
Apache Spark es un framework open source que nos permite procesar grandes volúmenes de datos de forma distribuida. ¿Cómo? Dividiendo los grandes volúmenes de datos, imposibles de procesar en una máquina, y repartiendolos entre los diferentes nodos del clúster.
En este post nos centraremos en las RDD haciendo una pausa en las transformaciones y el lazy evaluation.
¿Qué es Apache Spark y cómo funciona?
Antes de continuar, y si no conoces Hadoop, recomiendo hacer una parada y leer uno de los artículos anteriores de este blog donde hablamos sobre este framework. ¿Por qué? Aunque Spark mejora el modelo de programación Mapreduce de Hadoop, Spark puede correr sobre los componentes de Hadoop y utilizar a Yarn como clúster manager y HDFS como gestor de archivos. Siendo Spark, en este escenario, la unidad de procesamiento, y los componentes de Hadoop los brazos ejecutores.
La ventaja de Spark radica en que procesa los datos desde la RAM, utilizando un concepto llamado RDD (Resilient Distributed Dataset) y del que hablaremos más adelante. Otra ventaja, es el uso de la técnica lazy evaluation, donde las transformaciones no son realizadas al instante. Spark mantiene el registro de las operaciones a realizar, mediante el uso de DAGs, y cuando se ejecuta una llamada a la acción se realizan todas estas.
Por último, cabe mencionar que Spark tiene soporte en diferentes lenguajes como son: Java, Scala, R, SQL y Python.
¿Qué es un RDD en Spark?
Apache Spark trabaja los datos sobre un concepto llamado RDD (Resilient Distributed Dataset). Estas estructuras de datos contienen una colección de objetos distribuidos y están diseñadas para que cada colección sea dividida en múltiples particiones. Cada partición puede ser ejecutada en un cluster distinto.
Las RDDs se pueden crear de dos formas:
- Utilizando una fuente de almacenamiento, como por ejemplo la función
textFiledelSparkContext(). - Aplicando una transformación a un RDD ya existente para crear uno nuevo a partir de este. Los RDD son inmutables por lo que las transformaciones no se aplican al RDD de origen, sino que se crea un nuevo RDD para almacenar dichos cambios.
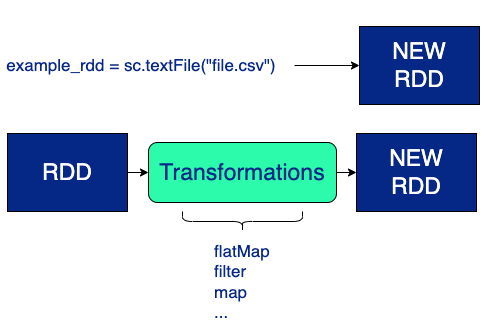
Transformaciones y Lazy Evaluation en Spark
Spark se basa en transformaciones y acciones. Una transformación es un conjunto de operaciones que manipulan el dato mientras que las acciones son las que muestran un resultado.
Las transformaciones de datos en Spark se realizan usando la técnica lazy evaluation. Así pues, estas son retrasadas hasta que un resultado sea necesario. Cuando Spark detecta que se va a ejecutar una acción, crea un DAG donde va registrando todas las transformaciones de forma ordenada. De este modo, en el momento que se precise, se realizarán las transformaciones, se optimizarán y se obtendrá el resultado esperado.
Esto lo podemos ver más en detalle con el siguiente ejemplo:
Para este ejemplo utilizaremos PySpark en donde crearemos una RDD a partir de un csv y le aplicaremos varias transformaciones para visualizar de esta forma el plan de ejecución creado.
rdd= sc.textFile("file.csv")
transformation_1 = rdd.map(parsedLine_returningTuple)
transformation_2 = transformation_1.filter(lambda x: "FILTER" in x[1])
transformation_3 = transformation_2.map(lambda x: (x[0], x[2]))
transformation_4 = transformation_3.reduceByKey(lambda x, y: min(x, y))
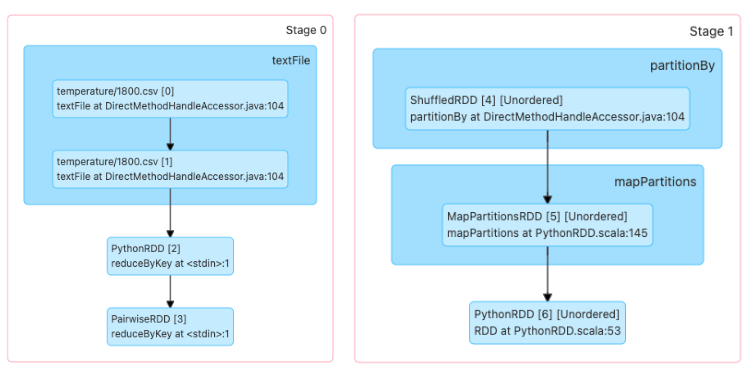
print(transformation_4.toDebugString())Para visualizar el plan de ejecución utilizamos la función toDebugString(). Este nos dará el plan de ejecución lógica comenzando por la RDD que no tiene ninguna dependencia y terminará por la RDD que ejecutará la acción. El número en paréntesis (2) representa el nivel de paralelismo.
Output>
PythonRDD[6] at RDD at PythonRDD.scala:53 []
|MapPartitionsRDD[5] at mapPartitions at PythonRDD.scala:145 []
|ShuffledRDD[4] at partitionBy at DirectMethodHandleAccessor.java:104 []
+-(2) PairwiseRDD[3] at reduceByKey at <stdin>:1 []
|PythonRDD[2] at reduceByKey at <stdin>:1 []
|file.csv MapPartitionsRDD[1] at textFile at DirectMethodHandleAccessor.java:104 []
|file.csv HadoopRDD[0] at textFile at DirectMethodHandleAccessor.java:104 []'En esta salida vemos el plan de ejecución y los diferentes tipos de RDDs que van a ser creados según las transformaciones que se realizarán. En este punto, el plan lógico (DAG) aún no se ha materializado, ya que no se ha realizado ninguna acción que haga ejecutar un Spark Job.
Algunas RDDs que podemos ver en este plan de ejecución son:
- PairwiseRDD: Es una RDD que contiene objetos de tipo Key/Value.
- ShuffledRDD: Esta fue creada al llamar a la transformación
reduceByKeypara asegurarse de que cada ítem con el mismo KEY pertenezcan a la misma partición. Recordemos que las RDDs son distribuidas, así que para garantizar que se ha agrupado por Key, Spark genera una operación de barajado para intercambiar información con los diferentes nodos.
- MapPartitionsRDD: Es una RDD creada a partir de las transformaciones de map y filter.
Al realizar la siguiente acción transformation_4.collect() vemos el plan de acción ya materializado y podemos ver que se ha ejecutado de acuerdo al plan previamente generado.
Pongamos otro ejemplo más simple para verlo un poco mejor:
rdd= sc.parallelize(range(1000))
transformation_1 = rdd.map(lambda x: x+2)En este ejemplo, solo estamos creando una lista de enteros y le estamos aplicando una transformación de sumarle “2” a cada objeto de la lista, por lo que nuestro plan lógico de ejecución sería algo como lo siguiente:
Output>
(8) PythonRDD[1] at RDD at PythonRDD.scala:53 []
| ParallelCollectionRDD[0] at readRDDFromFile at PythonRDD.scala:274 []Ahora bien, si nuevamente aplicamos una transformación (filter):
rdd= sc.parallelize(range(1000),8)
transformation_1 = rdd.map(lambda x: x+2)
transformation_2 = transformation_1.filter(lambda x: x%2 != 0)Output>
(8) PythonRDD[1] at RDD at PythonRDD.scala:53 []\n | ParallelCollectionRDD[0] at readRDDFromFile at PythonRDD.scala:274 []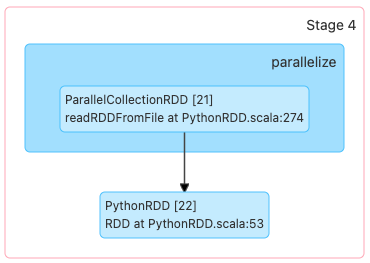
Vemos que el plan lógico de ejecución no cambia. Esto es debido a que Spark optimiza las transformaciones y agrupa los pasos redundantes. Spark genera el camino óptimo para mostrar un resultado. Esto no lo realiza ejecutando las transformaciones línea a línea, si no, esperando a que se le requiera una acción y generando un camino lógico para entregar el resultado deseado.
Conclusión
En este artículo hemos dado algunas pinceladas de lo que son los conceptos básicos de Apache Spark que son las RDDs, transformaciones y explicamos en detalle lo que es el lazy evaluation.
Poco a poco iremos evolucionando, adentrándonos más en este framework y realizaremos un tutorial en donde le pongamos práctica y sentido a toda esta teoría con lo que más nos gusta hacer: ¡tirar código! Utilizando Python y, por ende, la API de pySpark.
Si tienes alguna duda de cómo instalar PySpark y ya quieres ir practicando, puedes echar un ojo a este tutorial que enseña paso a paso cómo tener un Spark “up and running”.
¡Hasta la próxima!
