
En el post anterior sobre Aprendizaje por refuerzo, realizamos una introducción a este campo a través de una de sus técnicas más populares: el Q-learning. Establecimos las bases hablando de procesos de decisión de Markov, políticas y funciones de valor, y vimos una primera aproximación a este enfoque con su versión tabular.
En esta ocasión, extenderemos el Q-learning clásico con el uso de redes neuronales. Es por ello que si no estás familiarizado con los conceptos mencionados anteriormente, te recomendamos echarle un vistazo al artículo Aprendizaje por refuerzo: Q-learning. A su vez, también puede ser buena idea refrescar conceptos de Deep Learning con las siguientes entradas:
- Redes neuronales convolucionales aplicadas al juego Hungry Geese
- Creación de una red convolucional con Tensorflow
- El Perceptrón Simple: Implementación en Python
- Perceptrón Simple: Definición matemática y propiedades
Ha nacido una estrella
En el año 2015, DeepMind presenta DQN (Deep Q Network) y nace el campo que hoy conocemos como Deep Reinforcement Learning. Originalmente se aplicó a videojuegos de Atari, donde no solo batió el estado del arte si no que obtuvo resultados superiores a los de humanos expertos para asombro de todos.
En esta nueva arquitectura se reemplaza la q-table, en la que se almacenan los q-valores para cada par (estado, acción), por una red neuronal que aproxima el q-valor de realizar cada acción disponible en un estado. En la siguiente figura podemos ver los esquemas de cada versión:
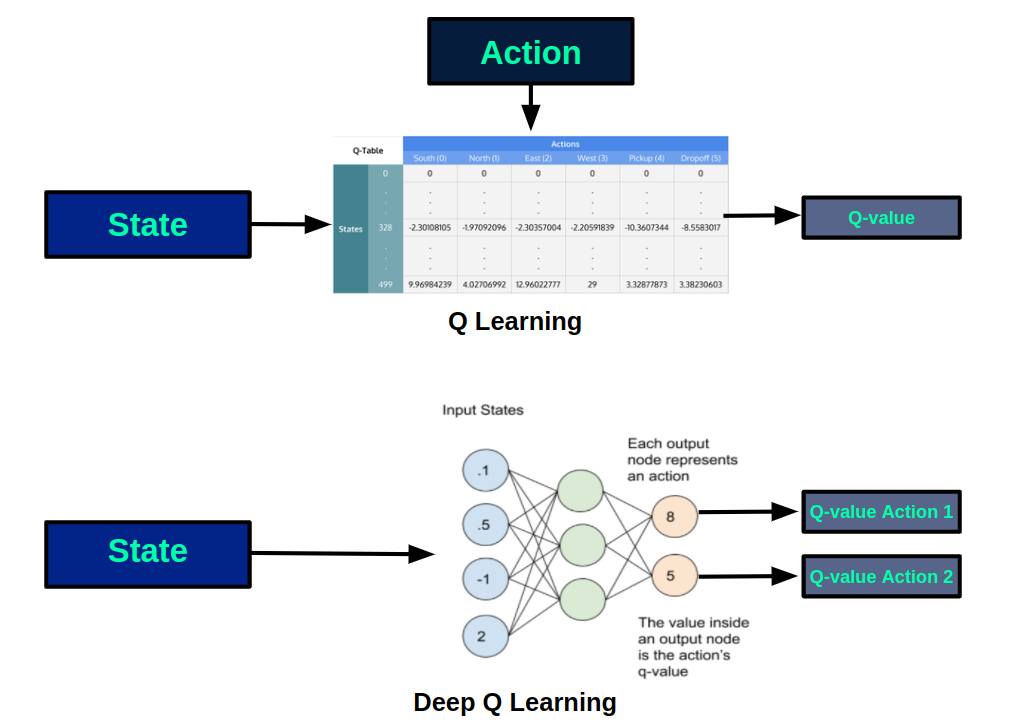
Usando una red neuronal tenemos múltiples beneficios frente a la versión tabular. De un lado, resulta imposible almacenar en una tabla los estados de entornos muy grandes o continuos, mientras que esto no es ningún problema para una red neuronal. Además, el aprendizaje obtenido en un estado se transfiere a estados similares, por lo que se podrán hacer buenas estimaciones para estados que no han sido visitados con anterioridad.
Entrenando el modelo
Antes de entrar con el algoritmo de entrenamiento, merece la pena explicar un concepto muy potente y usado en el mismo: Experience replay.
Interactuar con el entorno para obtener información sobre el impacto de las acciones tiene un coste. Si al obtener información la desechamos tras usarla, estamos perdiendo la oportunidad de volver a utilizarla en el futuro. Para aprovechar aún más la información obtenida, con Experience replay se propone ir almacenando la información de la experiencia obtenida, de forma que se pueda volver a usar en el futuro para aprender. De esta forma, la información obtenida (estado, acción, recompensa, estado siguiente), se almacena en una memoria de un tamaño determinado. Por ejemplo, podría implementarse con una cola en la que, cuando llega información de una nueva transición, sale la más antigua.
Durante el entrenamiento, usaremos algún criterio para balancear exploración y explotación e ir alimentando nuestra memoria con nueva información. A su vez, iremos tomando minibatchs de transiciones de la memoria, que usaremos para optimizar los parámetros del modelo, considerando el error entre la aproximación de nuestro modelo y lo que nos muestra la experiencia seleccionada.
A continuación se muestra el pseudocódigo del proceso de aprendizaje:

Conclusión
En este post hemos introducido el Deep Reinforcement Learning a través del modelo que lo originó: Deep Q Network. No solo hay que valorarlo por su rendimiento si no por lo que significó, ya que puso el foco en el uso de redes neuronales en el campo del aprendizaje por refuerzo, dando lugar a un sinfín de nuevos enfoques y líneas de investigación.
Si te ha gustado este post, te animamos a que visites la categoría Algoritmos para ver otros artículos similares a este y a que lo compartas en redes sociales. ¡Hasta pronto!
