
Durante años, Airflow se ha usado como un planificador que permite ejecutar tareas en momentos concretos del tiempo. Esto se hacía mediante expresiones cron que marcaban un momento exacto en el tiempo en el que debía suceder un acontecimiento.
Este enfoque está muy bien para procesos de batch clásicos. Si queremos hacer cargas de dimensiones por la noche, refrescar o cargar tablas periódicamente, este método es útil e incluso recomendable. Sin embargo, a medida que las arquitecturas evolucionan y las pipelines se vuelven más complejas, hay que aplicar diferentes sistemas de schedulers que se adapten mejor a las necesidades actuales.
En la mayoría de sistemas, la ejecución de una pipeline no solo tiene que ver con una hora. Depende de diferentes factores, como por ejemplo la llegada de nuevos datos o la finalización de otra pipeline.
Con los sistemas clásicos de scheduling basados en cron para gestionar este tipo de pipelines, pueden generarse cuellos de botella. Además, pueden darse patrones poco elegantes que acumulan fallos o retrasos y basan todo su funcionamiento en sensores perpetuos que crean dependencias frágiles y poco eficientes.
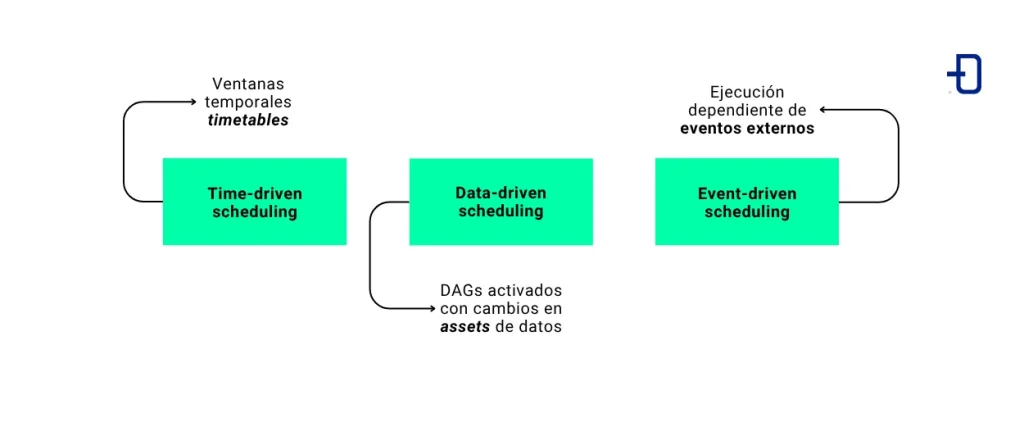
Por esa razón, Airflow 3 ha dado una vuelta de tuerca a la manera en la que funcionan los schedulers. En esta versión, se ha estructurado todo alrededor de tres conceptos diferentes:
- Time-driven scheduling. Está basado en ventanas temporales mediante timetables.
- Data-driven scheduling. Aquí, los DAGs se activan cuando cambia un asset de datos.
- Event-driven scheduling. La ejecución responde a eventos externos como la modificación en un fichero.
Con esto en mente, exploraremos cómo funciona el scheduling en Airflow 3 y cuáles son sus principales mecanismos. Además, analizaremos diferentes ejemplos y veremos cuándo es más recomendable usar uno u otro.
Qué es un scheduler en Airflow
Dado que hablaremos bastante de schedulers, lo primero es definir qué son y para qué se utilizan. Un scheduler en Airflow es un componente encargado de decidir cuándo debe iniciarse una nueva ejecución de los DAGs disponibles en el sistema.
Es importante entender que el scheduler no ejecuta las tasks directamente. Su función es decidir cuándo se ejecutan y enviarlas al sistema de ejecución correspondiente para que los workers las procesen. Por tanto, se encargan de establecer el momento de inicio del DAG y permitir que las tasks establecidas se ejecuten.
Cómo funciona el scheduling en Airflow 3
Para hacerlo, el scheduler funciona en un bucle continuo. Analiza los DAGs y comprueba si debe iniciar una ejecución. En caso de darse las características especificadas (ya sea por tiempo u otra casuística), genera la nueva instancia de ejecución (o lo que es lo mismo, un nuevo DagRun).
Un DagRun es una instancia concreta de una ejecución de un DAG y contiene toda la información para su ejecución. Esto es clave, porque cada DagRun está asociado a un intervalo de tiempo determinado o data interval. Este intervalo representa el rango de datos que debe procesar ese DagRun. Así, se puede establecer qué datos se deben procesar y en qué momento del tiempo, sin importar si la fecha en cuestión es el actual o no. Por ejemplo, un DAG que se ejecuta el lunes puede estar procesando datos del domingo o del lunes de la semana anterior.
Esto es muy importante porque otorga una flexibilidad increíble a la herramienta. Controlando este parámetro, se puede procesar cualquier instante presente, pasado o, en algunos casos, futuro.
Timetables y DagRun
Por otro lado, el elemento encargado de definir cuándo debe crearse un nuevo DagRun es el Timetable. Los timetables determinan tanto el momento en el que debe iniciarse una nueva ejecución como el intervalo de datos asociado a la misma. En otras palabras, el timetable define la lógica que utiliza Airflow para calcular la siguiente ejecución de un DAG.
Sin embargo, y aquí está la clave, Airflow permite crear ejecuciones en respuesta a otros eventos que no son únicamente temporales. Además, posibilita que un DagRun se inicie cuando cambia un dataset, cuando otro proceso finaliza o cuando ocurre un evento externo dentro del sistema. Y esto, una vez más, proporciona gran flexibilidad.
Ya hemos visto el papel que juegan los schedulers y tenemos claro qué son los DagRun y los Timetable. A continuación, pasaremos al siguiente punto, el scheduling basado en tiempo mediante timetables.
Timetables scheduling en Airflow
Un timetable define la lógica que utiliza Airflow para determinar cuándo debe iniciarse un nuevo DagRun y qué intervalo de datos procesar. Dicho esto, lo primero que se nos viene a la cabeza es establecer un momento temporal mediante un cron. Aunque lo cierto es que esto va mucho más allá de, únicamente, determinar una hora y un día concreto. Un timetable no solo define cuándo se ejecuta un DAG, sino también el intervalo de datos que se va a procesar en esa ejecución.
Mediante un cron, podemos establecer ejecuciones periódicas a lo largo del tiempo. Esto, como hemos comentado, es especialmente representativo. Cada DagRun se asocia a un intervalo de datos concreto (conocido como data interval) y está delimitado por data_interval_start y data_interval_end.
Ejemplo de timetable scheduling
Esto puede no ser evidente a primera vista, pero en el fondo es muy potente. Veamos con un caso de uso cómo funciona. Por ejemplo, vamos a configurar un DAG para ejecutarse todos los días a las 08:00 mediante una expresión cron.
schedule = '0 8 * * *'Haciendo esto, lo que realmente ocurre es que en ese momento se crea un DagRun encargado de procesar los datos del intervalo anterior. Es decir, la ejecución del 20 de marzo a las 00:00 procesará los datos comprendidos entre el inicio del día 19 y el del 20. Por tanto, 19-03-2026 00:00:00 sería el data_interval_start y 20-03-2026 00:00:00 el data_interval_end.
De esta forma, Airflow es capaz de separar completamente el momento en el que se inicia el DAG de los datos que está procesando. Esto es especialmente útil cuando se realizan pipelines en batch, ya que los datos se organizan en ventanas perfectamente definidas.
Sin embargo, a pesar de sus ventajas, este enfoque no siempre es el más adecuado. En muchos casos, un DAG depende de que otro proceso haya finalizado previamente, pues necesita los datos que éste genera. En estas situaciones, una solución habitual es usar sensores que apunten a otros DAGs. Esto puede dar lugar a flujos más complejos, dependencias frágiles y una arquitectura difícil de mantener.
Para abordar este problema, Airflow proporciona otros modelos de scheduling más adecuados y que veremos a continuación.
Asset-aware scheduling en Airflow
El asset-aware scheduling cambia la manera en que se ejecutan los DAGs. En primer lugar, la ejecución deja de estar centrada únicamente en el momento de ejecución para pasar a depender de los estados en los que se encuentren otros DAGs en el sistema. Es decir, con este modelo se pueden configurar los DAGs para que se ejecuten cuando un asset ha sido actualizado. Esta posibilidad es especialmente interesante en pipelines donde la disponibilidad de los datos es un punto crítico.
Qué son los assets
Antes de nada, es importante especificar lo que representa un asset. Un asset puede ser una tabla en BigQuery, una carpeta en GCS o cualquier otro recurso que se considere un conjunto de datos. Lo importante a tener en cuenta es que un asset no es una ubicación en sí misma, sino una representación de cómo ese dato se integra dentro del flujo de datos.
Esto es relevante porque un DAG puede actuar como productor de un asset dando lugar a que, tras la ejecución de una tarea, se ejecute automáticamente otro DAG que estaba configurado para ello. De esta forma, se crea una dependencia directa basada en los datos en lugar de una basada en tiempo.
Gracias a esto, podemos eliminar la necesidad de utilizar sensores para coordinar los DAGs entre sí. Así, dejaremos las dependencias temporales frágiles para empezar a reaccionar a eventos como la actualización de datos.
Ejemplo de asset-aware scheduling
Un ejemplo podría ser una carga de dimensiones en un data warehouse ejecutado por un DAG, que obligatoriamente ha de preceder a un proceso de transformación pues los datos deben de estar actualizados antes de este punto. Mediante asset-aware scheduling podemos configurar el DAG que ejecuta la transformación para que solo se ejecute una vez que la carga de dimensiones haya finalizado y, por tanto, estén actualizadas. Así, aportamos consistencia al proceso y nos aseguramos de que los datos finales obtenidos se han generado con las fuentes actualizadas.
Para entender mejor este comportamiento, veamos un ejemplo práctico. Por un lado, este sería el DAG productor, que marcaría el asset como actualizado para que los DAGs consumidores puedan ejecutarse.
master_ingestion_ready = Dataset("master_ingestion_ready")
def run_ingestion():
print("Master ingestion completed")
dag = DAG(
dag_id="producer_dag_1",
start_date=pendulum.datetime(2026, 1, 1, tz="UTC"),
schedule=None,
catchup=False,
)
produce_asset = PythonOperator(
task_id="run_ingestion",
python_callable=run_ingestion,
outlets=[master_ingestion_ready],
dag=dag,
)Por otro lado, el DAG consumidor sería el siguiente.
master_ingestion_ready = Dataset("master_ingestion_ready")
def run_transformation():
print("Transformation started after ingestion")
dag = DAG(
dag_id="consumer_dag_2",
start_date=pendulum.datetime(2026, 1, 1, tz="UTC"),
schedule=[master_ingestion_ready],
catchup=False,
)
consume_asset = PythonOperator(
task_id="run_transformation",
python_callable=run_transformation,
dag=dag,
)Como se puede ver, el primer DAG actúa como productor del asset indicando que los datos han sido actualizados tras su ejecución. Por otro lado, el segundo DAG está configurado para ejecutarse cuando ese asset cambia. Esto permite establecer una dependencia directa basada en los datos sin necesidad de utilizar sensores.
Por último, es importante destacar que, a pesar de que esta estrategia tiene muchas bondades en comparación con el Timetable scheduling, en algunos casos puede ser necesario combinar este enfoque con ejecuciones periódicas para garantizar la consistencia o cubrir ciertas situaciones en las que no se produzcan actualizaciones. Para ello, Airflow proporciona otros mecanismos como el que veremos a continuación.
Qué es y cómo funciona AssetOrTimeSchedule en Airflow
El AssetOrTimeSchedule se caracteriza por ser un modelo híbrido entre el timetable scheduling y el asset-aware scheduling. Esto se debe a que, gracias a él, un DAG puede ejecutarse cuando se actualiza un asset o cuando se cumple una condición temporal.
Este tipo de scheduling es especialmente útil si lo que se busca es que el pipeline se ejecute en cualquier circunstancia. Ya sea porque se han actualizado los datos o porque se ha alcanzado un momento concreto en el tiempo. De esta manera, evitamos que se queden datos sin procesar en aquellos casos en los que no se produzcan actualizaciones durante un periodo determinado.
En la práctica, esto significa que, gracias a AssetOrTimeSchedule, un DAG puede ejecutarse cuando un asset se ha actualizado. Sin embargo, también puede hacerlo de manera automática llegado un momento temporal. Así, asegura la consistencia de los datos y evita posibles lapsos de tiempo en los que falta información.
Un ejemplo de uso de AssetOrTimeSchedule sería el siguiente.
master_table_ready = Dataset("master_table_ready")
def run_reporting():
print("Reporting pipeline started")
dag = DAG(
dag_id="reporting_dag",
start_date=pendulum.datetime(2026, 1, 1, tz="UTC"),
schedule=AssetOrTimeSchedule(
timetable=CronTriggerTimetable("0 8 * * *", timezone="UTC"),
assets=[master_table_ready]
),
catchup=False,
)
run_report = PythonOperator(
task_id="run_reporting",
python_callable=run_reporting,
dag=dag,
)En este caso, el DAG se ejecutará en dos situaciones distintas. O bien cuando el asset de master_table_ready se haya actualizado o bien cuando llegue la ejecución programada por timetable a las 8:00. De esta forma, nos aseguramos de que, en cualquier caso, se ejecuta la pipeline.
Por lo tanto, AssetOrTimeSchedule, más que proporcionar un nuevo sistema de activación ofrece una especie de mecanismo de seguridad extra al asset-aware scheduling. Esto permite diseñar pipelines mucho más resistentes a fallos y adaptados a diferentes escenarios de procesamiento.
Event-driven scheduling en Airflow 3
Por último, veremos un nuevo método que se ha introducido en Airflow 3, el Event-driven scheduling. Su principal virtud es que proporciona un nuevo modelo de ejecución en el que se deja de depender tanto del tiempo o disponibilidad de los datos. En este caso, pasa a activarse cuando ocurren una serie de eventos externos.
Gracias a él, Airflow permite construir pipelines mucho más reactivos que hasta la fecha. Ahora, ya son capaces de responder a situaciones en el momento en el que ocurren los eventos.
Qué son los eventos de Airflow
No obstante, es importante definir qué es un evento. Un evento puede ser cualquier señal que indique que debe iniciarse un proceso. Por ejemplo, la llegada de ciertos ficheros a GCS, una modificación en un manifiesto o la aparición de un nuevo elemento en un sistema de colas, entre otros.
Como se puede observar, existe una gran variedad de elementos que pueden activar una pipeline. Gracias al event-driven scheduling, en lugar de comprobar periódicamente si se cumplen unas determinadas condiciones, el DAG reacciona a cuando uno de estos eventos ocurre.
Para que esto sea posible, Airflow ha introducido una arquitectura basada en triggers. En ella, es posible gestionar eventos evitando que las tareas tengan que estar ejecutándose constantemente mientras esperan a que se cumpla una condición.
Deferrable operators
Para comprender bien este apartado, es importante conocer los deferrable operators. Los sensores que hasta ahora estaban implementados en Airflow, hacían un pull continuo para asegurarse de si se había cumplido la condición especificada. En cambio, estos operadores pueden pausar su ejecución y esperar a que el trigger les especifique que deben ejecutarse. Una vez que esto ocurre, el proceso se reanuda y se ejecuta la tarea.
Esto es especialmente útil en caso de que los recursos del sistema sean limitados. Se pasa de tener un sensor haciendo pull continuamente, esperando que se cumpla una condición dada, a tener un sistema de trigger que solo se ejecuta una vez ocurre el evento.
Ejemplo de event-driven scheduling con Kafka
Para mostrar el uso tan diverso que se le puede dar a este nuevo modelo de ejecución, veremos dos ejemplos. Primero, mostraremos cómo utilizarlo para lanzar el DAG cuando ocurra un evento concreto (como la llegada de datos a una cola de Kafka). En el segundo, analizaremos cómo se puede usar aplicado a una tarea concreta.
En primer lugar, veremos cómo se implementaría el DAG para que permanezca escuchando un flujo de eventos externo a través de los nuevos Asset Watchers. Esto permite que, en lugar de depender de procesos por lotes, los flujos se definan como Assets. Al asociarles un watcher, delegan en el scheduler la tarea de hacer triggers en segundo plano.
De este modo, el DAG ya no depende del tiempo en el que se deba ejecutar. Ahora, permanece inactivo y sin consumir recursos, esperando a que se produzca el evento que lanzará la ejecución.
Un ejemplo de una estructura que espera a que ocurra un evento de Kafka sería la siguiente:
trigger = MessageQueueTrigger(
queue="kafka://localhost:9092/airflow_example_topic",
apply_function="include.kafka_trigger.apply_function",
)
kafka_topic_asset = Asset("kafka_topic_asset",
watchers=[AssetWatcher(name="kafka_watcher", trigger=trigger)]
)
dag = DAG(
dag_id="kafka_event_driven",
start_date=pendulum.datetime(2026, 1, 1, tz="UTC"),
schedule=[kafka_topic_asset],
catchup=False,
)
load_to_bq = GCSToBigQueryOperator(
task_id="load_to_bq",
bucket="data-bucket",
source_objects=["incoming/master_data.csv"],
destination_project_dataset_table="project_id.datawarehouse.master_data",
source_format="csv",
dag=dag,
)Como se puede observar en este ejemplo, el DAG no necesita un mecanismo interno de espera. Es el scheduler el que asume la escucha activa, con la consiguiente ventaja de que el DAG no se inicia hasta que el evento ha tenido lugar.
Caso de uso de event-driven scheduling con BigQuery
Por otro lado, un ejemplo de uso en una tarea concreta podría ser la carga de dimensiones desde GCS a BigQuery. Hasta ahora, el operador que hacía la carga debía tener establecido con anterioridad un sensor que bloqueaba un worker detectando si el fichero había sido cambiado. En caso de ocurrir este evento, se podía continuar con la pipeline. Gracias a los operadores diferibles, se puede conseguir que la pipeline espere de manera eficiente a que, por ejemplo, se haya modificado un manifiesto, liberando los recursos hasta que esto ocurra.
Para que el DAG no dependa de una activación manual o externa y que mantenga el enfoque diferible, la solución ideal en las versiones modernas de Airflow es combinar un enfoque híbrido. Por ejemplo, entre un cron tradicional con un sensor diferible.
Un ejemplo de este caso sería el siguiente:
dag = DAG(
dag_id="gcs_to_bigquery_event_driven",
start_date=pendulum.datetime(2026, 1, 1, tz="UTC"),
schedule="30 8 * * *",
catchup=False,
)
wait_for_file = GCSObjectExistenceSensor(
task_id="wait_for_file",
bucket="data-bucket",
object="incoming/master_data.csv",
deferrable=True,
dag=dag,
)
load_to_bq = GCSToBigQueryOperator(
task_id="load_to_bq",
bucket="data-bucket",
source_objects=["incoming/master_data.csv"],
destination_project_dataset_table="project_id.datawarehouse.master_data",
source_format="csv",
dag=dag,
)
wait_for_file >> load_to_bqComo podemos observar, este Dag no depende de un sensor que hace polling constante bloqueando un worker. Su tarea de espera se activa cuando detecta que ha llegado el fichero a GCS. Esto permite que se consuman muchos menos recursos en el sistema. Por tanto, esta estructura es especialmente útil en arquitecturas orientadas a eventos, donde las pipeline se han de ejecutar cuando ocurran cambios en el sistema.
Sin embargo, hay que tener cuidado con cómo se usa este nuevo modelo. En caso de que nuestro pipeline no requiera este nivel de reactividad, se puede acabar con pipelines excesivamente reactivos, mucho menos mantenibles, que podrían ser perfectamente ejecutados mediante datasets (assets) o timetables tradicionales.
Conclusión
Como hemos comprobado, los schedulers de Airflow van más allá de la ejecución de DAGs basados en el tiempo. Además, forman parte de la propia arquitectura de las pipelines. De esta manera, es posible adaptar nuestros procesos a los diferentes escenarios y necesidades.
Por un lado, hemos visto cómo el Timetable scheduling se centra en procesos batch tradicionales. Por su parte, el asset-aware scheduling se focaliza en la disponibilidad de los datos y el event-driven scheduling en la reacción a eventos externos. Todos ellos ofrecen diferentes enfoques para orquestar nuestros flujos de trabajo de forma eficiente.
Entender bien sus diferencias es algo crucial y permite diseñar pipelines robustos, mantenibles y escalables. En muchos casos, esto marca la diferencia entre un sistema mediocre y uno excelente.
En definitiva, Airflow 3 no solo amplía las capacidades de scheduling añadiendo el event-driven scheduling. Además, cambia la manera en la que debemos pensar a la hora de diseñar nuestros pipelines. Ahora, no solo debemos de comprender el flujo que se va a ejecutar, sino que debemos tener siempre en mente si queremos que nuestro sistema se ejecute en momentos concretos o reaccione a eventos específicos que establezcamos.
¡Esperamos que te haya servido el post! Si te ha parecido interesante, te animamos a visitar la categoría Software para ver artículos similares y a compartirlo en redes con tus contactos. ¡Hasta pronto!
