
Machine learning is perhaps the most popular branch of Artificial Intelligence and uses a series of algorithms whose methodology is based on carrying out a massive analysis of data in order to learn from it and, finally, find the solution to a complex problem.
What are the types of machine learning algorithms?
Machine Learning algorithms are classified into three different categories of learning, depending on the type of case we are dealing with or the problem we are trying to solve: supervised learning, unsupervised learning and reinforcement learning.
Below, we will define what each of them consists of, as well as the most commonly used algorithms in each area.
Supervised Learning
The main difference between the types of machine learning lies in the type of data they handle. In supervised learning, the Machine Learning algorithm is fed with previously labelled data, which means that the value of the target attribute of that data is known.
This will allow the model to decipher the existing patterns in the data and learn through them to make a prediction of the outcome when provided with new information.
The most commonly used algorithms in supervised learning are linear regression, logistic regression, support vector machines (SVM), K-Nearest Neighbors (KNN), decision trees and random forests.
Linear Regression Algorithm
The linear regression algorithm is one of the most popular algorithms in Machine Learning and is used to describe the trend in a dataset by means of a straight line.
Linear regression allows to show or know the relationship between two variables to make predictions as accurate as possible.
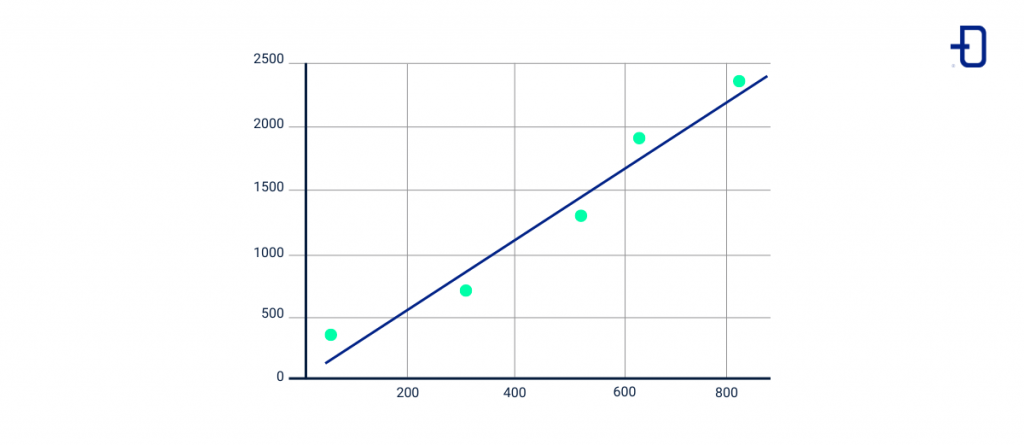
In a previous article in our blog, we showed an example of how to implement linear regression with Python.
Logistic Regression Algorithm
In the case of logistic regression algorithms, the data describes a continuous S-shaped curved line and uses a sigmoid function to analyze the data and predict discrete classes in a dataset.
Although linear and logistic regression may appear visually similar, the difference between the two is that linear regression deals with numerical predictions to look for relationships between variables, while logistic regression is used for binary classification of two discrete classes.
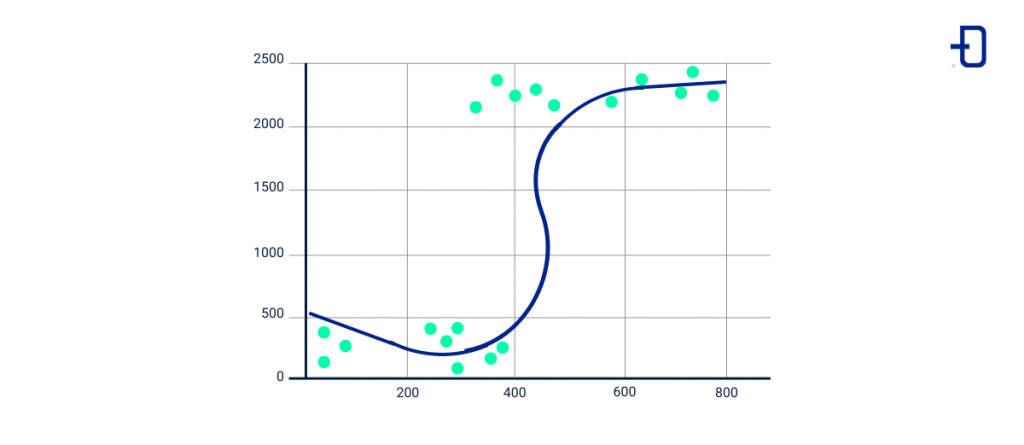
Support Vector Machines (SVM) Algorithm
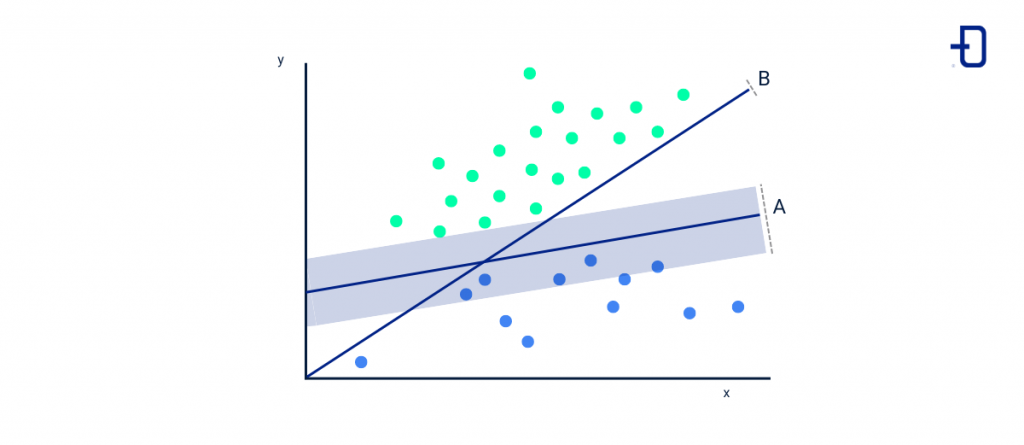
SVMs are a binary classification algorithm that describes a hyperplane between the two closest data points, allowing classes to be divided into two groups to maximize the distance between them so that they can be quickly differentiated.
K-Nearest Neighbors (KNN) algorithm
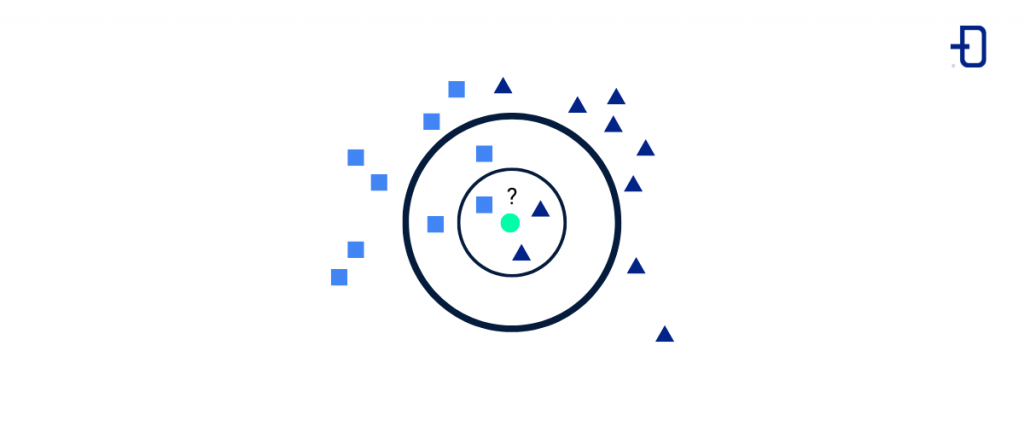
KNN means ‘nearest neighbours’, which gives an idea of how this algorithm works: it clusters existing data and ranks new inputs based on the distance to the nearest data point.
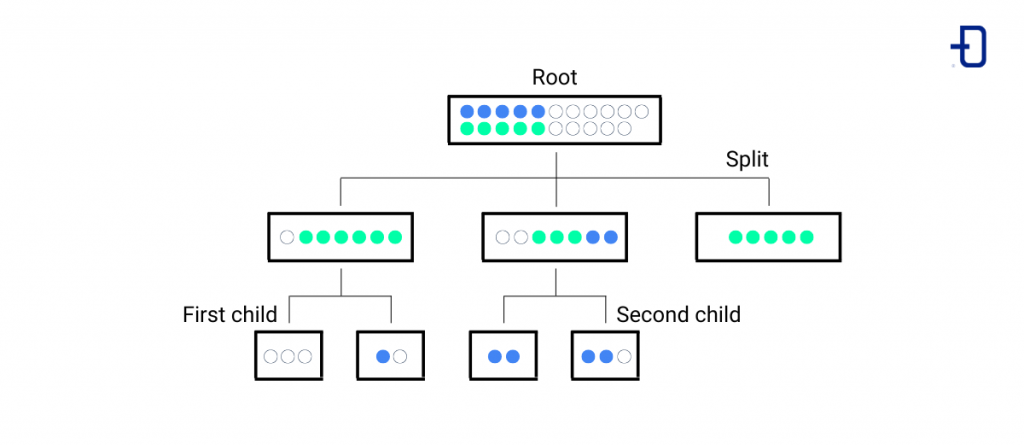
Decision tree algorithm
Decision trees are used to solve both regression and classification problems, and their hierarchical, tree-like structure is composed of: a root node at the top as a starting point followed by branches or splits which, in turn, link to other nodes (leaves) until they lead to a final node.
In the case of classification trees, quantitative data are used to obtain categorical results; while regression trees model quantitative results from both quantitative and categorical data.
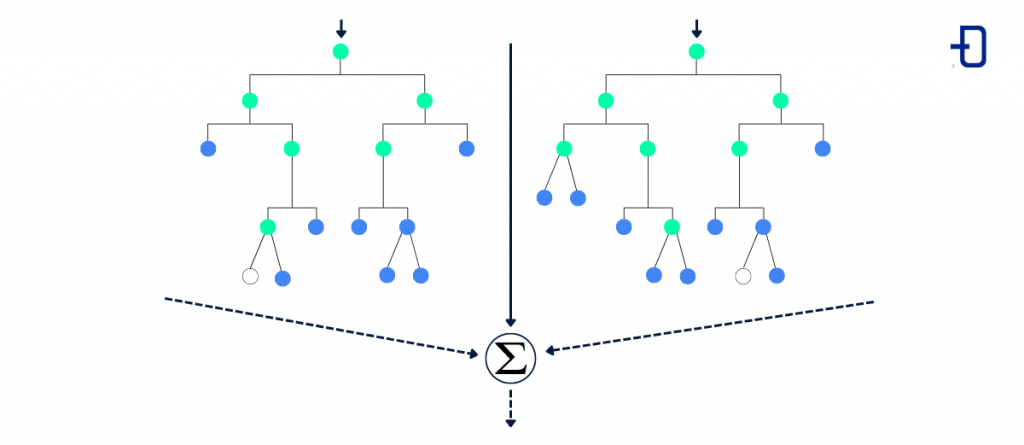
Random Forest Algorithm
This type of algorithm is based on decision trees but, in this case, the random forest constructs several trees and combines their results to select the optimal route in a classification or prediction scenario.
Unsupervised Learning
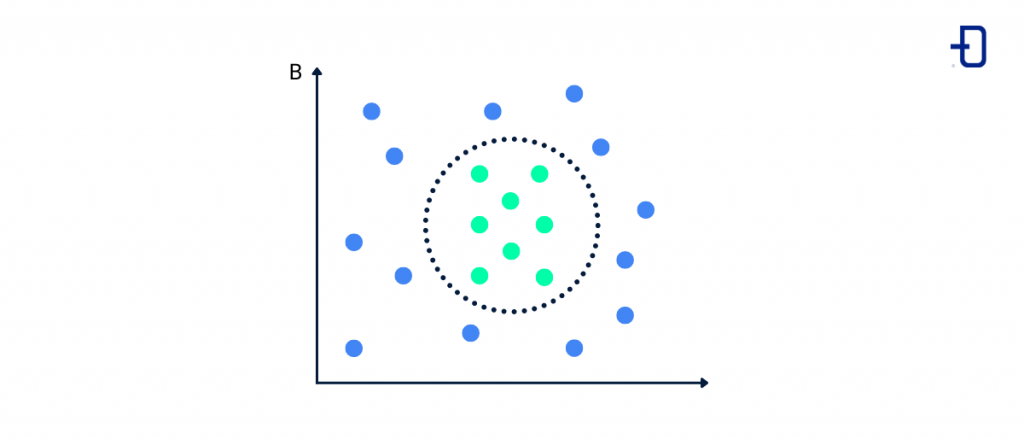
Unlike the previous case, in unsupervised learning the data is not labelled, so the model will look for hidden patterns within the data to create its own labels. Its function is to create relationships and clusters between data that are similar to each other.
The most commonly used algorithms in unsupervised learning are K-Means and Naïve Bayes, which cluster available information and new data points to find relationships between them.
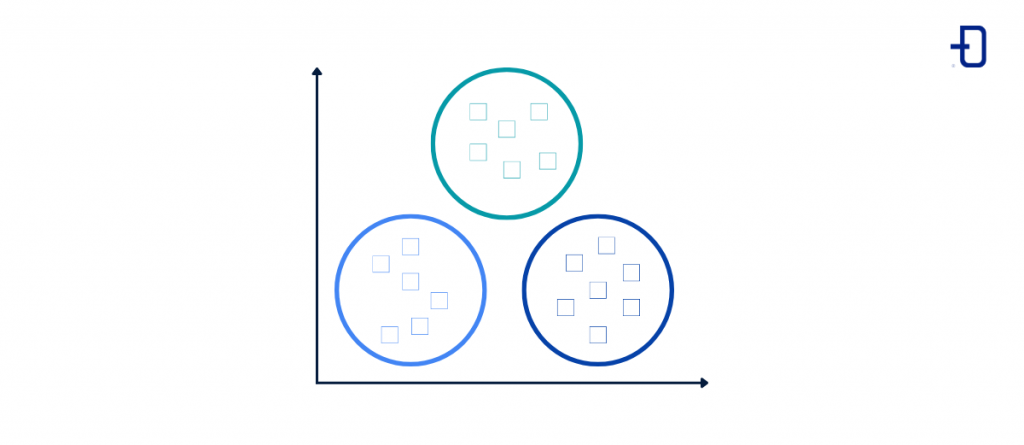
K-Means Algorithm
K-Means is perhaps the most widely used algorithm in unsupervised learning and allows data to be separated or classified into “k” groups or clusters in order to discover hidden patterns in them.
The data in each cluster are homogeneous with respect to each other and heterogeneous with respect to other clusters. It is therefore a way of grouping data according to their similar characteristics.
Naïve Bayes Algorithm
This classification method based on Bayes’ Theorem allows to calculate the probability that event A occurs under the condition that event B occurs.
Reinforcement learning
Reinforcement learning is another variant of Machine Learning in which the model learns through the interaction between an agent and an environment.
Through trial and error, the agent develops its learning process based on the consequences of actions in a specific environment. Thus, it is a behavioural learning where the algorithm directs the user towards the best outcome.
This technique can be seen as a Markov decision process, where the probability of an event happening depends exclusively on the immediate preceding event.
Among the most important algorithms of this variant are Q-Learning and Deep Q-Learning, but instead of explaining each of them in general terms, we recommend reading these two posts where they are developed in more detail: Reinforcement learning: Q-Learning and Deep reinforcement learning: DQN.
Conclusion
What can be achieved through Machine Learning? Thanks to machine learning algorithms, it is possible to analyse information with the aim of answering questions or solving problems that are too complex to do so through manual or traditional analysis.
If you liked the post, we encourage you to visit the Algorithms category to see other articles similar to this one and to share it on social networks. See you soon!
