
Apache Spark is an open source framework that allows us to process large volumes of data in a distributed way. How? By dividing the large volumes of data, impossible to process in one machine, and distributing them among the different nodes of the cluster.
In this post we will focus on RDD, pausing on transformations and lazy evaluation.
What is Apache Spark and how does it work?
Before continuing, and if you are not familiar with Hadoop, I recommend you to stop and read one of the previous articles of this blog where we talked about this framework. Why? Although Spark improves on Hadoop’s Mapreduce programming model, Spark can run on top of Hadoop components and use Yarn as a cluster manager and HDFS as a file manager. Spark in this scenario is the processing unit and the Hadoop components are the execution arms.
The advantage of Spark lies in the fact that it processes data from RAM, using a concept called RDD (Resilient Distributed Dataset), which we will talk about later. Another advantage is the use of the lazy evaluation technique, where transformations are not performed instantly. Spark keeps track of the operations to be performed, through the use of DAGs, and when a call to action is executed, all of them are performed.
Finally, it is worth mentioning that Spark has support in different languages such as: Java, Scala, R, SQL and Python.
What is an RDD in Spark?
Apache Spark works on a concept called RDD (Resilient Distributed Dataset). These data structures contain a collection of distributed objects and are designed so that each collection is divided into multiple partitions. Each partition can be executed in a different cluster.
RDDs can be created in two ways:
- Using a storage source, such as the
SparkContext()textFilefunction. - Applying a transformation to an existing RDD to create a new one from it. RDDs are immutable so transformations are not applied to the source RDD, but a new RDD is created to store those changes.
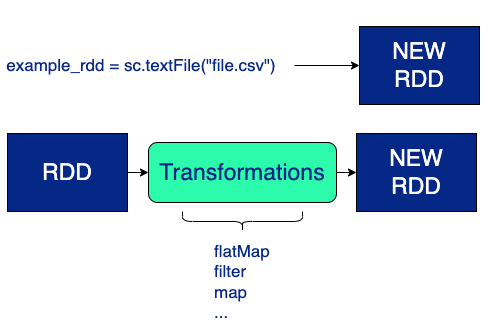
Transformations and Lazy Evaluation in Spark
Spark is based on transformations and actions. A transformation is a set of operations that manipulate the data while actions are those that display a result.
Data transformations in Spark are performed using the lazy evaluation technique. Thus, they are delayed until a result is needed. When Spark detects that an action is going to be executed, it creates a DAG where it registers all the transformations in an orderly fashion. In this way, when needed, the transformations will be performed, optimised and the expected result will be obtained.
We can see this in more detail with the following example:
For this example we will use PySpark where we will create a RDD from a csv and apply several transformations to it to visualize in this way the created execution plan.
rdd= sc.textFile("file.csv")
transformation_1 = rdd.map(parsedLine_returningTuple)
transformation_2 = transformation_1.filter(lambda x: "FILTER" in x[1])
transformation_3 = transformation_2.map(lambda x: (x[0], x[2]))
transformation_4 = transformation_3.reduceByKey(lambda x, y: min(x, y))
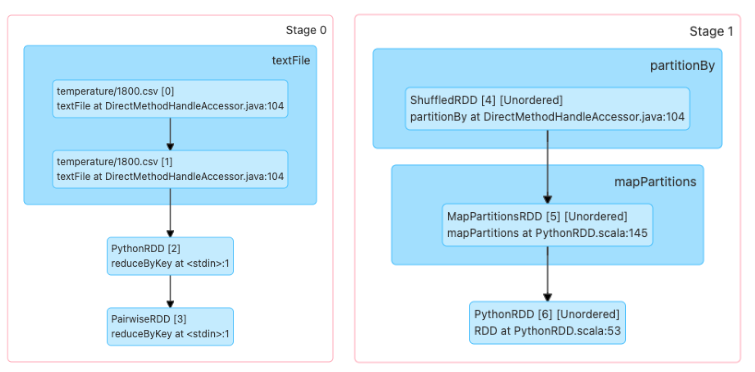
print(transformation_4.toDebugString())To display the execution plan we use the toDebugString() function. This will give us the logical execution plan starting with the RDD that has no dependencies and ending with the RDD that will execute the action. The number in parentheses (2) represents the level of parallelism.
Output>
PythonRDD[6] at RDD at PythonRDD.scala:53 []
|MapPartitionsRDD[5] at mapPartitions at PythonRDD.scala:145 []
|ShuffledRDD[4] at partitionBy at DirectMethodHandleAccessor.java:104 []
+-(2) PairwiseRDD[3] at reduceByKey at <stdin>:1 []
|PythonRDD[2] at reduceByKey at <stdin>:1 []
|file.csv MapPartitionsRDD[1] at textFile at DirectMethodHandleAccessor.java:104 []
|file.csv HadoopRDD[0] at textFile at DirectMethodHandleAccessor.java:104 []'In this output we see the execution plan and the different types of RDDs that are going to be created according to the transformations to be performed. At this point, the logical plan (DAG) has not yet materialised, as no action has been taken to execute a Spark Job.
Some RDDs that we can see in this execution plan are:
- PairwiseRDD: This is an RDD that contains objects of type Key/Value.
- ShuffledRDD: This was created by calling the
reduceByKeytransformation to make sure that each item with the same KEY belongs to the same partition. Recall that RDDs are distributed, so to ensure that it is grouped by Key, Spark generates a shuffle operation to exchange information with the different nodes. - MapPartitionsRDD: This is an RDD created from the map and filter transformations.
When performing the following action transformation_4.collect() we see the action plan already materialized and we can see that it has been executed according to the previously generated plan.
Let’s take another simpler example to show it a bit better:
rdd= sc.parallelize(range(1000))
transformation_1 = rdd.map(lambda x: x+2)In this example, we’re just creating a list of integers and applying a transformation of adding “2” to each object in the list, so our logical execution plan would be something like the following:
Output>
(8) PythonRDD[1] at RDD at PythonRDD.scala:53 []
| ParallelCollectionRDD[0] at readRDDFromFile at PythonRDD.scala:274 []But if we again apply a transformation (filter):
rdd= sc.parallelize(range(1000),8)
transformation_1 = rdd.map(lambda x: x+2)
transformation_2 = transformation_1.filter(lambda x: x%2 != 0)Output>
(8) PythonRDD[1] at RDD at PythonRDD.scala:53 []\n | ParallelCollectionRDD[0] at readRDDFromFile at PythonRDD.scala:274 []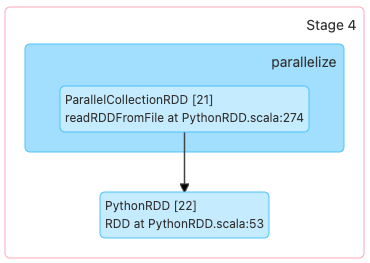
We see that the logical execution plan does not change. This is because Spark optimizes transformations and groups redundant steps. Spark generates the optimal path to display a result. It does this not by executing the transformations line by line, but by waiting for an action to be required and generating a logical path to deliver the desired result.
Conclusion
In this article we have given a few basic concepts of Apache Spark, such as RDDs, transformations and we have explained in detail what lazy evaluation is.
We will gradually evolve, going deeper into this framework and we will make a tutorial where we will put into practice and make sense of all this theory with what we like to do the most: throwing code! Using Python and, therefore, the pySpark API.
If you have any doubts about how to install PySpark and you want to start practicing, you can take a look at this tutorial that shows step by step how to get a Spark “up and running”.
See you next time!
