
La ciencia de datos es un área interdisciplinar que se encarga de extraer conocimiento e información útil de los datos. Y, dada la gran cantidad de datos que generan las empresas, es importante que los data scientists dispongan de herramientas que faciliten la manipulación, el análisis y la visualización de los mismos.
Entre estas tecnologías o herramientas se incluyen las librerías de código abierto, que son utilizadas para tratar los datos de forma eficiente y extraer todo su potencial.
¿Qué lenguajes de programación usa el Machine Learning?
Python, R, SQL y Scala son los lenguajes más populares en data science y cada uno de ellos cuenta con una serie de librerías o dependencias que aportan un valor diferente dentro del proceso de gestión, tratamiento y análisis de los datos.
A pesar de que R es el que, inicialmente, empezó a utilizarse de una forma más extensa entre los data scientists, es Python el que, por su gran versatilidad, alta eficiencia y la gran cantidad de recursos que ofrece, destaca actualmente entre los científicos de datos para desarrollar los algoritmos.
7 librerías de Python imprescindibles en ciencia de datos
Algunas de las librerías más populares en el ámbito de la ciencia de datos son Numpy, Pandas o Scikit-learn. A continuación, veremos cuáles son las que más se utilizan en data science y analizaremos para qué se usa cada una de ellas.
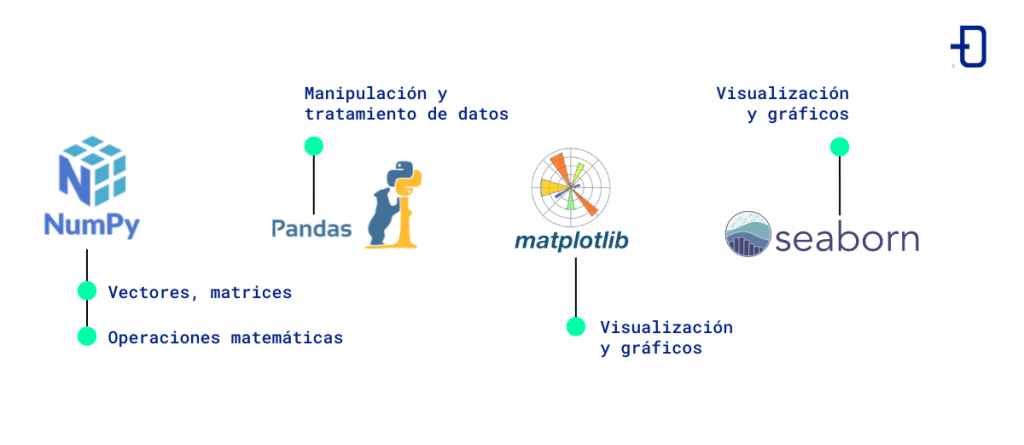
NumPy
NumPy es una librería de Python que ofrece una amplia gama de funciones matemáticas y que principalmente está diseñada para procesar y manipular grandes cantidades de datos numéricos.
Además, sirve de base para otras librerías de ciencia de datos de Python y con ella se pueden realizar operaciones matemáticas avanzadas como la resolución de sistemas de ecuaciones lineales, la generación de números aleatorios o la manipulación de arrays.
Pandas
Esta librería de análisis de datos en Python es considerada una de las más fáciles de utilizar y permite realizar múltiples tareas como la importación y exportación de los datos y la limpieza, manipulación y agrupación de los mismos ofreciendo un alto rendimiento.
Pandas se caracteriza por proporcionar estructuras de datos flexibles y potentes para su manejo y por su gran eficiencia.
Matplotlib
A la hora de visualizar los datos y presentar la información, Matplotlib es una de las opciones más completas que hay en Python ya que permite crear gráficos de gran calidad para las tareas de exploración de datos.
Matplotlib proporciona una amplia gama de opciones de visualización como por ejemplo gráficos de dispersión, de líneas o histogramas. Además, esta librería permite personalizar la apariencia de las visualizaciones y se puede integrar con otros marcos de trabajo de Python.
Seaborn
Seaborn es una librería de Python para la visualización de datos que se construye sobre Matplotlib y que se utiliza para crear gráficos estadísticos de alta calidad de forma muy sencilla gracias a una interfaz muy intuitiva.
Es compatible con Pandas y Numpy, por lo que tiene un uso muy extendido entre los desarrolladores y data scientists.
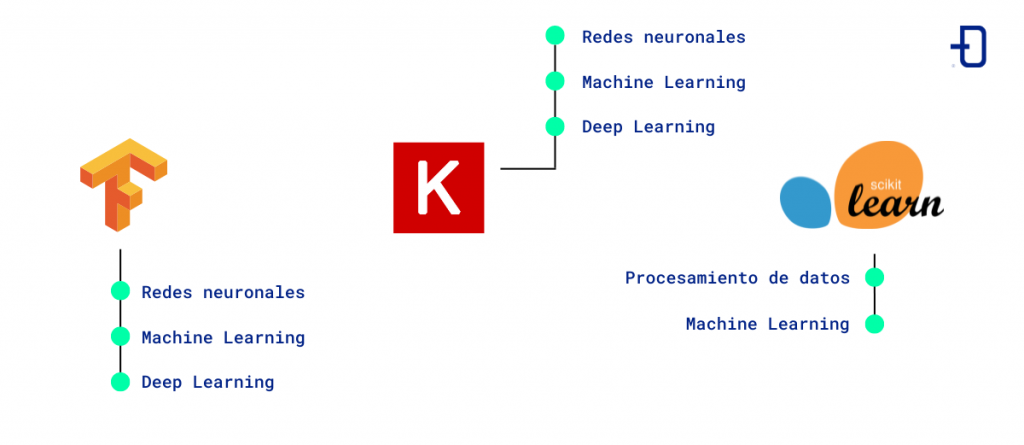
Tensorflow
Esta plataforma de código abierto desarrollada por Google se utiliza para desarrollar modelos de machine learning y deep learning y tiene una fácil integración con otras librerías de ciencia de datos.
Tensorflow es una de las librerías más utilizadas en el mundo y se encuentra respaldada por una gran comunidad de desarrolles y usuarios. Con ella se pueden elaborar modelos complejos y escalables que además se pueden entrenar en sistemas de CPU y GPU para dotar de más rapidez al proceso de entrenamiento.
Keras
Keras es una librería de Python de alto nivel para deep learning con la que se pueden construir y entrenar modelos de aprendizaje profundo de manera sencilla, rápida y eficiente.
Su compatibilidad con Tensorflow y su facilidad de uso la convierten en una opción muy popular y extendida entre los científicos de datos.
Scikit-learn
Otra de las librerías de Python para machine learning es Scikit-learn, que se utiliza en ciencia de datos para resolver problemas de clasificación, regresión y clustering.
Esta librería destaca por tener una gran cantidad de algoritmos y herramientas disponibles que son muy útiles y fáciles de usar incluso para principiantes en este campo.
Conclusión
Las dependencias y librerías de Python han cambiado la forma en la que los científicos e ingenieros de datos abordan los problemas de gestión y tratamiento de los mismos, siendo una herramienta imprescindible en un contexto en el que la demanda de análisis de cantidades masivas de información sigue en aumento.
El uso de librerías de Python en ciencia de datos ofrece a los profesionales una forma más eficiente de trabajar y de obtener resultados más rápido, mientras que permiten a las empresas ser más ágiles e inteligentes tomando decisiones basadas en datos.
Si estás interesado en conocer cómo se trabaja con estas librerías pero desde un punto de vista práctico, te recomendamos leer Machine Learning con Python: Ejemplos prácticos.
Si te ha parecido útil este post, te recomendamos visitar la categoría Data Sience y a compartirlo con tus contactos para que ellos también puedan leerlo y opinar. ¡Nos vemos en redes!
