
Data deduplication is a problem that affects many organisations. In addition to negatively impacting business operations, it can also affect costs. In this article, we will analyse what it entails and what architecture to implement in a project of this nature.
What is data deduplication?
Even if a company thinks it knows its customers inside and out, the reality is that the same user may appear multiple times in different internal systems. They may be stored under slightly different names, with different phone numbers, different email addresses, or incomplete addresses. This problem is known as data fragmentation or deduplication.
Data deduplication is an issue that affects a wide range of business sectors. However, in the hospitality industry, it reaches a particularly high level of complexity due to the enormous number of elements involved in daily operations. These include PMS and CRM systems, booking engines, survey platforms, call center structures, mobile apps, and marketing tools.
Each of these elements continuously generates separate records. The result is a highly fragmented data ecosystem where a single guest may exist as several different individuals. From a technological standpoint, this leads to a massive loss of data quality. From a business perspective, it also means a direct decline in revenue, efficiency, and the ability to personalise the guest experience.
Customer 360 or single customer
The solution to this deduplication problem is known as Customer 360 or single customer. The goal of this approach is to create a master record that consolidates all of a customer’s scattered information into a single, consistent digital identity. To achieve this, simply storing data in a centralised database is not enough. The real challenge lies in determining when two seemingly different records actually represent the same person.
Many solutions attempt to resolve this issue using simple rules. For example, they might consider two records to be the same if they share the same email address or ID number. However, in more complex environments, this approach quickly fails. This is because customers change phone numbers, use different email addresses for work and personal use, make typos when making reservations, or a receptionist might misspell a last name. Even across different countries, incompatible formats for addresses, phone numbers, or documents can arise.
Architecture of a deduplication project
Deduplication architecture is typically built on real-time data pipelines. In these pipelines, rather than connecting each source system directly to the deduplication logic, the entire ingestion process is decoupled using streaming platforms such as Apache Kafka.
This approach allows any system to publish customer records in real time without the deduplication engine needing to know the exact source of the data. In this way, the architecture becomes data-source-agnostic. Thus, implementing a new PMS or integrating a new booking platform no longer requires changes to the structure or ETL processes.
The simplified architecture of the project is shown below:
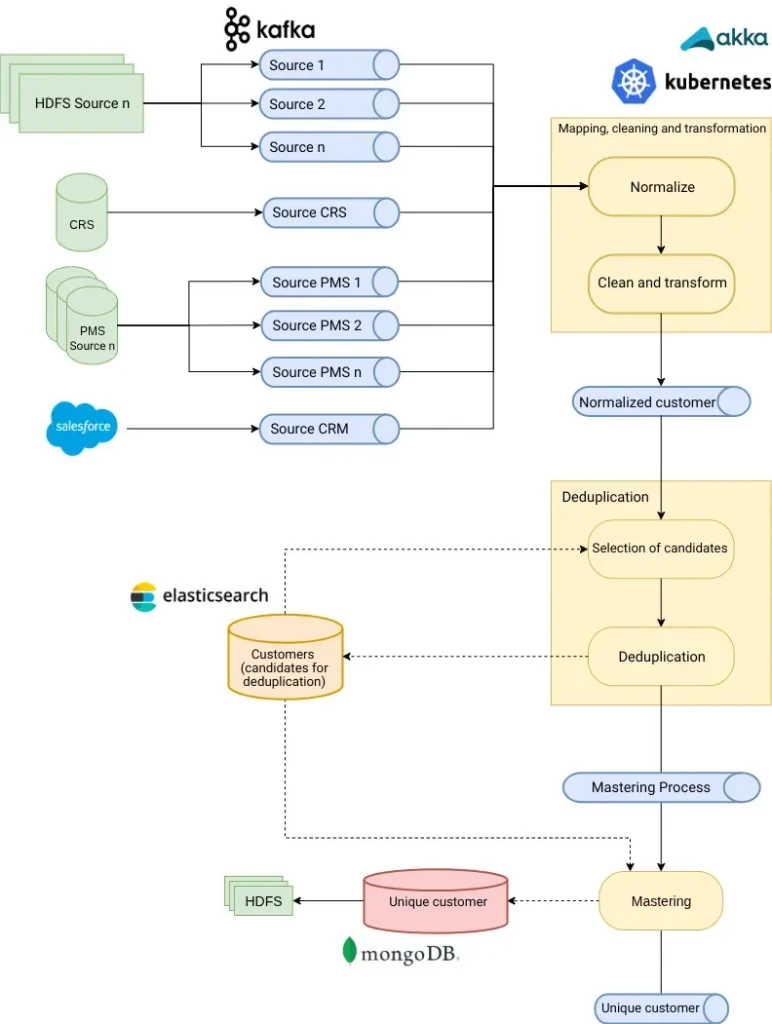
Data normalisation
At the processing level, the first major step is data normalisation. In this regard, the quality of deduplication depends directly on the quality of the input data. An email address such as “Juan.Martinez@GMAIL.Com” must be converted to a standard format. Similarly, a phone number such as “0034-600-123-456” must be converted to a uniform international format. Likewise, an address such as “Av. España No. 14” must be interpreted the same way as “Avenida España 14.” This process combines cleaning, standardisation, enrichment, and validation.
For first and last names, other types of techniques are typically applied. These include tokenisation, the removal of accents, and semantic dictionaries so that the system can understand that “José,” “Pepe,” and “Josep” are variants of the same name. For phone numbers, specialised libraries are used that can detect countries, area codes, and line types. Additionally, these libraries make it possible to identify whether a number is a cell phone, a landline, or even if it has an invalid format.
Candidate search
Once the data has been normalised, the candidate search process begins. This step is critical because it determines the balance between accuracy and scalability. Comparing each new customer against millions of existing records could become computationally infeasible.
For this reason, modern systems use intelligent blocking techniques that drastically reduce the search space. Their primary goal is to select only a small subset of potentially similar candidates. This process is carried out using tools such as Elasticsearch. This database allows for the combination of fuzzy matching, phonetic indexing, N-grams, and probabilistic scoring.
For example, the last name “Martínez” can be broken down into multiple textual subsets to detect partial typos. At the same time, phonetic algorithms can convert it into similar representations such as “MRTNS.” This makes it possible to find matches even when human errors are present. Hybrid searches combine different types of matching with varying relevance weights. An exact email match may have a very high weight, while a partial match in a last name may contribute only a moderate score.
The system does not yet decide whether two records are identical; it merely constructs a reduced set of plausible candidates. This reduction is the most important part from both an economic and computational standpoint. Poor design at this stage can cause infrastructure costs and processing time to skyrocket exponentially. Most projects do not take this complexity into account until they attempt to run real-time pipelines on tens of millions of customers.
Deduplication model
After identifying potentially similar candidates, the data is passed to the deduplication model. The purpose of this model is to determine whether two records belong to the same customer. However, making this determination involves significant mathematical, semantic, and business complexity.
In real-world environments, perfect data is practically nonexistent. This is because customers make typos, human operators enter incomplete names, some legacy systems store corrupted information, and others use different alphabets or incompatible formats. For this reason, the deduplication model combines deterministic rules with probabilistic algorithms.
There are many different types of records to deduplicate, and each presents a different level of complexity. To begin with, the simplest cases are exact duplicates. If two records share exactly the same first name, last name, ID number, and phone number, the system can merge them with a high degree of confidence.
Algorithms for deduplication
However, the real problems begin when small differences arise. For example, “Pepe Gómez,” “Jose Gómez,” and “Pepe Gome” could all refer to the same person, but they could also be different users.
Fuzzy Matching
This is where fuzzy matching comes into play. Fuzzy matching is a technique that calculates the similarity between two text strings, even when there are some differences between them. A widely used algorithm for this is the Levenshtein distance. Its purpose is to measure how many operations are needed to transform one string into another. The smaller the distance, the greater the similarity.
Jaro-Winkler
On the other hand, Jaro-Winkler is also commonly used for proper names. It is an algorithm specifically designed to detect minor typographical variations. Its main advantage is that it penalises minor errors less heavily and places greater emphasis on common prefixes. For addresses or longer texts, vector metrics such as Cosine Similarity are typically used.
However, no single algorithm is sufficient on its own. Multiple scores are needed to determine whether two records belong to the same customer. That is why the deduplication model uses composite scoring. Each customer attribute contributes a weighted score to the final result, allowing for the creation of models that are much more flexible and adaptable to the business.
For example, an identical email address may carry more weight than a similar one. An ID document may be considered nearly deterministic, while a partially matching phone number may provide only moderate evidence. The final result is typically converted into a probabilistic score between 0 and 1, and decision thresholds are then applied. Above a certain value, the system performs an automatic match. Those falling within two intermediate ranges, the system may send the case for manual review; if it falls below the minimum threshold, the match is discarded.
If the thresholds are set too aggressively, false positives will occur. Similarly, if they are set too conservatively, false negatives will increase.
Overmerging and partial duplicates
Mistakenly merging two different people can lead to very serious operational problems—ranging from incorrect marketing campaigns to errors in loyalty programs or legal issues related to data privacy.
A classic example is a father and son with the same first and last names who share a family phone number and email address. At first glance, they appear to be the same customer. However, merging them incorrectly creates an overmerging problem. For this reason, the deduplication model must incorporate penalty rules. For example, incompatible birthdates, different documents, or detected family relationships can drastically reduce the final score.
Another significant problem is partial duplicates. That is, in many cases, no single system contains enough information to identify the customer. A CRM might have a name and email address. A PMS, on the other hand, might have a name and phone number, while a post-stay survey might contain only an email address. By combining all these sources, the complete identity may emerge. Therefore, deduplication is a problem of distributed correlation. Each new data point not only updates a customer’s profile but also improves the ability to detect new related duplicates.
In more advanced projects, machine learning models are trained using algorithms that enable them to learn complex patterns from previously labeled historical data. These models learn vector representations capable of detecting semantic relationships between seemingly distinct records. However, the use of artificial intelligence introduces new problems:
- Explainability decreases considerably.
- Decisions are no longer entirely deterministic.
- Training these models requires high-quality labeled datasets.
However, it often quickly becomes apparent that the quality of the training completely determines the system’s behavior. For this reason, deduplication models typically combine deterministic rules with probabilistic models rather than relying exclusively on AI.
Customer mastering
Once the system determines that multiple records belong to the same person, a single customer record must be created. This process is known as mastering.
Mastering is the component responsible for merging multiple partial versions of a customer into a single, consolidated record. Its purpose is not merely to combine records; it must also decide which information to retain when conflicting data exists. For example, the same customer may appear as “Pepe,” “Jose,” or “Josep” in different sources, may have multiple phone numbers, different email addresses, and multiple historical addresses.
Mastering strategies
The question is no longer whether the records belong to the same customer, but which version should be considered the correct one. To resolve this issue, mastering employs different resolution strategies depending on the type of data. One of the most common is prioritisation by source.
For example, a CRM typically has more reliable information than a PMS with data entered manually by the front desk. A call center can be particularly reliable for validating phone numbers, and a marketing platform may contain more up-to-date email addresses.
Another widely used strategy is to select the most frequently occurring value. If the same email address appears in multiple systems, it is more likely to be the correct one. The most recent data criterion is also commonly used. This criterion is particularly useful for addresses or phone numbers because customers’ information can change over the years.
In other cases, priority is given to the most complete value, where an address including street, city, and ZIP code provides much more context than a partial address without additional geographic information.
The solution must be specifically tailored to each attribute, such as:
- Names are typically resolved using frequency, length, and source reliability.
- Emails and phone numbers are typically stored as multiple collections classified by type. This makes it possible to distinguish between personal, work, or secondary email addresses.
NoSQL storage
The final result is typically stored in NoSQL databases such as MongoDB. This type of storage allows for the creation of flexible structures and the representation of heterogeneous and evolving information. At the same time, updated events from the individual customer can be re-broadcast in real time via Apache Kafka. This enables a company to process data in real time across different departments.
From a business perspective, this is where the project’s return on investment truly becomes apparent. This is because a well-constructed single customer view directly impacts marketing, revenue, operations, and the customer experience. Furthermore, customer segmentation becomes much more accurate because there are no longer duplicate or inconsistent records, and a company’s departments can build accurate behavioral profiles.
It is also possible to identify frequent guests, premium guests, family profiles, or users with a high likelihood of returning. In addition, a front desk clerk can view historical preferences, the guest’s usual language, preferred room type, or previous incidents, among other details. All of this is available regardless of the channel the guest used to make the reservation.
Integration with post-stay surveys also opens up new possibilities. Linking NPS, satisfaction, and spending behavior allows critical signals to be detected much earlier. A high-value guest who begins to give poor ratings can become a priority alert for the business.
Advantages of deduplication architecture
From a technical perspective, one of the major benefits of these architectures is their operational flexibility in transforming a single-client platform into a central enterprise identity hub:
- Different departments can consume data in different ways depending on their needs.
- Real-time systems can directly read streaming events.
- Analytics environments can consume daily snapshots from distributed storage systems such as Apache Hadoop.
- Other teams can directly access document repositories or search engines.
However, maintaining this ecosystem requires continuous monitoring, making technical KPIs essential. For example, precision, recall, false positive rate, and match rate allow for the objective measurement of the deduplication system’s quality. Latency also becomes critical in real-time architectures, as the system must operate within milliseconds if it is to integrate with live operational processes.
Business metrics are also essential; for example, reducing duplicate customers, improving NPS, increasing the number of effective campaigns, and boosting revenue per guest are the metrics that truly justify the project’s investment.
That’s it for today’s post. If you found it interesting, we encourage you to visit the Data Science category to see all the related posts and to share it in networks with your contacts. See you soon!
