
In a previous post, we analyzed from a theoretical point of view which are the main libraries for data science and machine learning used by data scientists to treat data efficiently and extract its full potential.
In this post, we will put it into practice through simple examples that show how to work with these libraries. To do so, we will emphasise what they offer to the user interested in the world of machine learning.
Machine Learning with Python
Python is one of the most widely used programming languages today. Moreover, it has seen an upward trend in its use over the last few years. This statement can be clearly reflected in the annual ranking used as a reference to know the most used programming languages. This index is known as TIOBE index.
TIOBE is an indicator of the popularity of these languages. It is based on elements such as the number of engineers worldwide, courses or number of external suppliers. All the information collected to calculate it comes from the most popular search engines (Google, Bing, Yahoo, Baidu…). Therefore, the index does not reflect which programming language is better or in which programming language more lines of code have been written, but its overall popularity.
Why Python is used in Machine Learning
Python’s popularity is due to the large number of advantages and options it has over its competitors. It is an open source programming language, so there are virtually no limitations to its use. In addition, it offers the possibility of collaborating to improve it by becoming part of its large community.
Python has a simple, readable and easy to understand syntax. For this reason, it is suitable both for users who are just starting to program and for those who are looking to save time and resources when developing software in an efficient way. All this, added to the large number of libraries, frameworks and paradigms that Python offers, makes it one of the most versatile and versatile programming languages that exist. It is a general purpose language suitable for the vast majority of users regardless of their specialisations or interests.
Finally, the fact that it is open source and that it is so popular nowadays, means that Python has a large and solid community, willing to help other users with their doubts and that the Python ecosystem continues to grow and improve for everyone.
These advantages, combined with the existence of a large number of libraries, tools and frameworks suitable for data processing, make Python the ideal programming language for carrying out tasks related to the field of machine learning and, in general, the field of artificial intelligence and data science.
Most popular libraries for Machine Learning in Python
Pandas
Pandas is the reference library in Python for data manipulation and analysis. It is an open source library that is committed to a flexible, efficient and available to all analysis and management of one of the most valuable resources for the company, the data.
In order to carry out this task, Pandas offers mainly two key data structures. The series as a one-dimensional structure and the DataFrame as a two-dimensional structure represented as a table. Together, they allow the handling of most datasets in an intuitive and simple way.
Some of the most common and relevant utilities of this library are the following:
- Thanks to the use of the DataFrame as the main data structure it allows several operations. For example, clustering, summarising, iterating or indexing data quickly.
- Among its capabilities are tools for data reading and writing, supporting different structures and formats.
- It allows the treatment of missing values.
- It also enables executing chains of operations on data in a vectorized way.
- Contains tools for the processing and transformation of time series.
- It offers a unified representation of the data that allows the integration of the data with other Python libraries in a simple way.
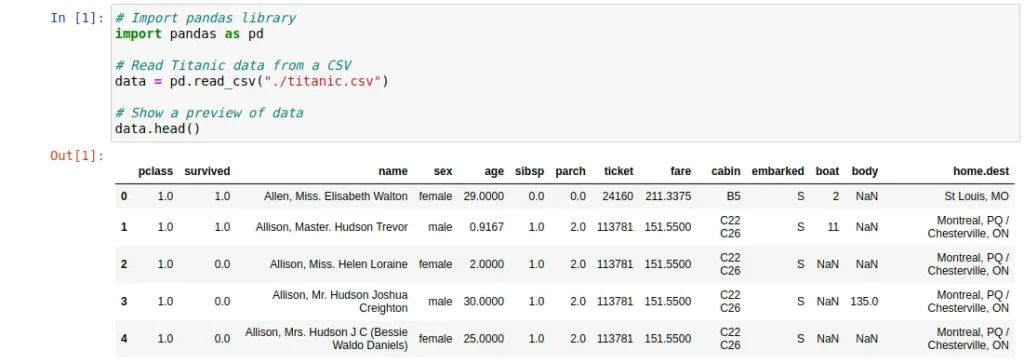
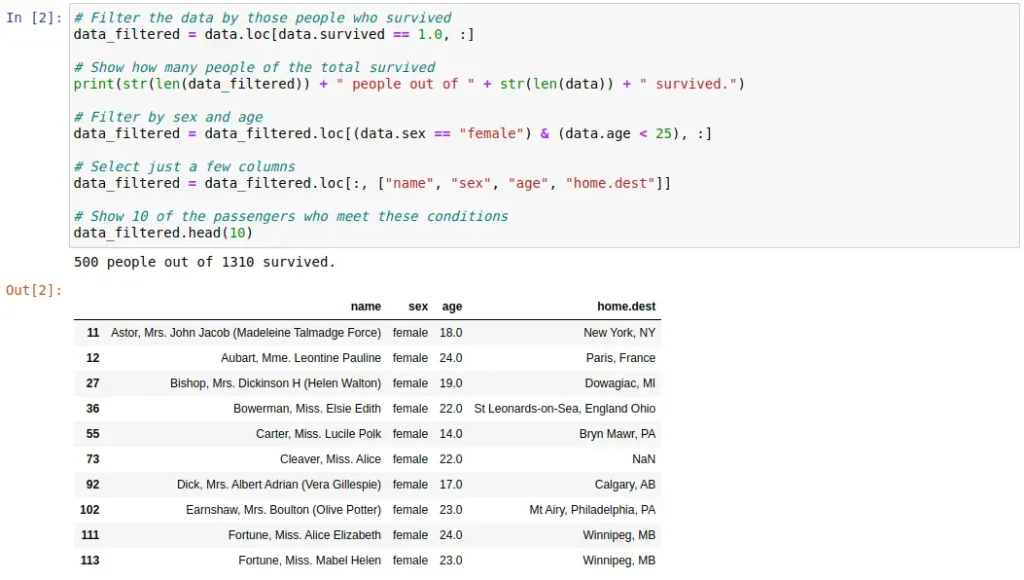
Pandas library usage example
Below are some code cells with an example of a simple use of the Pandas library. In this example, we first read a dataset in CSV format in order to visualize it. Then, a subset of this data is obtained and displayed, corresponding to those Titanic passengers who survived and meet certain conditions.
Numpy
NumPy (Numeric Python) is another one of those libraries that cannot be missing in your arsenal if you intend to tackle problems in the field of data science. It offers different essential tools for scientific computing and matrix-oriented numerical computation.
This library introduces a new kind of object called Array. An Array is nothing more than an N-dimensional array data structure for efficient handling. The need for this new representation arises because the manipulation of large native Python lists is very inefficient. This is largely due to the flexibility they provide as data structures, allowing to dynamically resize them or to hold data of different types in the same structure.
On the other hand, NumPy’s arrays allow for internal storage. In addition, they offer efficient handling thanks to an internal binary representation in which the number of bytes associated with each element of an array is fixed (the data that make up the array are all of the same type) and only the value of the data is represented, leaving aside added information or metadata.
Another contribution of NumPy with respect to Python is the support it offers for invoking functions in a vectorized way. It allows optimised calculations by eliminating loops and avoiding having to access sequentially to each of the elements that make up the matrix.
How Numpy is used in Machine Learning
In addition to all this, NumPy offers tools and utilities such as the following:
- Indexing and filtering of Arrays in a simple and efficient way. It makes it possible to obtain new Arrays that are a subarray of the original one and meet a certain condition.
- Simple mathematical operations between Arrays in an intuitive and vectorized way, using classic operators such as +, -, *, /, …
- Algebraic operations with vectors and matrices. For example, the scalar product of two vectors, the product of two matrices, the transpose of a matrix, calculation of the determinant of a matrix, autovectors of a matrix…
- Integrated methods for the generation of random data matrices according to different probability distributions.
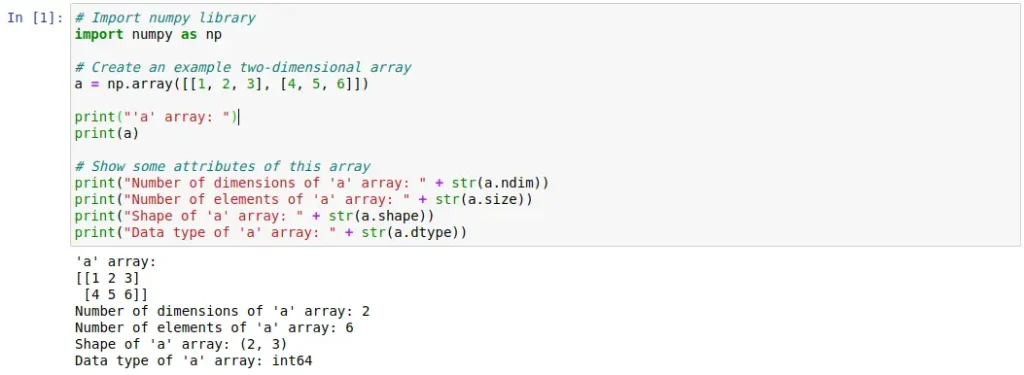
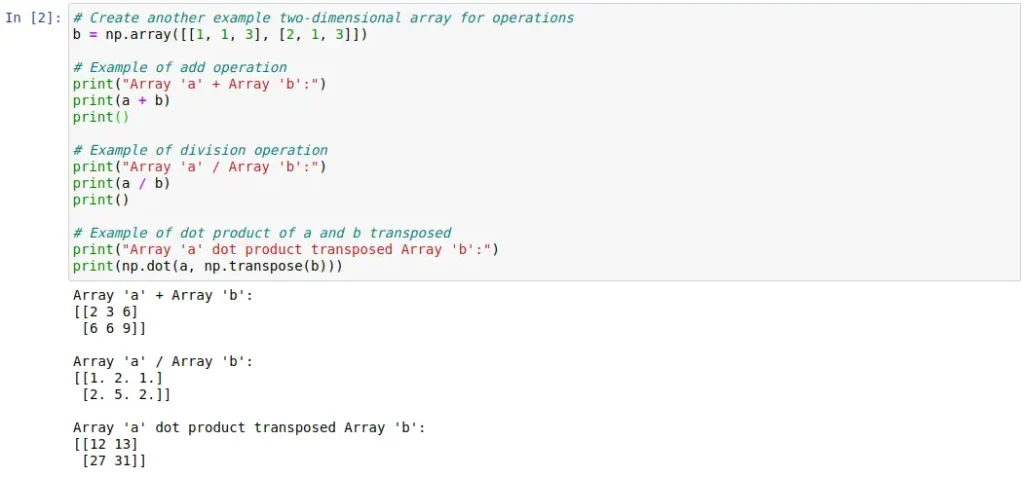
As was done with the Pandas, here are two cells of code that show, with a simple example, some of the functionalities provided by the NumPy library. We can see from the definition of arrays to their use to perform different mathematical and algebraic operations.
Scikit-learn
The third library we are going to review in this post is Scikit-learn. It is one of the most widely used free software libraries to carry out tasks related to the field of machine learning. This is largely due to the number of classification, regression and clustering algorithms it supports in a unified way. Scikit-lear makes it possible to ttrain and evaluate them in a simple way. In addition, it presents a very simple syntax abstracted from the implementation details of these algorithms.
On the other hand, it also provides methods for pre-processing and transforming the data prior to training the algorithms. This feature, together with the variety of models, allows for quick and efficient experimentation.
Some of the algorithms and methods offered by Scikit-Learn are the following:
- Supervised learning. Decision trees, support vector machines (SVM), neural networks, K-nearest neighbours, naive bayes, linear regression, logistic regression, random forest, gradient boosting…
- Unsupervised learning. K-means, DBSCAN, BIRCH, agglomerative clustering, OPTICS…
- Preprocessing and transformation. Feature selection, missing value imputation, label encoder, one hot encoder, normalization, dimensionality reduction…
This library supports the definition of pipelines to concatenate and manage sets of elements in groups. In this way, it maintains the coherence and consistency of the development process from start to finish. In terms of model evaluation, Scikit-learn has implementations of the most commonly used metrics for most machine learning tasks. These metrics are integrated in a simple way for model selection by hyperparameter search.
Example of how to use Scikit-learn in Machine Learning models
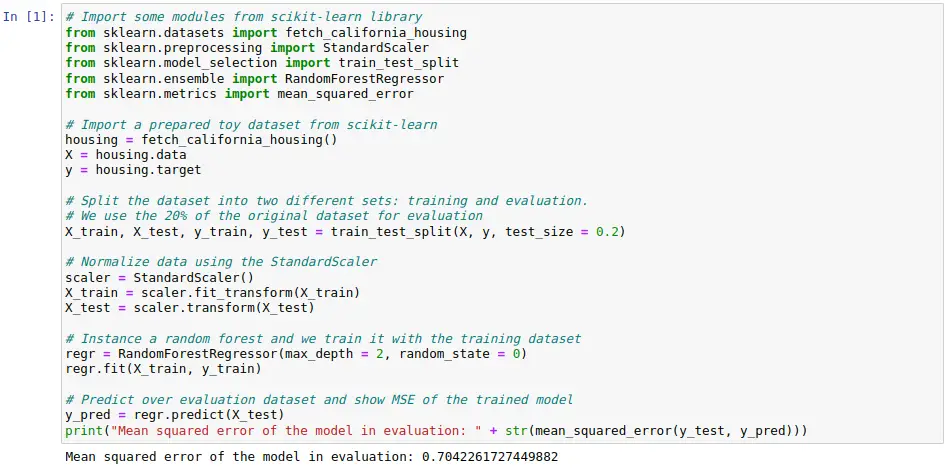
An example of how to instantiate, train and evaluate a machine learning model using only Scikit-learn can be visualized in the following code cell. An example dataset is imported, which is split into training and evaluation, and the data is normalised using standard scaling. Next, a random forest is trained using only the training set. Finally, the model is evaluated using the mean squared error on the evaluation set as a metric.
Matplotlib
Unlike the rest, Matplotlib is a library specialized in the creation of two-dimensional graphs for data visualization. It is built on top of NumPy arrays and allows easy integration with a large number of Python libraries such as Pandas.
Some of the chart types supported by Matplotlib are the following:
- Histogram
- Bar chart
- Pie chart
- Box and whisker diagram
- Violin diagram
- Scatter diagram
- Area diagram
- Line graph
- Heat map
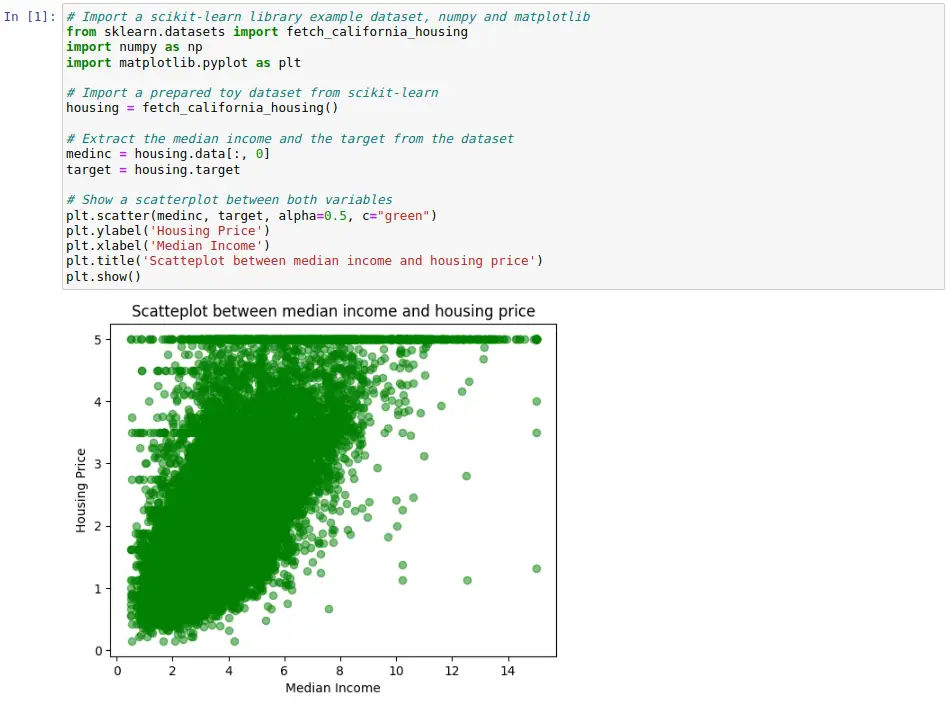
In the gallery of the official Matplotlib website you can see many examples of all these graphs and some more along with the associated Python code to generate them. In this post, we have included a code cell with the creation of a simple scatter plot using Matplotlib. This example uses the same dataset introduced in the previous section.
Finally, it should be noted that there are other libraries oriented to the creation of graphs that use Matplotlib as a base. These libraries facilitate its use and extend Matplotlib to create good quality visualisations with as little intervention as possible. This is the case of the Seaborn library.
TensorFlow / Keras
We can define TensorFlow as a high-performance open-source library oriented to numerical computation. Underneath, it uses directed acyclic graphs (DAG) to represent these operations, which follow one after the other when performing complex processes.
Tensors are mathematical objects that act as a generalization of scalar numbers, vectors and matrices of different dimensions. They are the building block for representing the data in this library, a concept from which TensorFlow derives part of its name. This library was developed by Google and subsequently released as open source in 2015. At this time, it was widely adopted by industry and the research community due to the wide range of advantages it offers when tackling machine learning problems.
The use of graphs to represent the computations to be performed makes these operations completely independent of the underlying code, making them portable between different devices and environments. This makes it possible, for example, to develop a model in Python, store it in some intermediate format and then load it into a C++ program on another device to run it in a more optimised way. In this way, you can use virtually the same code to execute a set of operations using only the computer’s CPU, the graphics card (GPU) to accelerate calculations, or even multiple graphics cards together.
Using Keras with Tensorflow
All these advantages make TensorFlow a perfect platform for the development of machine learning models. Especially, for the construction and training of neural networks. This is where Keras, an API designed to work with TensorFlow, comes in. Keras offers intuitive high-level abstractions intuitive high-level abstractions that aim to greatly simplify the development of this type of algorithms, minimizing the number of user actions required for most common use cases. Keras is not only able to work and run on top of TensorFlow, but can also make use of other low-level libraries such as Theano or Microsoft Cognitive Toolkit.
The use of TensorFlow is not limited to the development of machine learning models. In addition, it allows all kinds of tasks to be carried out in relation to such development, such as the following:
- Data preparation, from data loading to pre-processing prior to model input.
- Evaluation and monitoring of model output in a precise and simple way.
- Running models on mobile devices and embedded systems with TensorFlow Lite.
- Deployment of models in production environments, helping to implement best practices for applying an MLOps methodology.
- Exploration and use of models previously trained by the community using TensorFlow Hub.
How to use TensorFlow and Keras to create neural networks
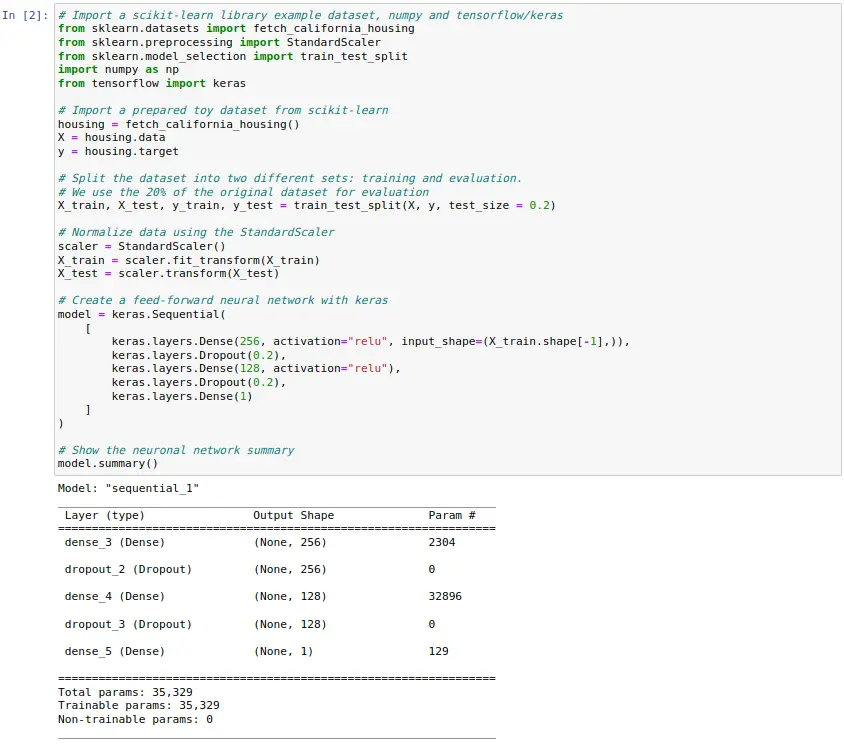
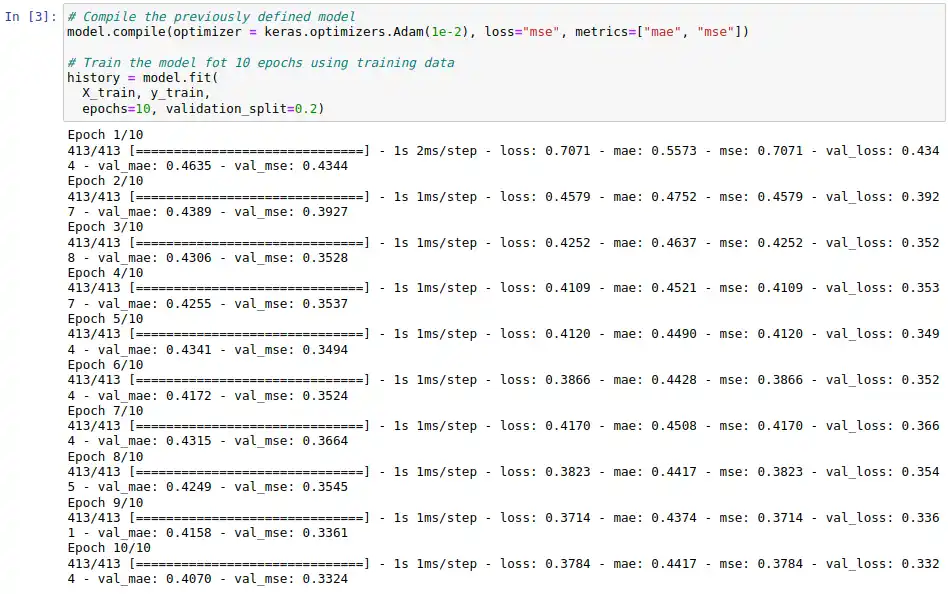
The following example shows a use case in which Keras is used with TensorFlow as a backend to define a neural network that is able to solve the same problem previously addressed using Scikit-learn. For this, first a simple multilayer neural network is defined. This neural network is trained using the data set already used for 10 epochs and then evaluated using a proprietary method provided by Keras.

Scipy
The last library we are going to describe in this post is Scipy. This open source library offers a large number of mathematical tools and algorithms to solve problems of optimization, interpolation, algebraic equations, differential equations or statistics, among others. It is built to work with NumPy arrays, offering a simple interface to tackle mathematical problems. This interface is free, powerful, easy to install, and can be used in the most common operating systems.
One of the great advantages of Scipy is its great speed. It uses highly optimized implementations written in low-level languages such as Fortran, C or C++. The great benefit of this feature is the flexibility that Python provides as a programming language without giving up the speed of execution of the compiled code necessary to perform this type of task. In addition, Scipy offers a high-level syntax that is easy to use and interpret. This makes it accessible and productive for both inexperienced programmers and professionals.
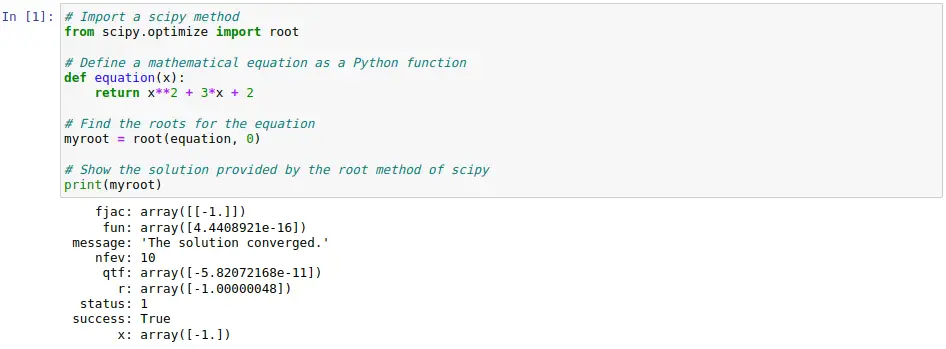
Example of how to use the Scipy library
The following code cell is intended to represent a simple use case of the Scipy library. In it, the aim is to find the roots for a second-degree mathematical equation. To do this, use is made of the root method provided by Scipy. This method can be used to obtain the roots for linear and non-linear equations.
Conclusion
Python is one of the programming languages of the moment, standing out among other reasons for the large number of libraries, frameworks and paradigms it offers. In this post we have reviewed in detail the functionalities provided by some of the most widely used Python libraries in the field of data processing, highlighting their practical applicability and showing some simple code examples to familiarize the reader with these tools.
If you liked the post, we encourage you to visit the Data Science category to see other articles similar to this one and to share it on social networks. See you soon!
