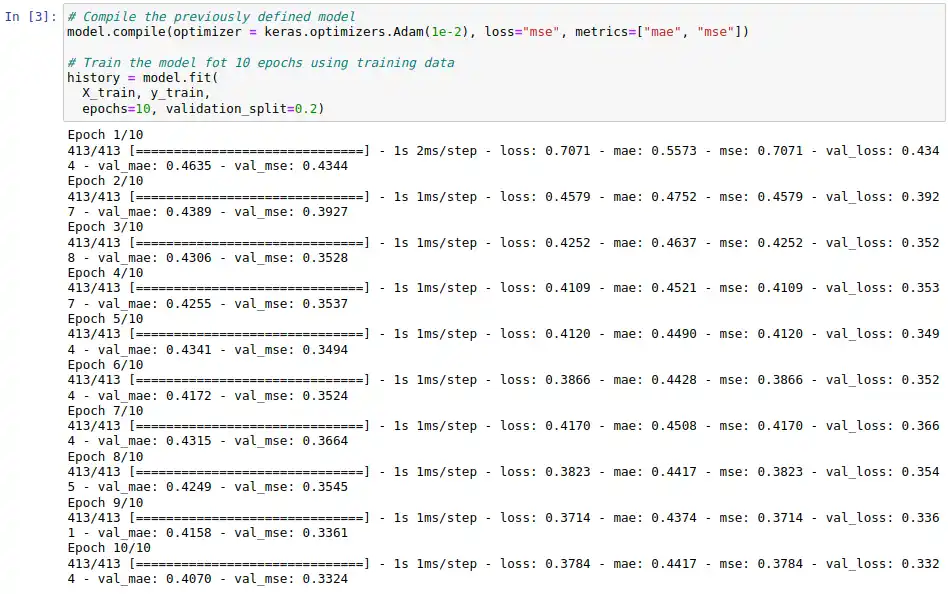
En el siguiente ejemplo se puede observar un caso de uso en el que se utiliza Keras con TensorFlow como backend para definir una red neuronal que sea capaz de resolver el mismo problema abordado previamente con Scikit-learn. Para ello, primero se define una red neuronal multicapa sencilla. Esta red neuronal es entrenada utilizando el conjunto de datos ya usado durante 10 épocas para, posteriormente, evaluarla utilizando un método propio que nos aporta Keras.

Scipy
La última librería que veremos en este post es Scipy. Esta librería de código abierto ofrece un gran número de herramientas y algoritmos matemáticos para resolver problemas de optimización, interpolación, ecuaciones algebraicas, ecuaciones diferenciales o estadística, entre otros. Está construida para trabajar con Arrays de NumPy, ofreciendo una interfaz sencilla para afrontar problemas matemáticos. Dicha interfaz es gratuita, potente, fácil de instalar y puede ser utilizada en los sistemas operativos más comunes.
Una de las grandes ventajas de Scipy es su gran velocidad. Utiliza implementaciones altamente optimizadas escritas en lenguajes de bajo nivel como Fortran, C o C++. El gran beneficio de esta característica es la flexibilidad que aporta Python como lenguaje de programación sin dar de lado la velocidad de ejecución del código compilado necesaria para realizar este tipo de tareas. Además, Scipy ofrece una sintaxis de alto nivel fácil de utilizar e interpretar. Esto la hace accesible y productiva tanto para programadores con poca experiencia como para profesionales.
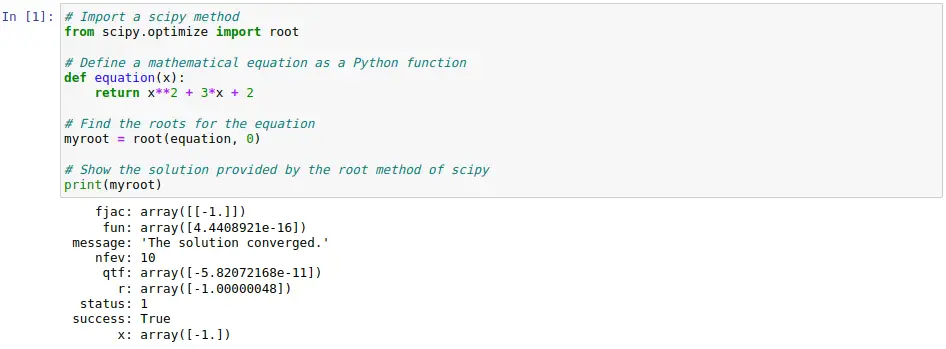
Ejemplo de cómo utilizar la librería Scipy
La siguiente celda de código pretende representar un caso de uso sencillo de la librería Scipy. En él, se pretende buscar las raíces para una ecuación matemática de segundo grado. Para ello, se hace uso del método root que proporciona Scipy. Con dicho método se pueden obtener las raíces para ecuaciones lineales y no lineales.
Conclusión
Python es uno de los lenguajes de programación del momento. Destaca, entre otros motivos, por la gran cantidad de librerías, frameworks y paradigmas que ofrece. En este post, se han revisado en detalle las funcionalidades que aportan algunas de las librerías de Python más utilizadas en el ámbito del procesamiento de datos. Hemos analizado en detalle su aplicabilidad práctica y mostrado algunos ejemplos sencillos de código para familiarizar al lector con estas herramientas.
Si te ha gustado el post, te animamos a que visites la categoría Data Science para ver otros artículos similares a este y a que lo compartas en las redes sociales. ¡Hasta pronto!
