
Apache Airflow is a free workflow orchestration software, which are created through Python scripts, and can be monitored using its user interface. Some examples of workflows in which this tool could be used are the scheduling of ETL (Extract, Transform, Load) pipelines, the automatic generation of reports or the periodic creation of backups.
It is important to note that Airflow is not an ETL tool, that is, the objective of Airflow is not to manage the data (especially when the size of the data is considerable), but the tasks that deal with it, following the order and flow defined by the user.
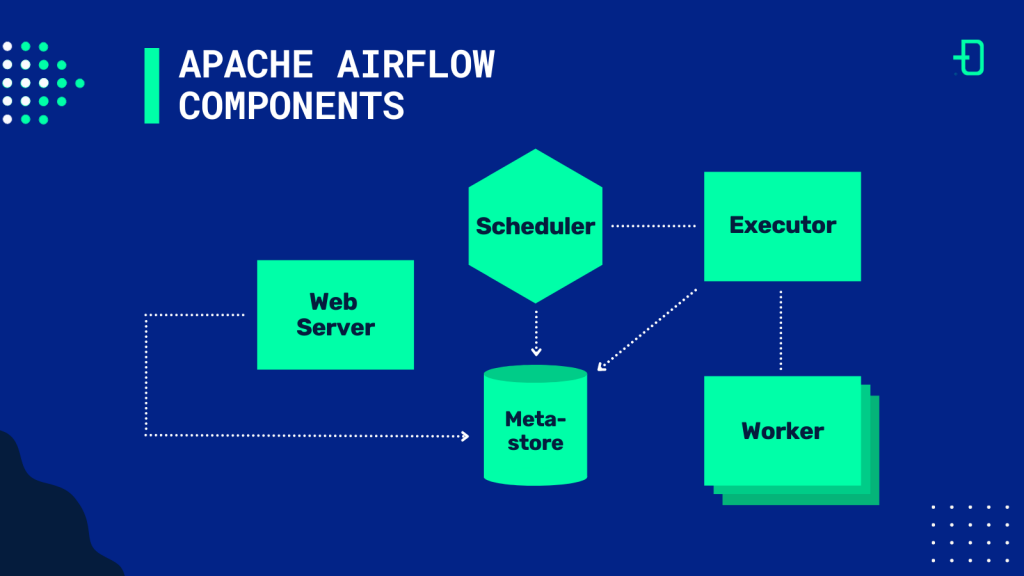
Airflow components
An Airflow installation normally consists of 5 main components. The first component, called Web Server, is responsible of providing the graphical interface where the user can interact with the workflows and check the status of the tasks that compose them.
Secondly, the Scheduler is the component in charge of scheduling the executions of the tasks and pipelines defined by the user. When the tasks are ready to be executed, they are sent to the Executor. The Executor defines how the tasks are going to be executed and sent to the Workers. Airflow provides different types of Executors that can execute the tasks sequentially (SequentialExecutor) or allowing the parallelization of them (LocalExecutor, CeleryExecutor, etc.).
The Worker is the process or sub-process that executes the tasks. Depending on the configuration of the Executor, there will be one or several Workers that receive different tasks. Finally, the Metastore is a database where all the metadata of Airflow and the defined workflows are stored. It is used by the Scheduler, the Executor and the Webserver to store their statuses.
Defining workflows
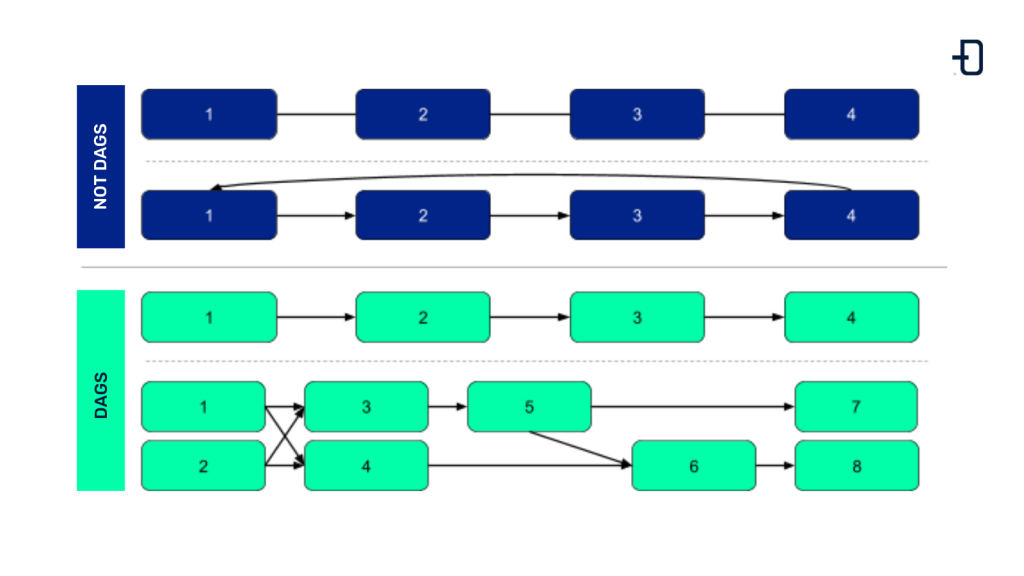
The main unit with which Airflow defines a workflow is the Directed Acyclic Graph (DAG). The nodes of the graph are the different tasks and the directed edges show the relationships and dependencies between them. The acyclic property allows the DAG to be executed from beginning to end without entering any loop.
The following image shows some examples of networks that are DAGs and networks that are not. Those that have loops or are undirected do not fall under the definition of DAG.
Tasks are the basic units of execution. They are ordered according to the upstream and downstream dependencies defined in the DAG to which they belong. A task is defined from the realization of an Operator, which serve as templates for a specific functionality. An example of an operator would be the BashOperator, which allows executing a Bash command.
Hooks allow to communicate with different external platforms and interact with their APIs in a simple way. In many cases operators make use of Hooks to describe a specific functionality, such as connecting to a database using a hook, performing a specific query and saving the results to a file locally.
One of the main features of Airflow is that the user can define their own Operators and Hooks. This capability allows the Airflow community to develop and maintain more than 60 providers packages, which integrate different external projects, including interesting options for Big Data, such as Apache Spark or cloud services such as Amazon or Google.
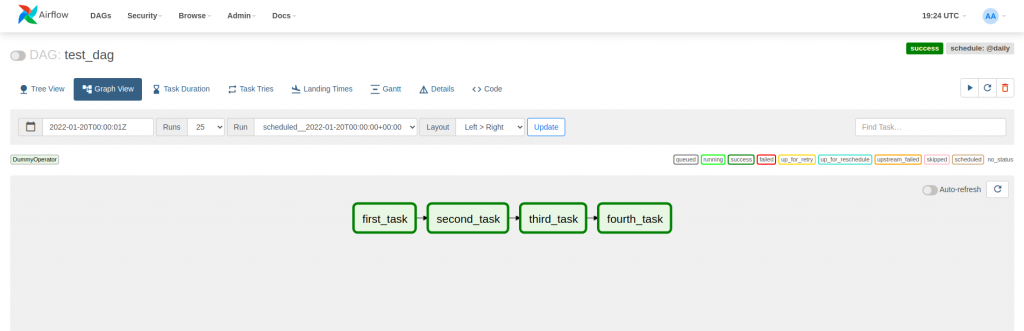
Once the DAG has been introduced, it is time to see an example in action. A DAG is defined from an id, an execution interval and a start date. The way Airflow works, the scheduler will plan a certain execution for when the execution interval has passed. In the example of the DAG test_dag, the first execution corresponding to January 1, 2022, will be scheduled for January 2, 2022, since the execution interval is 1 day.
from datetime import datetime
from airflow import DAG
from airflow.operators.dummy import DummyOperator
dag = DAG(
dag_id='test_dag',
schedule_interval="@daily",
start_date=datetime(2022, 1, 1),
)
task_1 = DummyOperator(task_id="first_task", dag=dag)
task_2 = DummyOperator(task_id="second_task", dag=dag)
task_3 = DummyOperator(task_id="third_task", dag=dag)
task_4 = DummyOperator(task_id="fourth_task", dag=dag)
task_1 >> task_2 >> task_3
task_4 << task_3The DAG in the example consists of 4 DummyOperator tasks, which does nothing. To describe the dependencies between tasks the bitshift operators >> and << are used. In the following image you can see how the dependencies are represented in the webserver graph.
In the previous example, we have seen a DAG that executes tasks sequentially. However, Airflow has Executors that can execute tasks in parallel. In the following example, the above DAG has been configured so that second_task and third_task depend on first_task and can be executed in parallel.
task_1 >> [task_2, task_3]
task_4 << task_3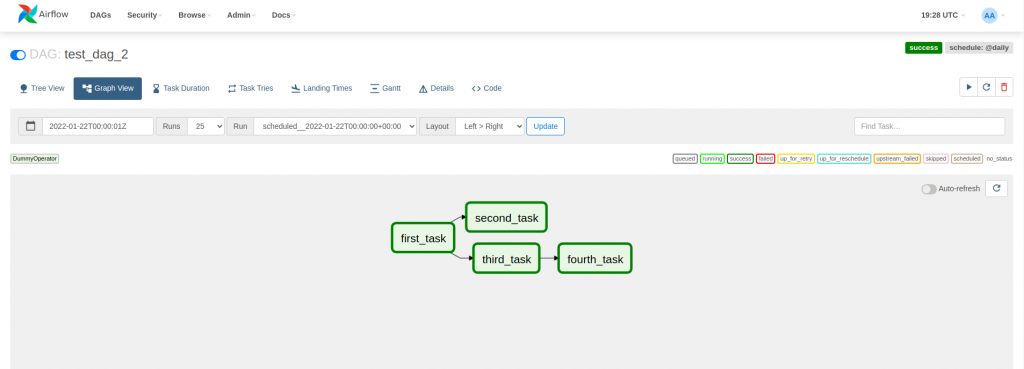
Increasing reusability of DAGs
The use of Operators and Hooks has made the implementation of tasks a simpler task. These are capable of abstracting a functionality without going into the specific details, thus allowing for greater reusability. Airflow also facilitates the reuse of DAGs through variables and connections.
Variables are a set of keys and values that are accessible to DAGs at runtime and configurable from the graphical interface (Admin > Variables). In the following example a variable is used to define a directory where a file to be deleted is located.
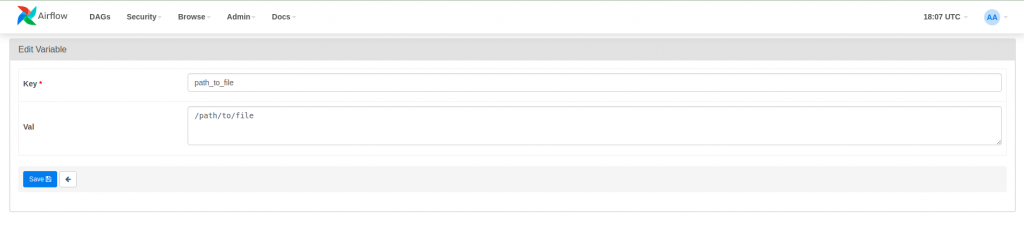
PATH_TO_FILE = Variable.get("path_to_file")
remove_file = BashOperator(
task_id="remove_file",
bash_command=f"rm {PATH_TO_FILE}/file.txt",
dag=dag
)If the directory changes or in an environment the directory is different, you do not have to make a new dag: you simply have to change the variable that defines the directory.
A connection is a set of parameters where the credentials to communicate with an external system are stored. Connections can be defined from the graphical interface (Admin > Connections) and allow you to define a connection id that DAGs or, more conveniently, Hooks can use to connect without having to specify the credentials each time. In the following example, a connection to Google Cloud Storage is created using a keyfile and used to upload a local file to Google Cloud Storage.
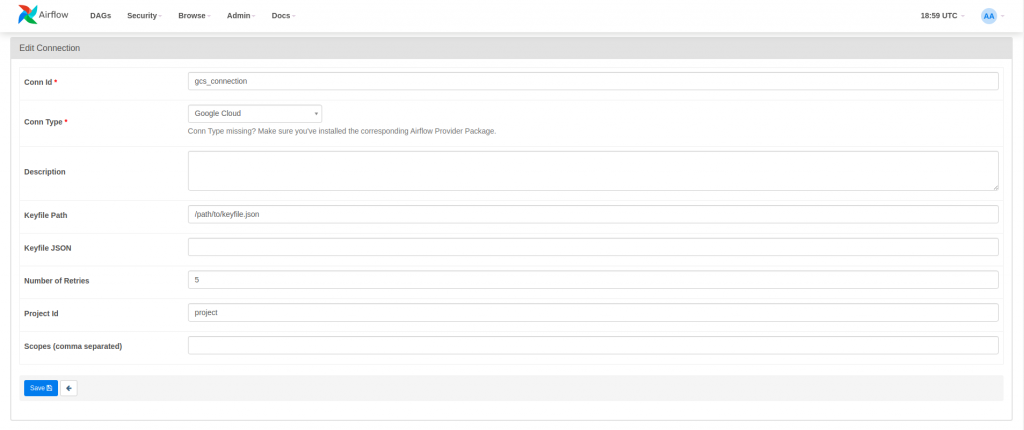
upload_file_to_gcs = LocalFilesystemToGCSOperator(
task_id="upload_file_to_gcs",
src="/path/to/file/file.txt",
dst="/path/to/file/",
bucket="bucket",
gcp_conn_id='gcs_connection',
dag=dag,
)One way to illustrate the usability of connections would be to imagine a typical project with a production environment and a development environment: abstracting the connection from the DAG definition allows to switch between environments only by changing the connection parameters, keeping the same id.
Conclusion
In conclusion, Apache Airflow is a simple tool for implementing workflows, which allows us to automatize ETL pipelines. The number of available providers packages allows Airflow’s functionality to be easily extended. Its user interface facilitates interaction and monitoring of workflows, which are represented as DAGs.
If you want to learn more about this tool, you can consult the official Airflow documentation or check our other posts about it:
- In Advanced Airflow. Cross-DAG task and sensor dependencies, cross workflows are separated into different DAGs using sensor operators.
- In Deploying Airflow: CeleryExecutor in Kubernetes, Apache Airflow is deployed in a Kubernetes cluster so it can scale better horizontally.
- In Pentaho PDI Plugin for Airflow, an Airflow plugin is developed to orchestrate Kettle tasks.
That’s it! If you found this article interesting, we encourage you to visit the Airflow tag with all related posts and to share it on social media. See you soon!
