
El aprendizaje automático es quizás la rama más popular de la Inteligencia Artificial y se sirve de una serie de algoritmos cuya metodología se basa en realizar un análisis masivo de datos para aprender de ellos y, finalmente, encontrar la solución a un problema complejo.
¿Cuáles son los algoritmos de Machine Learning?
Los algoritmos de Machine Learning se clasifican en tres categorías distintas de aprendizaje, en función del tipo de caso que se esté tratando o el problema que se busque resolver: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo.
A continuación, definiremos en qué consiste cada uno de ellos así como los algoritmos más utilizados en cada área.
Aprendizaje Supervisado
La principal diferencia entre los tipos de aprendizaje automático radica en el tipo de datos que manejan. En el aprendizaje supervisado, el algoritmo de Machine Learning se nutre de datos previamente etiquetados, lo que significa que se conoce el valor del atributo objetivo de dichos datos.
Esto permitirá al modelo descifrar los patrones existentes en los datos y aprender a través de ellos para hacer una predicción del resultado cuando se le proporcione nueva información.
Los algoritmos más utilizados en el aprendizaje supervisado son la regresión lineal, la regresión logística, máquinas de vectores de soporte (SVM), K-Nearest Neighbors (KNN), árboles de decisión y bosques aleatorios.
Algoritmo de Regresión Lineal
El algoritmo de regresión lineal es uno de los más populares en Machine Learning y se utiliza para describir a través de una línea recta la tendencia en un conjunto de datos.
La regresión lineal permite mostrar o conocer la relación entre dos variables para realizar predicciones lo más acertadas posible.
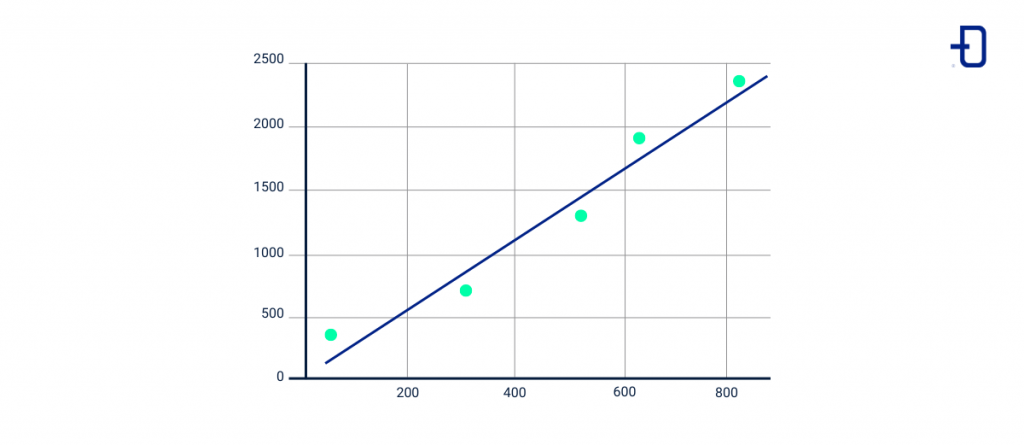
En un artículo previo de nuestro blog, mostramos un ejemplo de cómo implementar una regresión lineal con Python.
Algoritmo de Regresión Logística
En el caso de los algoritmos de regresión logística, los datos describen una línea curva continua en forma de S y utilizan una función sigmoidea para analizar dichos datos y predecir clases discretas en un dataset.
Aunque la regresión lineal y la logística puedan parecer semejantes visualmente, la diferencia entre ambas es que la primera aborda predicciones numéricas para buscar relaciones entre variables, mientras que la regresión logística se utiliza para la clasificación binaria de dos clases discretas.
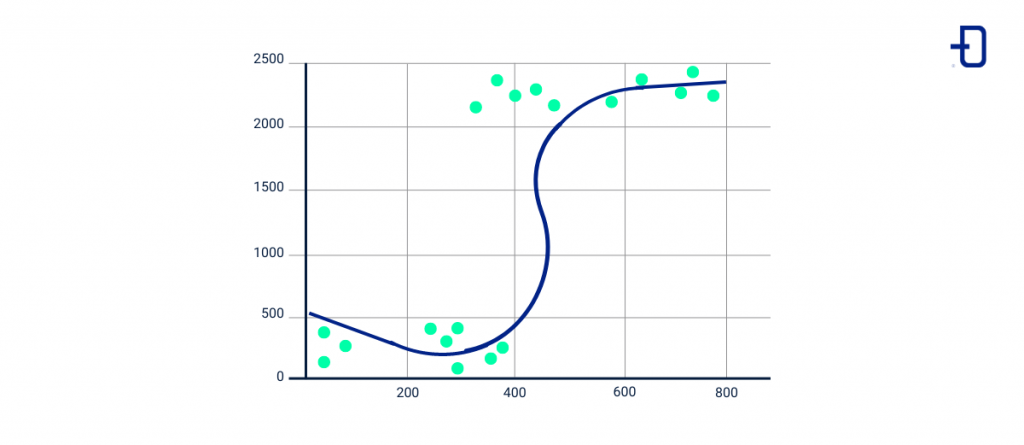
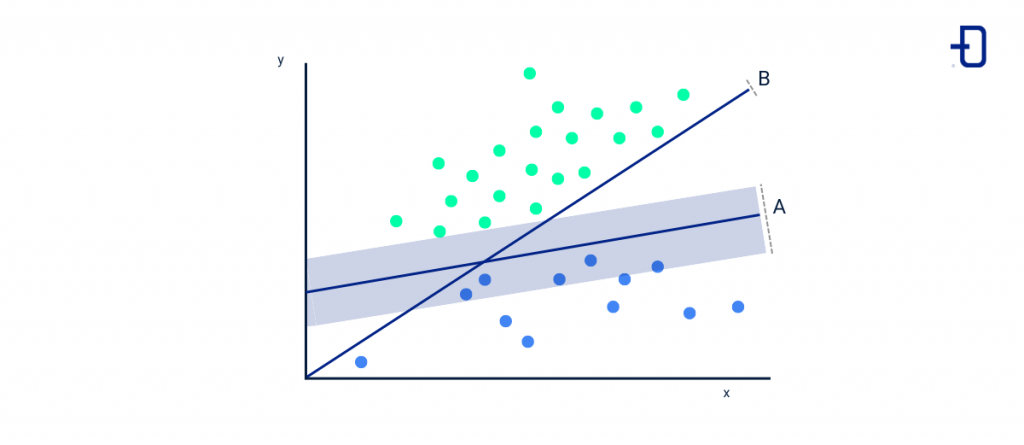
Algoritmo de Máquinas de Vectores de Soporte (SVM)
Las SVM son un algoritmo de clasificación binario que describe un hiperplano entre los dos puntos de datos más cercanos, lo que permite dividir las clases en dos grupos para maximizar la distancia entre ellas y que se puedan diferenciar rápidamente.
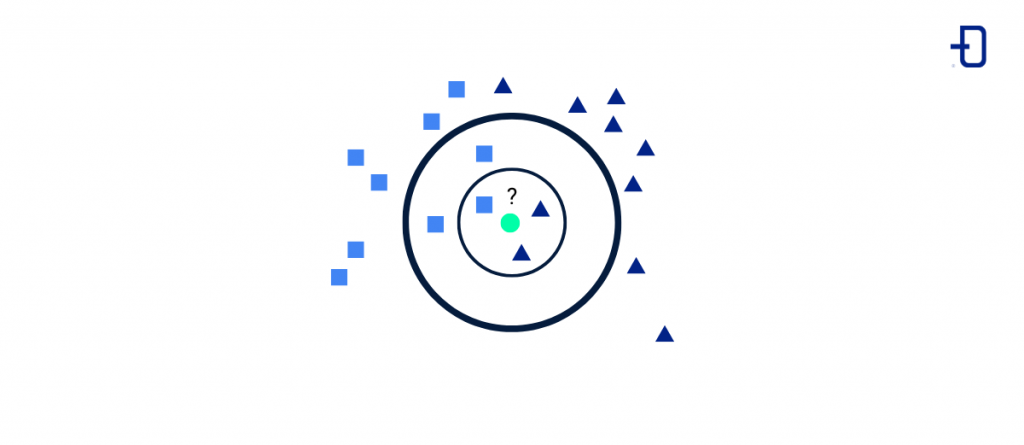
Algoritmo K-Nearest Neighbors (KNN)
KNN se traduce como ‘vecinos más cercanos’, lo que nos deja hacernos una idea de cómo funciona este algoritmo: agrupa los datos existentes y clasifica los nuevos inputs en función de la distancia al punto de datos más cercano.
Algoritmo de árboles de decisión
Los árboles de decisión se utilizan para resolver problemas tanto de regresión como de clasificación, y su estructura jerárquica y en forma de árbol está compuesta de: un nodo raíz, situado en la parte superior como punto de partida seguido de ramas o divisiones que, a su vez, se enlazan con otros nodos (hojas) hasta desembocar en un nodo final.
En el caso de los árboles de clasificación, se utilizan datos cuantitativos para obtener resultados categóricos; mientras que los árboles de regresión modelan resultados cuantitativos a partir de datos tanto cuantitativos como categóricos.
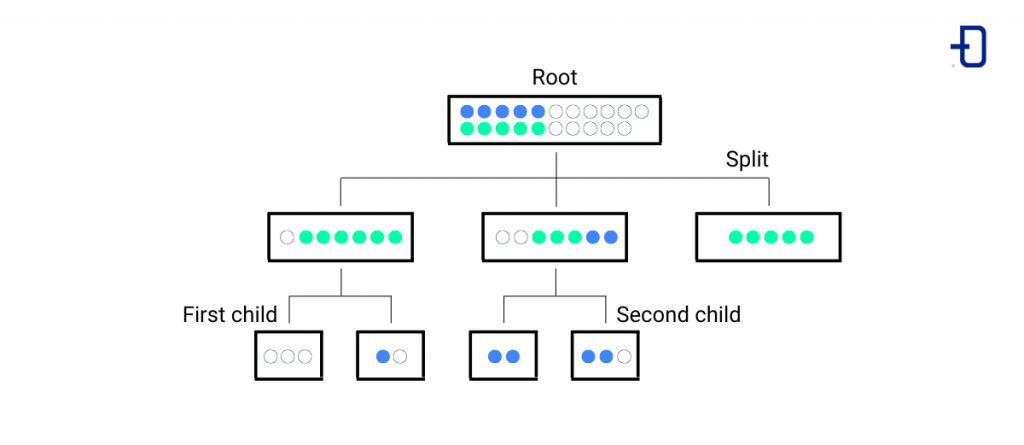
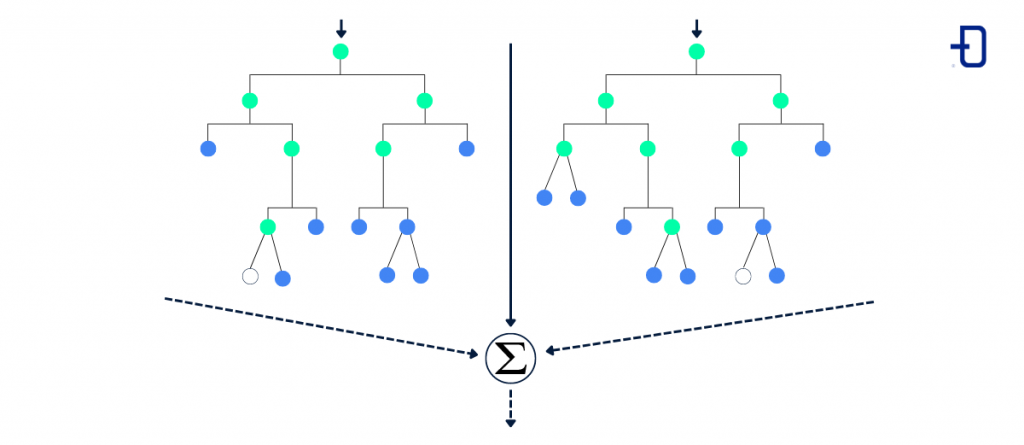
Algoritmo Random Forest
Este tipo de algoritmo está basado en los árboles de decisión pero, en este caso, el bosque aleatorio o random forest construye varios árboles y combina sus resultados para seleccionar cuál es la ruta óptima en un escenario de clasificación o predicción.
Aprendizaje No Supervisado
Al contrario que en el caso anterior, en el aprendizaje no supervisado los datos no están etiquetados, por lo que el modelo buscará patrones ocultos dentro de los mismos para crear sus propias etiquetas. Su función es crear relaciones y agrupaciones entre aquellos datos que se asemejen entre sí.
Los algoritmos más utilizados en aprendizaje no supervisado son el K-Means y el Naïve Bayes, que se encargan de agrupar la información disponible y los nuevos puntos de datos para encontrar relaciones entre ellos.
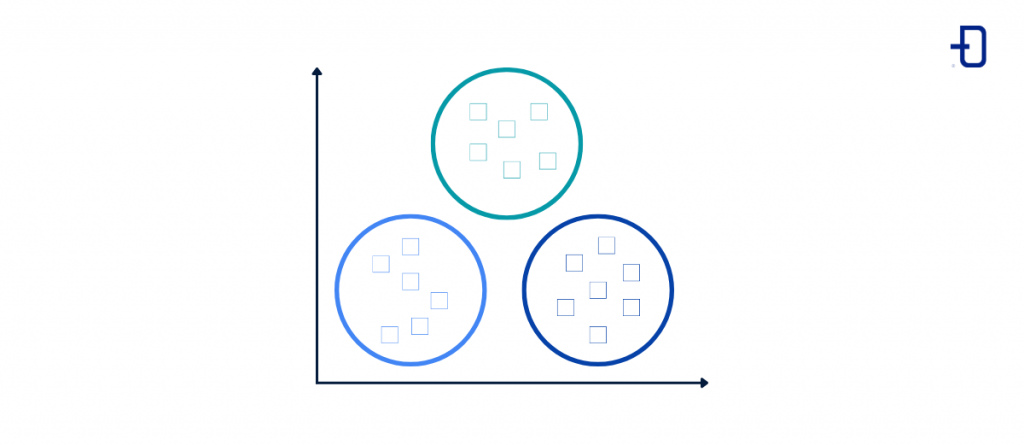
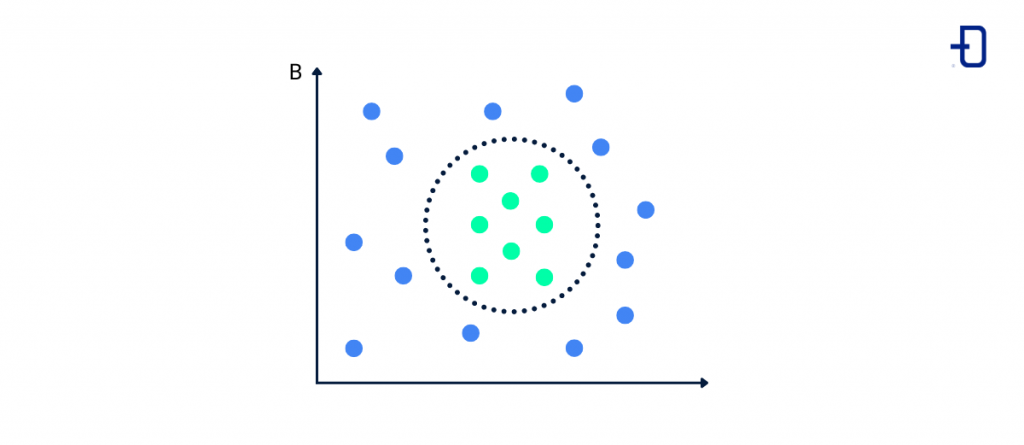
Algoritmo K-Means
El K-Means es quizás el algoritmo más utilizado en aprendizaje no supervisado y permite separar o clasificar los datos en “k” grupos o clústeres para descubrir patrones ocultos en ellos.
Los datos que hay en cada clúster son homogéneos entre ellos y heterogéneos con respecto a los de otros clústeres. Es, por tanto, una forma de agrupar datos en función de las características similares que tengan entre sí.
Algoritmo Naïve Bayes
Este método de clasificación basado en el Teorema de Bayes permite calcular la probabilidad de que se produzca un evento A bajo la condición de que ocurra un evento B.
Aprendizaje por refuerzo
El aprendizaje por refuerzo es otra de las variantes existentes en Machine Learning en la que el modelo aprende a través de la interacción entre un agente y un entorno.
Por medio de ensayo y error, el agente desarrolla su proceso de aprendizaje en función de las consecuencias que se derivan de las acciones en un entorno específico. Es, pues, un aprendizaje conductual donde el algoritmo dirige al usuario hacia el mejor resultado.
Esta técnica puede verse como un proceso de decisión de Markov, donde la probabilidad de que suceda un evento depende exclusivamente del evento inmediato anterior.
Entre los algoritmos más importantes de esta variante destacan el Q-Learning y el Deep Q-Learning, pero en lugar de detenernos a explicar en líneas generales cada uno de ellos, recomendamos leer estos dos posts donde se desarrollan con más detalle: Aprendizaje por refuerzo: Q-Learning y Aprendizaje por refuerzo profundo: DQN.
Conclusión
¿Qué se puede conseguir a través del Machine Learning? Gracias a los algoritmos de aprendizaje automático, es posible analizar información con el objetivo de responder preguntas o resolver problemas que son demasiado complejos para hacerlo mediante un análisis manual o tradicional.
Si te ha gustado el post, te animamos a visitar la categoría Algoritmos para ver otros artículos similares a este y a compartirlo en redes. ¡Hasta pronto!
