
En ocasiones, a la hora de analizar el comportamiento de un sistema, es habitual encontrarse algún tipo de problema o dificultad. Por ejemplo, queremos mejorar el estado de un proceso, desde distribuir mejor las cargas hasta evitar largas esperas, o aumentar su rendimiento. Sin embargo, es extremadamente difícil saber si el cambio que estamos aplicando nos acercará o alejará de los objetivos que esperamos conseguir.
Imaginemos que nuestra misión es aumentar los beneficios obtenidos en un centro de ocio gracias a los visitantes que acuden a él. Entre otras cosas, podríamos considerar reducir el precio, pero también aumentarlo. ¿Cuál de estas dos opciones incrementaría los ingresos totales?
Quizás, al bajar precios, se multiplicaría tanto el tráfico de visitantes que aumentaría el beneficio. Sin embargo, si subiera el precio, puede que el tráfico no baje demasiado, con lo cual también habría incremento de los ingresos. Por el contrario, quizás bajando precios los costes de mantenimiento suben tanto que perderíamos dinero. O podría ocurrir que una subida de precios se tradujera en una pérdida considerable de tráfico, afectando negativamente a los ingresos.
Entonces, tenemos un dilema. ¿Cómo podemos decidir cuál sería la solución para conseguir nuestro objetivo? Otra opción sería la de aplicar tests A/B sobre partes de nuestro sistema. Así, podríamos obtener información sobre el efecto que producen los cambios aplicados. Sin embargo, esta tarea a veces no es del todo práctica o, incluso, se torna imposible. En estos casos, es común realizar simulaciones.
¿Qué son las simulaciones?
Una simulación es una representación de un sistema real. No obstante, siempre hay que tener en cuenta que toda simulación es errónea. Esto se debe a que la realidad es imposible de representar en un modelo simplificado. Por eso, es necesario tomar decisiones sobre qué elementos de la realidad queremos simular, cuáles simplificamos o qué asunciones tomaremos.
Teniendo esto en cuenta, procederemos a introducir una de las herramientas más simples que se usan para realizar simulaciones, la cadena de Markov.
¿Qué es una cadena de Markov?
Una cadena de Markov es un proceso que nos permite modelar la probabilidad de transicionar entre diferentes estados. Por ejemplo, si un cliente está en una sección concreta del supermercado, existe cierta posibilidad de que visite las siguientes.
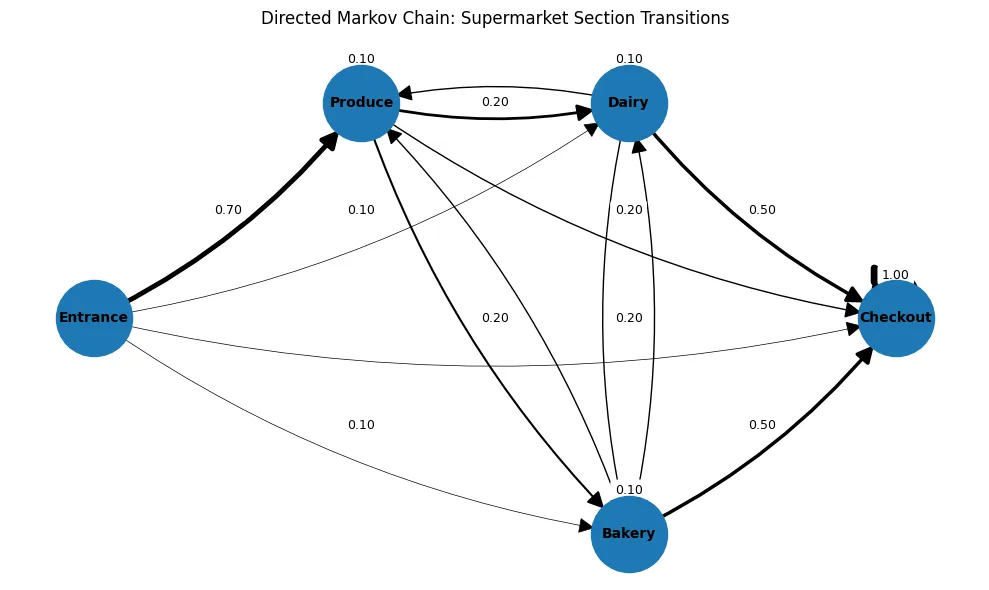
Este tipo de modelos posee una asunción clave, que el tiempo no afecta a la transición. Es decir, si previamente el cliente ha estado en la sección “Dairy”, no afecta si 3 transiciones antes estaba en “Produce”. Solamente importa el momento actual.
Un modelo así es extremadamente simplificado. Es evidente que, en la realidad, el pasado afecta a las decisiones actuales. Entonces, ¿por qué puede ser útil un modelo tan simplificado?
Como mencionamos antes, todo modelo es presumiblemente erróneo. La realidad es demasiado compleja y capturar todas esas complejidades es una tarea imposible. Sin embargo, para entender mejor un sistema no es necesario atrapar toda su diversidad. En este sentido, las cadenas de Markov son una herramienta extremadamente sencilla que nos ayuda a entender el sistema mucho mejor respecto a su coste de implementación.
Ejemplo cadena de Markov
Para ilustrar el uso de este modelo, crearemos un escenario artificial. Tenemos una web y queremos aumentar la cantidad de tráfico que llega a la página de “Signup”, ya que tenemos la teoría de que otras páginas absorben demasiado tráfico.
En primer lugar, hemos registrado cómo diferentes usuarios se mueven por la página web. De esta forma, y para cada sección de la página web, obtenemos a dónde saltó el usuario a continuación. Por ejemplo, ha navegado desde “Home” a “Features”.
Obtener la cadena de Markov representativa de nuestros datos es muy simple. Basta con agregar todas las transiciones iguales y dividir después por la ocurrencia total del estado.
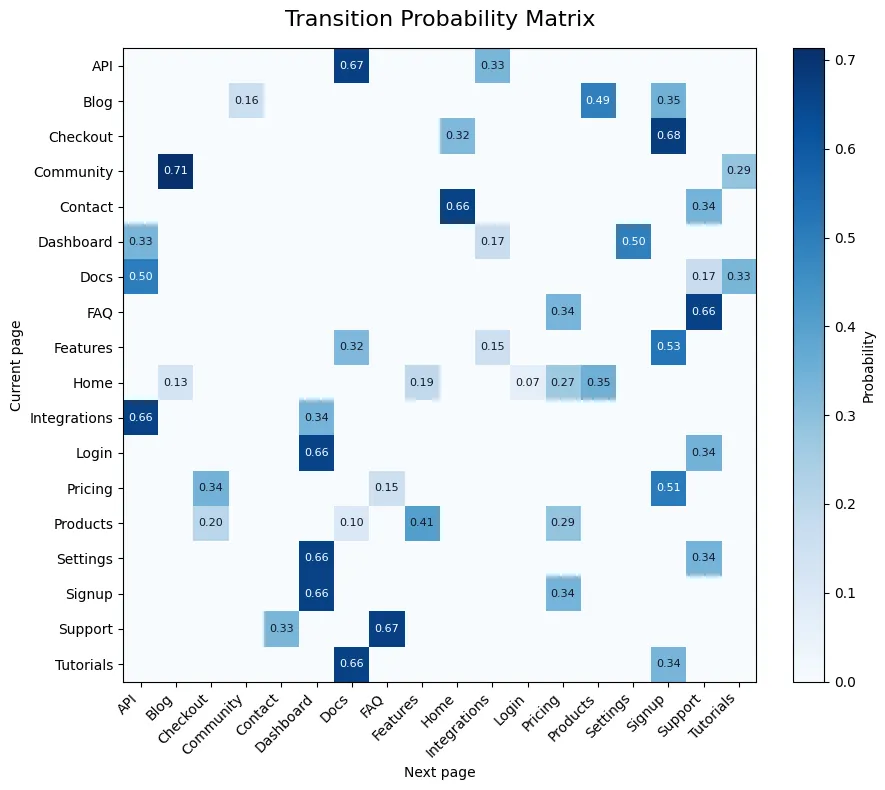
Entendiendo el comportamiento de los usuarios
Ahora, ya tenemos una representación simplificada del comportamiento de los usuarios. En ella, podemos observar qué páginas generan tráfico a otras páginas. Por ejemplo, vemos que la página “Tutorials” lleva a “Signup” con un 34% de probabilidad, similar a la de “Blog” con un 35%.
Si usamos el modelo como es ahora, podemos replicar varias de las posibles rutas que un usuario tomó hasta llegar a “Signup”.
Home -> Features -> Docs -> Tutorials -> Signup
Home -> Pricing -> Signup
Home -> Login -> Dashboard -> Settings -> Support -> Contact -> Home -> Pricing -> Checkout -> Signup
Home -> Pricing -> Signup
Home -> Products -> Pricing -> Signup
Home -> Blog -> Signup
Home -> Products -> Docs -> Support -> FAQ -> Support -> FAQ -> Pricing -> Checkout -> Signup
Home -> Pricing -> Checkout -> Signup
Home -> Blog -> Signup
Home -> Features -> Docs -> API -> Docs -> Support -> FAQ -> Pricing -> Signup
Home -> Products -> Features -> Docs -> Tutorials -> SignupEl problema es que ahora solo estamos imitando la realidad y esto no nos aporta mucha información más que la representación de algo que ya existe. Sin embargo, podemos simular diferentes escenarios usando el modelo obtenido, alterando la representación del estado del sistema. Por ejemplo, vamos a simular el escenario más básico, quitar ciertos enlaces a otras páginas.
Simulación de un cambio en el sistema
Para este ejemplo, decidimos que el Blog requiere demasiada inversión para lo que se considera un retorno bajo en la cantidad de usuarios que visitan “Signup”. Por lo tanto, decidimos simular el efecto de quitar “Blog” del modelo.
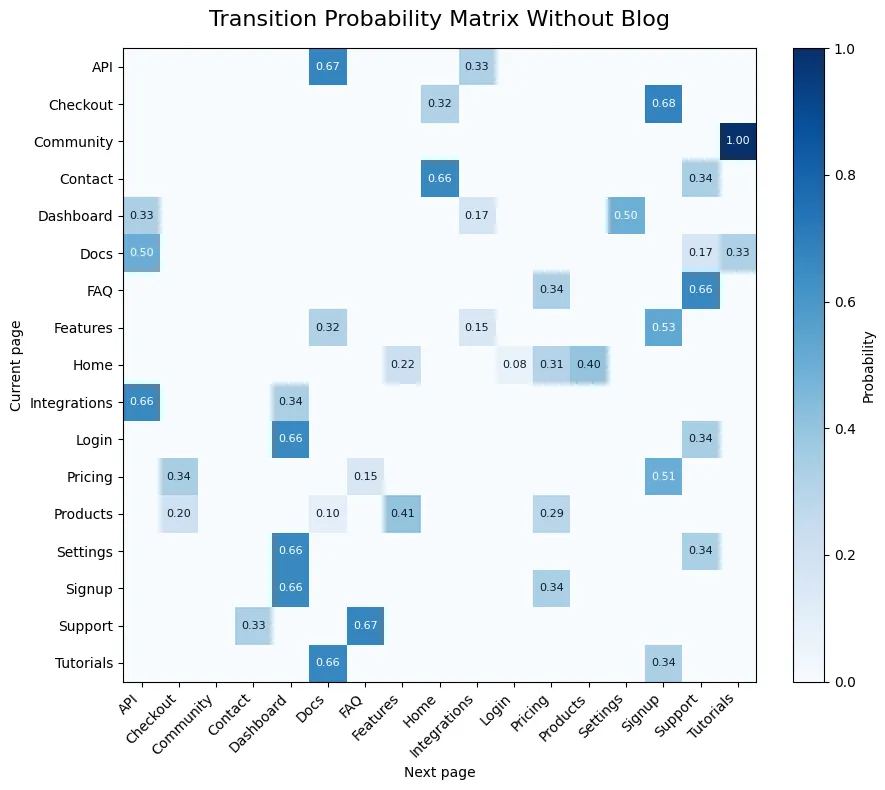
Para medir el efecto, haremos una simulación simple. Vamos a obtener 10.00 simulaciones de los caminos que un usuario seguiría hasta llegar a la página de “Signup” y mediremos la distancia media y su varianza. De esta forma, conseguiremos una representación primitiva del efecto que este cambio tendría.
| Saltos medios | Desviación estándar | |
| Con Blog | 6.65 | 3.98 |
| Sin Blog | 6.69 | 4.02 |
Observando los resultados, vemos que quitar “Blog” no tendría el efecto deseado debido a la alta desviación estándar. Aunque, por otra parte, tampoco parece que tendría un impacto negativo.
De esta manera, tenemos una aproximación rápida (aunque no muy precisa) del efecto de cambios en un sistema. Así, conseguimos un primer acercamiento a cómo se comportaría ante una variación sin necesidad de costosas pruebas. Obviamente, este proceso no reemplaza a un testeo propiamente dicho, pero puede ser un primer paso para justificar pruebas más detalladas.
Conclusión
En este post, hemos visto una introducción al concepto de simulación. Además, hemos analizado uno de los muchísimos modelos que podemos usar para realizarla, la cadena de Markov.
Por otro lado, hemos comprobado cómo este modelo se puede emplear para simular el comportamiento de un sistema y cómo nos ayuda a entender si ciertas decisiones pueden modificar el sistema hacia un objetivo deseado.
Si te ha parecido útil este post, te animamos a ver otros artículos de la categoría Algoritmos en nuestro blog y visitar la web de Damavis para conocer los servicios que ofrecemos.
