
Data science is an interdisciplinary area that deals with extracting knowledge and useful information from data. Given the large amount of data generated by companies, it is important for data scientists to have tools that facilitate the manipulation, analysis and visualization of them.
Such technologies or tools include open source libraries, which are used to process data efficiently and extract its full potential.
What programming languages does Machine Learning use?
Python, R, SQL and Scala are the most popular languages in data science and each of them has a series of libraries or dependencies that provide a different value within the process of data management, processing and analysis.
Although R is the one that initially began to be used more extensively among data scientists, it is Python that, due to its great versatility, high efficiency and the large number of resources it offers, currently stands out among data scientists for developing algorithms.
7 top Python libraries for data science
Some of the most popular libraries in the field of data science are Numpy, Pandas or Scikit-learn. Next, we will see which ones are the most used in data science and we will analyze what each of them is used for.
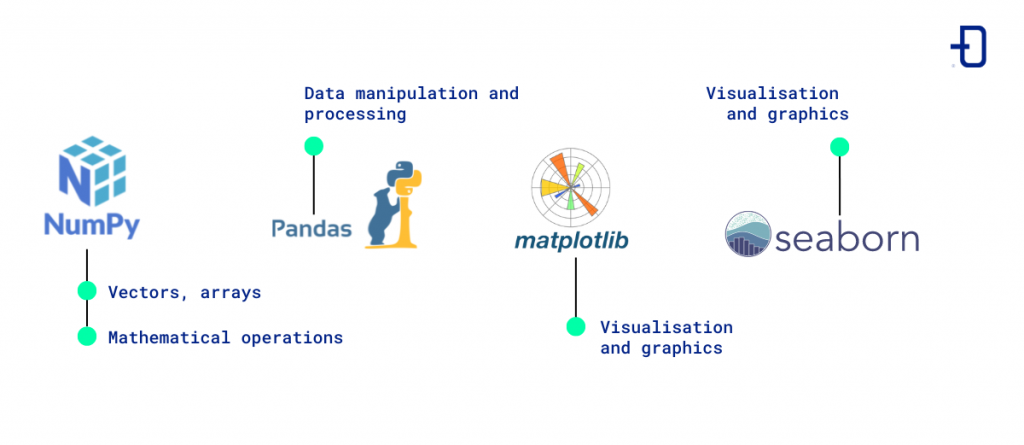
NumPy
NumPy is a Python library that offers a wide range of mathematical functions and is primarily designed to process and manipulate large amounts of numerical data.
It also serves as a basis for other Python data science libraries and can be used to perform advanced mathematical operations such as solving systems of linear equations, generating random numbers or manipulating arrays.
Pandas
This Python data analysis library is considered one of the easiest to use and allows multiple tasks such as importing and exporting data and cleaning, manipulating and grouping data, offering high performance.
Pandas is characterized by its flexible and powerful data structures and its high efficiency.
Matplotlib
When it comes to visualizing data and presenting information, Matplotlib is one of the most complete options available in Python, allowing you to create high quality graphs for data exploration tasks.
Matplotlib provides a wide range of visualization options such as scatter plots, line plots and histograms. In addition, this library allows you to customize the appearance of visualizations and can be integrated with other Python frameworks.
Seaborn
Seaborn is a Python library for data visualization that is built on top of Matplotlib and is used to create high quality statistical graphs in a very easy way thanks to a very intuitive interface.
It is compatible with Pandas and Numpy, so it is widely used by developers and data scientists.
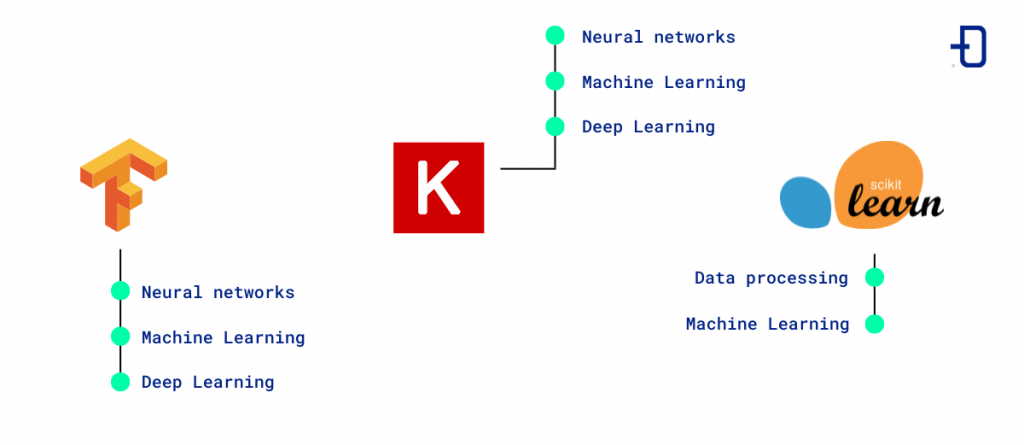
Tensorflow
This open source platform developed by Google is used to develop machine learning and deep learning models and is easily integrated with other data science libraries.
Tensorflow is one of the most widely used libraries in the world and is supported by a large community of developers and users. It can be used to build complex, scalable models that can be trained on CPU and GPU systems to speed up the training process.
Keras
Keras is a high-level Python library for deep learning that can be used to build and train deep learning models easily, quickly and efficiently.
Its compatibility with Tensorflow and its ease of use make it a popular and widespread choice among data scientists.
Scikit-learn
Another Python library for machine learning is Scikit-learn, which is used in data science to solve classification, regression and clustering problems.
This library stands out for having a large number of algorithms and tools available that are very useful and easy to use even for beginners in this field.
Conclusion
Python dependencies and libraries have changed the way data scientists and engineers approach data management and processing problems, and are an indispensable tool in a context where the demand for analysis of massive amounts of information continues to grow.
The use of Python libraries in data science offers professionals a more efficient way of working and getting results faster, while allowing companies to be more agile and intelligent in making data-driven decisions.
If you are interested in knowing how to work with these libraries but from a practical approach, we recommend you to read Machine Learning with Python: Practical examples.
If you found this post useful, we recommend you to visit the Data Sience category and to share it with your contacts so that they can also read it and give their opinion. See you in networks!
