
Apache Airflow es un software libre de orquestación de flujos de trabajo, que son creados a través de scripts de Python, y que pueden ser monitoreados haciendo uso de su interfaz de usuario. Algunos ejemplos de flujos de trabajo en los que se podría utilizar esta herramienta son la programación de pipelines ETL (Extract, Transform, Load), la generación automática de informes o la creación periódica de copias de seguridad.
Es importante notar que Airflow no es una herramienta ETL, es decir, el objetivo de Airflow no es manejar el dato (especialmente cuando el tamaño de este es considerable), sino las tareas que se ocupen de este, siguiendo el orden y el flujo definido por el usuario.
Componentes de Airflow
Una instalación de Airflow normalmente consiste en 5 componentes principales. El primer componente, llamado Web Server, se encarga de proveer la interfaz gráfica donde el usuario puede interactuar con los flujos de trabajo y revisar el estado de las tareas que los componen.
En segundo lugar, el Scheduler es el componente encargado de planificar las ejecuciones de las tareas y las pipelines definidas por el usuario. Cuando las tareas están listas para ser ejecutadas, estas son enviadas al Executor. El Executor define cómo las tareas van a ser ejecutadas y son enviadas a los Workers. Airflow proporciona diferentes tipos de Executors que pueden ejecutar las tareas de manera secuencial (SequentialExecutor) o permitiendo la paralelización de las mismas (LocalExecutor, CeleryExecutor, etc.).
El Worker es el proceso o subproceso que ejecuta las tareas. Dependiendo de la configuración del Executor, habrá uno o varios Workers que reciban diferentes tareas. Finalmente, el Metastore es una base de datos donde se guardan todos los metadatos de Airflow y de los flujos de trabajo definidos. Es utilizado por el Scheduler, el Executor y el Webserver para guardar sus estados.

Definiendo los flujos de trabajo
La unidad principal con la que Airflow define un flujo de trabajo es el Grafo Acíclico Dirigido (DAG). Los nodos del grafo son las diferentes tareas y las aristas dirigidas muestran las relaciones y dependencias entre ellas. La propiedad acíclica permite que el DAG sea ejecutado de principio a fin sin entrar en ningún bucle.
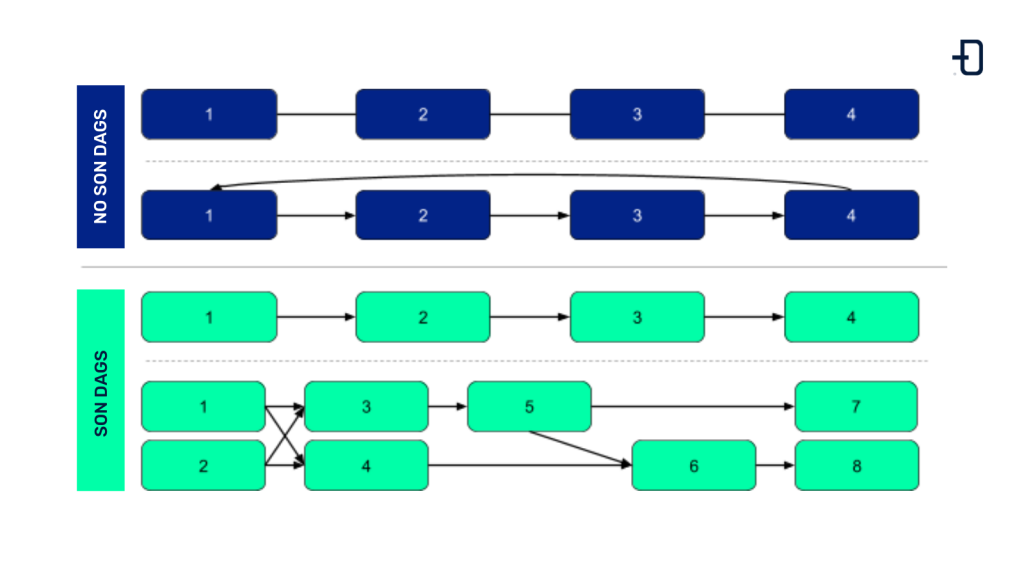
En la siguiente imagen se muestran algunos ejemplos de grafos que son DAGs y grafos que no lo son. Aquellos que presentan ciclos o que no están dirigidos no entran en la definición de DAG.
Las tareas son las unidades básicas de ejecución. Están ordenadas según las dependencias anteriores y posteriores definidas en el DAG al que pertenecen. Una tarea se define a partir de la realización de un Operator, que sirven como plantillas para una funcionalidad específica. Un ejemplo de operador sería el BashOperator, que permite ejecutar un comando Bash.
Los Hooks permiten comunicarse con diferentes plataformas externas e interactuar con sus APIs de manera sencilla. En muchos casos los operadores hacen uso de los Hooks para describir una funcionalidad específica, como por ejemplo, conectarse a una base de datos usando un hook, realizar una query específica y guardar los resultados en un archivo en local.
Una de las características principales de Airflow es que el usuario puede definir sus propios Operators y Hooks. Esta capacidad permite que la comunidad de Airflow haya desarrollado y mantenga más de 60 paquetes de proveedores, que integran diferentes proyectos externos, entre los que se encuentran opciones interesantes para Big Data, como Apache Spark o servicios en la nube como Amazon o Google.
Una vez introducido el DAG, es el momento de ver un ejemplo en acción. Se define un DAG a partir de un id, un intervalo de ejecución y una fecha de inicio. Por cómo funciona Airflow, el scheduler planificará una cierta ejecución para cuando haya pasado el intervalo de ejecución. En el ejemplo del DAG test_dag, la primera ejecución correspondiente a día 1 de enero de 2022, se planificará para día 2 de enero de 2022, ya que el intervalo de ejecución es de 1 día.
from datetime import datetime
from airflow import DAG
from airflow.operators.dummy import DummyOperator
dag = DAG(
dag_id='test_dag',
schedule_interval="@daily",
start_date=datetime(2022, 1, 1),
)
task_1 = DummyOperator(task_id="first_task", dag=dag)
task_2 = DummyOperator(task_id="second_task", dag=dag)
task_3 = DummyOperator(task_id="third_task", dag=dag)
task_4 = DummyOperator(task_id="fourth_task", dag=dag)
task_1 >> task_2 >> task_3
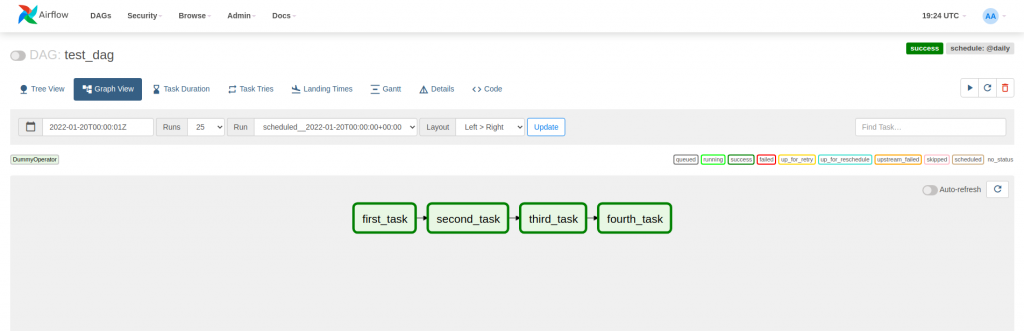
task_4 << task_3El DAG del ejemplo está formado por 4 tareas de DummyOperator, que no hace nada. Para describir las dependencias entre tareas se usan los operadores de bitshift >> y <<. En la siguiente imagen se puede observar como las dependencias se representan en el grafo del webserver.
En el ejemplo anterior, se ha visto un DAG que ejecuta tareas secuencialmente. No obstante, Airflow dispone de Executors que pueden ejecutar tareas en paralelo. En el siguiente ejemplo se ha configurado el DAG anterior para que second_task y third_task dependan de first_task y se puedan ejecutar de manera paralela.
task_1 >> [task_2, task_3]
task_4 << task_3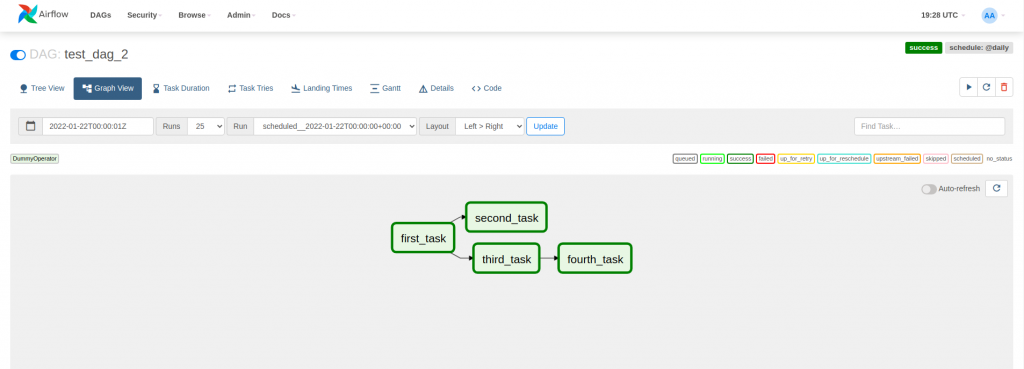
Aumentando la reusabilidad de los DAGs
El uso de Operators y Hooks ha permitido que la implementación de las tareas sea, valga la redundancia, una tarea más sencilla. Estos son capaces de abstraer una funcionalidad sin entrar en los detalles concretos, permitiendo así una mayor reusabilidad. Asimismo, Airflow facilita la reutilización de DAGs mediante variables y conexiones.
Las variables son un conjunto de claves y valores que son accesibles para los DAGs en tiempo de ejecución y configurables desde la interfaz gráfica (Admin > Variables). En el siguiente ejemplo se hace uso de una variable para definir un directorio donde se encuentra un archivo a borrar.
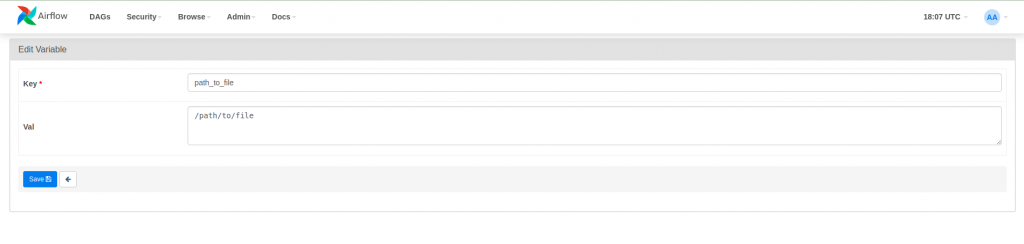
PATH_TO_FILE = Variable.get("path_to_file")
remove_file = BashOperator(
task_id="remove_file",
bash_command=f"rm {PATH_TO_FILE}/file.txt",
dag=dag
)Si el directorio cambia o en un entorno el directorio es diferente, no habrá que hacer un dag nuevo: simplemente se tendrá que cambiar la variable que define el directorio.
Una conexión es un conjunto de parámetros donde se guardan las credenciales para comunicarse con un sistema externo. Las conexiones se pueden definir desde la interfaz gráfica (Admin > Connections) y permiten definir un id de conexión que los DAGs o, más convenientemente, los Hooks pueden usar para conectarse sin tener que especificar las credenciales cada vez. En el siguiente ejemplo, se crea una conexión a Google Cloud Storage usando un keyfile y se usa para cargar un archivo local a Google Cloud Storage.
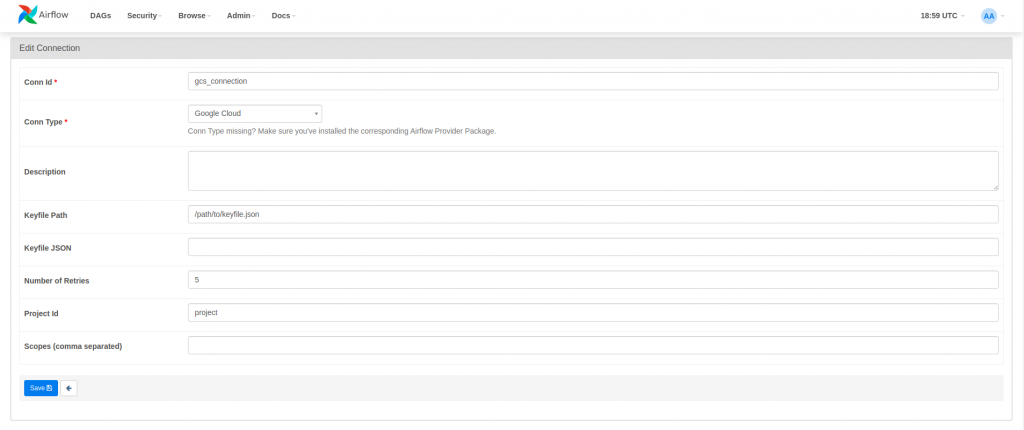
upload_file_to_gcs = LocalFilesystemToGCSOperator(
task_id="upload_file_to_gcs",
src="/path/to/file/file.txt",
dst="/path/to/file/",
bucket="bucket",
gcp_conn_id='gcs_connection',
dag=dag,
)Una manera de ilustrar la utilidad de las conexiones sería imaginar un proyecto típico con un entorno de producción y una de desarrollo: el hecho de abstraer la conexión de la definición del DAG permite cambiar entre entornos solamente cambiando los parámetros de la conexión, manteniendo igual el id.
Conclusión
En conclusión, Apache Airflow es una herramienta sencilla para la implementación de flujos de trabajo, que nos permite la automatización de pipelines ETL. La cantidad de paquetes de proveedores disponibles permite que la funcionalidad de Airflow se pueda extender fácilmente. Su interfaz de usuario facilita la interacción y la monitorización de flujos de trabajo, que son representados como DAGs.
Si quieres conocer más en profundidad esta herramienta, puedes consultar la documentación oficial de Airflow o consultar nuestros otros posts sobre ella:
- En Airflow Avanzado. Dependencias Entre Tareas y Sensores Cross-DAG se separan flujos de trabajo cruzados en diferentes DAGs usando operadores sensores.
- En Despliegue de Airflow: CeleryExecutor en Kubernetes se despliega Apache Airflow en un clúster de Kubernetes para que pueda escalar mejor horizontalmente.
- En Plugin de Pentaho PDI para Airflow se desarrolla un plugin de Airflow para orquestar las tareas de Kettle.
¡Eso es todo! Si este artículo te ha resultado interesante, te animamos a visitar la etiqueta Airflow para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
