
La deduplicación de datos es un problema que afecta a un gran número de organizaciones. Además de impactar negativamente en la operativa de negocio, puede llegar a afectar a los costes. En este artículo, analizaremos en qué consiste tomando un ejemplo del sector hotelero y qué arquitectura implementar en un proyecto de estas características.
¿Qué es la deduplicación de datos?
Aunque una compañía piense que conoce perfectamente a sus clientes, la realidad es que el mismo usuario puede aparecer múltiples veces en distintos sistemas internos. Es posible que quede almacenado con nombres ligeramente cambiados, teléfonos distintos, emails diferentes o direcciones incompletas. Este problema se conoce como fragmentación o deduplicación de datos.
La deduplicación de datos es una cuestión que afecta a multitud de sectores empresariales. Sin embargo, en el hotelero alcanza una complejidad especialmente elevada debido a la enorme cantidad de elementos implicados en la operación diaria. Entre ellos, sistemas PMS y CRM, motores de reservas, plataformas de encuestas, estructuras de call center, aplicaciones móviles y herramientas de marketing.
Cada uno de estos elementos genera continuamente registros independientes. El resultado es un ecosistema de datos altamente fragmentado donde un mismo huésped puede existir como varias personas distintas. Desde el punto de vista tecnológico, esto implica una pérdida masiva de calidad del dato. Por lo que respecta a negocio, también significa una merma directa de ingresos, eficiencia y capacidad de personalización.
Customer 360 o cliente único
La solución a este problema de deduplicación se conoce como Customer 360 o cliente único. Esta medida tiene por objetivo construir una ficha maestra en la que unificar toda la información dispersa de un cliente en una única identidad digital coherente. Para lograrlo, no basta con almacenar datos en una base de datos centralizada. El verdadero reto consiste en determinar cuándo dos registros aparentemente diferentes en realidad representan a la misma persona.
Muchas soluciones intentan resolver esta cuestión mediante reglas simples. Por ejemplo, considerando que dos registros son iguales si comparten el mismo email o documento de identidad. Sin embargo, en entornos más complejos esta práctica falla rápidamente. Esto se debe a que los clientes cambian de teléfono, utilizan emails distintos para trabajo y ocio, introducen errores tipográficos al reservar o un recepcionista puede escribir mal un apellido. Incluso entre diferentes países, se generan formatos incompatibles para direcciones, teléfonos o documentos.
Arquitectura de un proyecto de deduplicación
La arquitectura de deduplicación suele construirse sobre pipelines de datos en tiempo real. En ellos, en lugar de conectar directamente cada sistema origen con la lógica de deduplicación, se desacopla toda la ingesta utilizando plataformas de streaming como Apache Kafka.
Este enfoque permite que cualquier sistema publique registros de clientes en tiempo real. Además, no es necesario que el motor de deduplicación conozca el origen exacto del dato. De esta forma, la arquitectura se vuelve agnóstica a las fuentes de datos. Así, un nuevo PMS o integrar una nueva plataforma de reservas, deja de requerir cambios en la estructura y las ETLs.
A continuación, se muestra la arquitectura simplificada del proyecto:
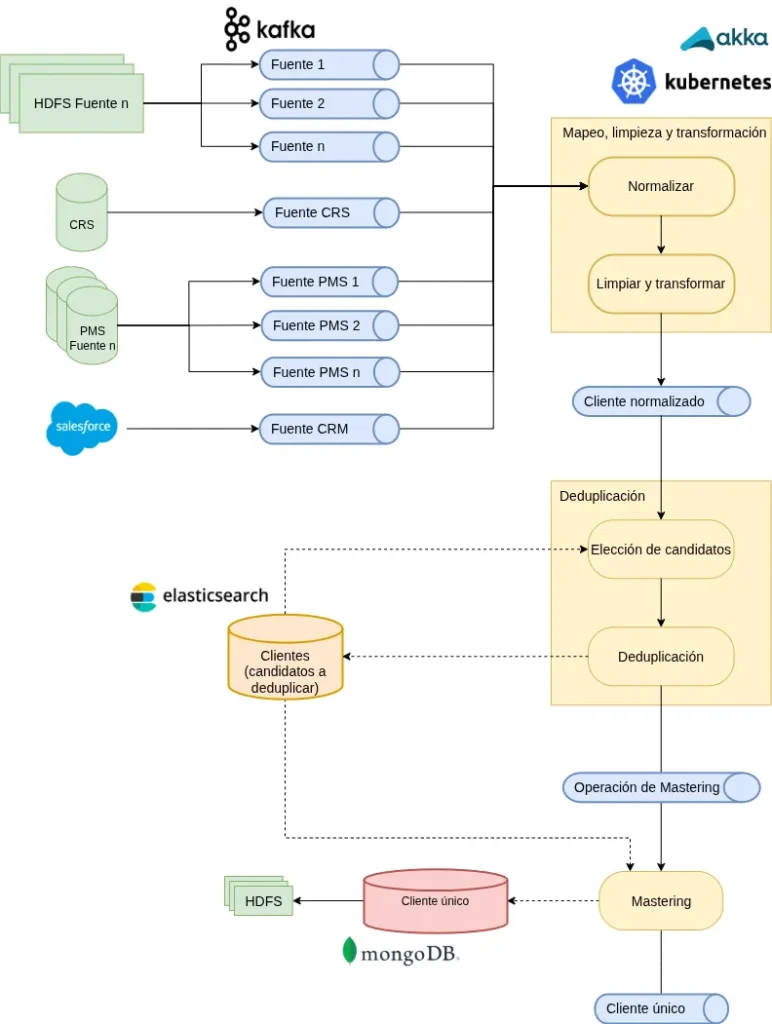
Normalización de datos
A nivel de procesamiento, el primer gran bloque es la normalización de datos. En este sentido, la calidad de la deduplicación depende directamente de la calidad del dato de entrada. Un email como «Juan.Martinez@GMAIL.Com» debe transformarse en un formato estándar. Igualmente, un teléfono como «0034-600-123-456» ha de convertirse a formato internacional homogéneo. Asimismo, una dirección como «Av. España Nº14» debe interpretarse igual que «Avenida España 14». Este proceso combina limpieza, estandarización, enriquecimiento y validación.
En nombres y apellidos suelen aplicarse otro tipo de técnicas. Entre ellas, la tokenización y eliminación de acentos y diccionarios semánticos para que el sistema pueda entender que «José», «Pepe» o «Josep» son variantes del mismo nombre. En teléfonos se utilizan librerías especializadas capaces de detectar países, prefijos y tipos de línea. Además, con ellas, es posible identificar si un número corresponde a móvil, fijo o, incluso, si tiene un formato inválido.
Búsqueda de candidatos
Una vez normalizados los datos, comienza el proceso de búsqueda de candidatos. Este paso es crítico porque determina el equilibrio entre precisión y escalabilidad. Al comparar cada nuevo cliente contra millones de registros existentes, podría ser computacionalmente inviable.
Por este motivo, los sistemas modernos utilizan técnicas de blocking inteligente que reducen drásticamente el espacio de búsqueda. Su objetivo principal es seleccionar únicamente un pequeño subconjunto de candidatos potencialmente similares. Este proceso se realiza con herramientas como Elasticsearch. Esta base de datos permite combinar fuzzy matching, indexación fonética, N-Grams y scoring probabilístico.
Por ejemplo, el apellido «Martínez» puede fragmentarse en múltiples subconjuntos textuales para detectar errores tipográficos parciales. Al mismo tiempo, algoritmos fonéticos pueden convertirlo en representaciones similares como «MRTNS». De esta forma, es posible encontrar coincidencias incluso cuando existen errores humanos. Las búsquedas híbridas combinan diferentes tipos de matching con distintos pesos de relevancia. Un email exacto puede tener un peso muy alto, mientras que una coincidencia parcial en un apellido puede aportar únicamente una puntuación moderada.
El sistema no decide todavía si dos registros son iguales, solo construye un conjunto reducido de candidatos plausibles. Esta reducción es la parte más importante desde el punto de vista económico y computacional. Un mal diseño en esta fase puede disparar exponencialmente los costes de infraestructura y el tiempo de procesamiento. La mayoría de proyectos no tienen en cuenta esta complejidad hasta que intentan ejecutar pipelines en tiempo real sobre decenas de millones de clientes.
Modelo de deduplicación
Después de localizar candidatos potencialmente similares, los datos pasan al modelo de deduplicación. Dicho modelo tiene por objetivo decidir si dos registros pertenecen o no al mismo cliente. Sin embargo, hay una gran complejidad matemática, semántica y de negocio para tomar esta decisión.
En los entornos reales, prácticamente nunca existen datos perfectos. Esto se debe a que los clientes introducen errores tipográficos, los empleados escriben nombres incompletos, algunos sistemas antiguos almacenan información corrupta y otros utilizan alfabetos distintos o formatos incompatibles. Por eso, el modelo de deduplicación combina reglas deterministas con algoritmos probabilísticos.
Existen múltiples casos de registros para deduplicar y cada uno de ellos tiene una complejidad distinta. Para empezar, los casos más sencillos son los duplicados exactos. Si dos registros tienen nombre, apellidos, documento y teléfono idénticos, el sistema puede fusionarlos con un alto nivel de confianza.
Algoritmos para la deduplicación
No obstante, los problemas reales empiezan cuando aparecen pequeñas diferencias. Por ejemplo, «Pepe Gómez», «Jose Gómez» y «Pepe Gome» podrían representar a la misma persona. Aunque también podrían ser usuarios totalmente distintos.
Fuzzy matching
En estos casos entra en juego el fuzzy matching. El fuzzy matching es una técnica que permite calcular la similitud entre dos cadenas de texto, incluso cuando existen algunas diferencias entre ellas. Un algoritmo muy utilizado para ello es la distancia de Levenshtein. Su misión es medir cuántas operaciones se necesitan para transformar una cadena en otra. Cuanto menor sea la distancia, mayor será la similitud.
Jaro-Winkler
Por otro lado, en nombres propios también suele usarse Jaro-Winkler. Se trata de un algoritmo especialmente diseñado para detectar pequeñas variaciones tipográficas. Su principal ventaja es la de penalizar menos los errores menores y dar más importancia a los prefijos comunes. Para direcciones o textos más largos, suelen emplearse métricas vectoriales como Cosine Similarity.
Sin embargo, ningún algoritmo individual es suficiente por sí solo. Son necesarios múltiples scores para determinar si dos registros son del mismo cliente. Es por ello que el modelo de deduplicación utiliza scoring compuesto. Cada atributo del cliente aporta una puntuación ponderada al resultado final. De esta forma, es posible construir modelos mucho más flexibles y adaptables al negocio.
Por ejemplo, un email idéntico puede tener más peso que una dirección similar. Un documento de identidad puede considerarse casi determinista. Un teléfono parcialmente coincidente puede aportar únicamente una evidencia moderada. El resultado final suele convertirse en un score probabilístico entre 0 y 1 y, a partir de ahí, se aplican umbrales de decisión. Por encima de cierto valor, el sistema realiza un match automático. Entre dos rangos intermedios puede enviar el caso a revisión manual y, por debajo del umbral mínimo, se descarta la coincidencia.
Si los umbrales son demasiado agresivos aparecerán falsos positivos. Igualmente, si son demasiado conservadores, aumentarán los falsos negativos.
Overmerging y duplicados parciales
Fusionar por error dos personas distintas puede provocar problemas operativos muy graves. Desde campañas de marketing incorrectas, errores en programas de fidelización e, incluso, incidencias legales relacionadas con privacidad de datos.
Un ejemplo clásico es el de un padre y un hijo con mismo nombre y apellido compartiendo teléfono y email familiar. A simple vista, parecen el mismo cliente. Sin embargo, unirlos incorrectamente genera un problema de overmerging. Por ello, el modelo de deduplicación debe incorporar reglas de penalización. Por ejemplo, fechas de nacimiento incompatibles, documentos diferentes o relaciones familiares detectadas pueden reducir drásticamente el score final.
Otro problema importante son los duplicados parciales. En muchos casos, ningún sistema individual contiene suficiente información para identificar al cliente. Un CRM puede tener nombre y email. Por su parte, un PMS puede tener nombre y teléfono y una encuesta post-estancia puede contener únicamente email. Al combinar todas las fuentes es posible obtener la identidad completa. Por tanto, la deduplicación es un problema de correlación distribuida. Cada nuevo dato no solo actualiza un cliente, sino que también mejora la capacidad de detectar nuevos duplicados relacionados.
En proyectos más avanzados se entrenan modelos de Machine Learning con algoritmos que permiten aprender patrones complejos a partir de históricos previamente etiquetados. Estos modelos aprenden representaciones vectoriales capaces de detectar relaciones semánticas entre registros aparentemente distintos. Sin embargo, el uso de inteligencia artificial introduce nuevos problemas:
- La explicabilidad disminuye considerablemente.
- Las decisiones dejan de ser totalmente deterministas.
- Entrenar estos modelos requiere datasets etiquetados de alta calidad.
No obstante, muchas veces se descubre rápidamente que la calidad del entrenamiento condiciona completamente el comportamiento del sistema. Por este motivo, el modelo de deduplicación suele combinar reglas deterministas con modelos probabilísticos en lugar de depender exclusivamente de IA.
Mastering de cliente
Una vez que el sistema determina que varios registros pertenecen a la misma persona, es necesario construir la ficha única de cliente. Este proceso se conoce como mastering.
El mastering es el componente encargado de fusionar múltiples versiones parciales de un cliente en una única ficha consolidada. Su objetivo no es únicamente unir registros. También debe decidir qué información conservar cuando existen datos contradictorios. Por ejemplo, un mismo cliente puede aparecer como «Pepe», «Jose» o «Josep» en distintas fuentes. Además, puede tener varios teléfonos, diferentes emails y múltiples direcciones históricas.
Estrategias de mastering
La pregunta ya no es si los registros pertenecen al mismo cliente. Ahora, la cuestión es qué versión debe considerarse la correcta. Para resolver este problema, el mastering utiliza distintas estrategias de resolución dependiendo del tipo de dato. Una de las más habituales es la priorización por fuente.
Por ejemplo, un CRM suele tener información más controlada que un PMS cuyos datos son introducidos manualmente por recepción. Un call center puede ser especialmente fiable para validar teléfonos. Una plataforma de marketing puede contener emails más actualizados.
Otra estrategia muy utilizada es seleccionar el valor más repetido. Si un mismo email aparece en múltiples sistemas, aumenta la probabilidad de que sea el correcto. También suele utilizarse el criterio del dato más reciente. Dicho criterio resulta muy útil para direcciones o teléfonos porque los clientes pueden cambiar esta información con el paso de los años.
En otros casos se prioriza el valor más completo en el que una dirección con calle, ciudad y código postal aporta mucho más contexto que una dirección parcial sin información geográfica adicional.
La solución debe adaptarse específicamente a cada atributo. Por ejemplo:
- Los nombres suelen resolverse utilizando frecuencia, longitud y fiabilidad de fuente.
- Los emails y teléfonos normalmente se almacenan como colecciones múltiples clasificadas por tipología. Así, es posible distinguir entre emails personales, laborales o secundarios.
Almacenamiento NoSQL
El resultado final suele almacenarse en bases de datos NoSQL como MongoDB. Este tipo de almacenamiento permite crear estructuras flexibles y representar información heterogénea y evolutiva. Al mismo tiempo, los eventos actualizados del cliente único pueden emitirse nuevamente en tiempo real mediante Apache Kafka. Así, se hace posible que una empresa procese los datos en vivo a través de los diferentes departamentos.
Desde el punto de vista de negocio, aquí realmente aparece el retorno de inversión del proyecto. Esto se debe a que un cliente único bien construido impacta directamente en marketing, revenue, operaciones y experiencia de cliente. Además, la segmentación de clientes se vuelve mucho más precisa porque ya no se trabaja con registros duplicados o inconsistentes. Por lo tanto, los departamentos de una empresa pueden construir perfiles reales de comportamiento más precisos.
Asimismo, es posible identificar clientes frecuentes, huéspedes premium, perfiles familiares o usuarios con alta probabilidad de repetición. Además, un recepcionista puede visualizar preferencias históricas, idioma habitual, tipo de habitación preferida, incidencias anteriores, etc. Todo ello, independientemente del canal que haya usado el cliente para hacer la reserva.
La integración con encuestas post-estancia abre también nuevas posibilidades. El hecho de relacionar NPS, satisfacción y comportamiento económico permite detectar señales críticas mucho antes. Un cliente de alto valor que empieza a mostrar malas valoraciones puede convertirse en una alerta prioritaria para negocio.
Ventajas de la arquitectura de deduplicación
Desde la perspectiva técnica, uno de los grandes beneficios de estas arquitecturas es su flexibilidad operativa. Gracias a ella, es posible convertir la plataforma de cliente único en un hub central de identidad empresarial:
- Distintos departamentos pueden consumir los datos de formas diferentes dependiendo de sus necesidades.
- Los sistemas en tiempo real pueden leer directamente eventos de streaming.
- Los entornos analíticos pueden consumir snapshots diarios desde almacenamiento distribuido como Apache Hadoop.
- Otros equipos pueden acceder directamente a bases documentales o motores de búsqueda.
Sin embargo, mantener este ecosistema requiere monitorización continua. En este sentido, los KPIs técnicos son fundamentales. Por ejemplo, precision, recall, false positive rate o match rate permiten medir objetivamente la calidad del sistema de deduplicación. La latencia también se vuelve crítica en arquitecturas real time. Eso se debe a que el sistema debe hacerlo en milisegundos si quiere integrarse con procesos operacionales en vivo.
Los indicadores de negocio también son sumamente necesarios. Por ejemplo, la reducción de clientes duplicados, la mejora del NPS, el incremento de campañas efectivas o el aumento del revenue por huésped son las métricas que realmente justifican la inversión del proyecto.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Science para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
