
Apache Airflow es una herramienta de código abierto diseñada para la orquestación de flujos de trabajo especialmente útil en el campo de la ingeniería de datos. Los DAGs se definen en ficheros de Python y establecen la relación y dependencias entre las tareas a ejecutar. Puedes echar un vistazo a este otro post donde hacíamos una introducción a los Conceptos Básicos de Apache Airflow.
Esta herramienta permite al usuario definir cuándo y cómo se van a ejecutar estas tareas a través del componente scheduler, que se encarga de interpretarlo y lanzarlas cuando corresponda. En este artículo, se exploran las diferentes opciones que proporciona Airflow para programar un DAG y que se pueden separar en dos grupos: las programaciones basadas en tiempo (cron y timetables) y las basadas en eventos (triggers y datasets).
Nota: Desde la versión 3.0 de Airflow, el concepto de Dataset ha sido renombrado a Asset. Aunque sigue siendo lo mismo, puedes explorar el post Airflow 3 Scheduling: Timetables, Assets y Event-Driven pipelines para ver todos los detalles.
¿Qué es un Scheduler en Airflow?
En Airflow se puede definir el schedule del DAG como una expresión de cron para lanzar DAGRuns de forma periódica. Esta es la manera más sencilla de programar un DAG. Una expresión de cron está compuesta por cinco campos separados por espacios que representan, por orden, minutos, horas, días del mes, meses y días de la semana. Estos cinco campos describen el momento en el que se debería lanzar el DAG.
Un ejemplo podría ser un proceso que se quiera lanzar cada día a las 12:00 del mediodía, es decir, que se lance el DAG cuando la hora sea 12 y el minuto sea 0. Se puede pasar la expresión cron como string al parámetro schedule en la definición del DAG de la siguiente manera:
dag = DAG(
dag_id='dag_with_cron_schedule',
start_date=datetime(2024, 1, 1),
schedule='00 12 * * *'
)Cron proporciona también caracteres para definir para cada valor (\*), rangos (-), listas (,), etc. Este DAG se lanzaría los días entre semana a las 7:00 de la mañana y se repetiría cada 5 minutos hasta las 7:20:
dag = DAG(
dag_id='wake_me_up',
start_date=datetime(2024, 1, 1),
schedule='00-20/5 7 * * 1-5'
)En la UI de Airflow, en la pestaña Browse > DAG Runs se puede ver las DAGRuns generadas:
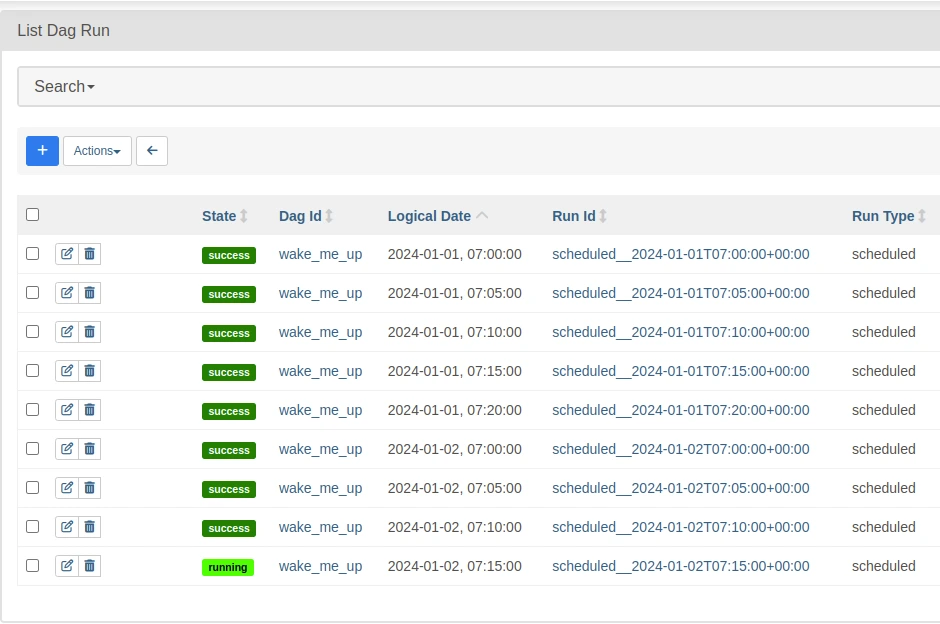
Adicionalmente, también se puede programar los DAGs con valores preestablecidos de cron. Algunos ejemplos son @hourly, @daily o @weekly. A estos se suman algunos valores propios de Airflow:
- @continous: se crea una nueva DAGRuns cuando acaba la anterior.
- @once: se crea solo una DAGRun.
- None: el scheduler no crea ninguna DAGRun. Esta opción se puede utilizar cuando el DAG se activa de forma externa.
Cron vs Timedelta
Finalmente, si se quiere ejecutar el DAG en intervalos fijos, también se pueden utilizar objetos timedelta, de la librería datetime. Para entender la diferencia entre cron y timedelta, se crean dos DAGs con start_date igual a 2024-01-01 00:15 que se ejecuta cada 30 minutos. Con cron se utiliza la expresión schedule="*/30 * * * *" y estas son las DAGRuns ejecutadas:
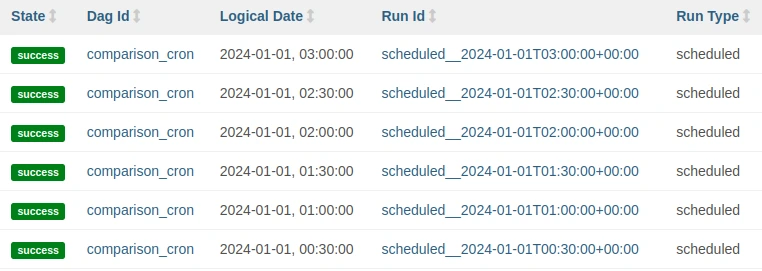
Con timedelta se utiliza schedule=timedelta(minutes=30) y estas son las DAGRuns ejecutadas:
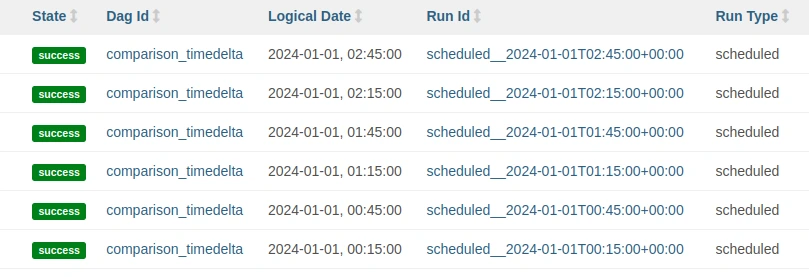
Se puede observar que cuando se utiliza timedelta las horas de las ejecuciones se alinean con la hora de start_date. Este no es el caso cuando se utiliza una expresión cron.
Timetables: Qué son y cuándo usarlas
En ocasiones, las opciones de cron y timedelta no serán suficientes para establecer la programación deseada de un DAG o su definición en una expresión de cron sería muy compleja. Para estos casos, a partir de la versión de Airflow 2.2, se pueden definir schedules personalizados utilizando timetables. Las timetables son el objeto básico con que el scheduler programa las tareas. De hecho, cuando se utilizan expresiones cron o timedeltas, Airflow crea una timetable por detrás (CronDataIntervalTimetable y DeltaDataIntervalTimetable, respectivamente).
Crear una Timetable personalizada
Para definir una timetable personalizada, se debe crear una clase que herede de Timetable e implemente los métodos next_dagrun_info y infer_manual_data_interval. En next_dagrun_info se establece cómo se calcula el intervalo de la siguiente DAGRun en función de la última DAGRun ejecutada y de los parámetros start_date, end_date y catchup. En infer_manual_data_interval se determina como definir el intervalo en caso de ejecución manual.
Por ejemplo, para determinar que si se lanza una ejecución a las 8:46, esto se mapee a un intervalo (por ejemplo, el intervalo de 0:00 a 8:00). Si la timetable necesita de parámetros adicionales para el constructor (__init__), también se deberán ajustar los métodos serialize y deserialize.
En el siguiente ejemplo, se quiere un DAG que se ejecute cada 8 horas durante los días entre semana pero que en el fin de semana solo se ejecute una vez al día. Esto no se puede representar con una expresión de cron porque en días diferentes se ejecuta en horas diferentes. Para ello, se crea una timetable personalizada. En este caso, se han reutilizado los métodos next_dagrun_info e infer_manual_data_interval de _DataIntervalTimetable, que es la base de las timetables CronDataIntervalTimetable y DeltaDataIntervalTimetable descritas antes.
from __future__ import annotations
from airflow.plugins_manager import AirflowPlugin
from airflow.timetables.base import DataInterval, TimeRestriction, DagRunInfo
from airflow.timetables.interval import _DataIntervalTimetable
from pendulum import DateTime
class CustomTimetable(_DataIntervalTimetable):
"""Every 8 hours during workdays. Every 24 hours during weekends"""
WORKDAY_DELTA_HOURS = 8
WEEKEND_DELTA_HOURS = 24
def _get_prev(self, current: DateTime) -> DateTime:
if current.subtract(seconds=1).weekday() >= 5:
return current.subtract(hours=self.WEEKEND_DELTA_HOURS)
else:
return current.subtract(hours=self.WORKDAY_DELTA_HOURS)
def _get_next(self, current: DateTime) -> DateTime:
if current.weekday() >= 5:
return current.add(hours=self.WEEKEND_DELTA_HOURS)
else:
return current.add(hours=self.WORKDAY_DELTA_HOURS)
def _align_to_prev(self, current: DateTime) -> DateTime:
if current.weekday() >= 5:
# Align to the start of the current day
return current.start_of('day')
else:
# Align to the last workday_delta_hours interval in the day
prev_hour = (current.hour // self.WORKDAY_DELTA_HOURS) * self.WORKDAY_DELTA_HOURS
return current.start_of('day').set(hour=prev_hour)
def _align_to_next(self, current: DateTime) -> DateTime:
return self._get_next(self._align_to_prev(current))
def _skip_to_latest(self, earliest: DateTime | None) -> DateTime:
current_time = DateTime.utcnow()
end = self._align_to_prev(current_time)
start = self._get_prev(end)
return max(start, self._align_to_next(earliest))
def infer_manual_data_interval(self, *, run_after: DateTime) -> DataInterval:
end = self._align_to_prev(run_after)
start = self._get_prev(end)
return DataInterval(start=start, end=end)
def next_dagrun_info(self, *, last_automated_data_interval: DataInterval | None, restriction: TimeRestriction) -> DagRunInfo | None:
return super().next_dagrun_info(last_automated_data_interval=last_automated_data_interval, restriction=restriction)
class CustomTimetablePlugin(AirflowPlugin):
name = "custom_timetable_plugin"
timetables = [CustomTimetable]En el código anterior, se han implementado con la lógica descrita anteriormente los métodos _get_prev, _get_next, _align_to_prev, _align_to_next y _skip_to_latest, que son los que usa _DataIntervalTimetable para definir next_dagrun_info y infer_manual_data_interval. En concreto, _get_prev y _get_next se utilizan para saltar de una fecha de DAGRun a la anterior o a la siguiente, respectivamente.
Los métodos _align_to_prev y _align_to_next se utilizan para pasar de una fecha cualquiera a una alineada con la programación. Finalmente, _skip_to_latest se utiliza para determinar la primera DAGRun en caso de que el DAG esté configurado con catchup=False. En la siguiente imagen se pueden ver las DAGRuns creadas con schedule=CustomTimetable(), siendo día 6 y día 7 sábado y domingo, respectivamente:
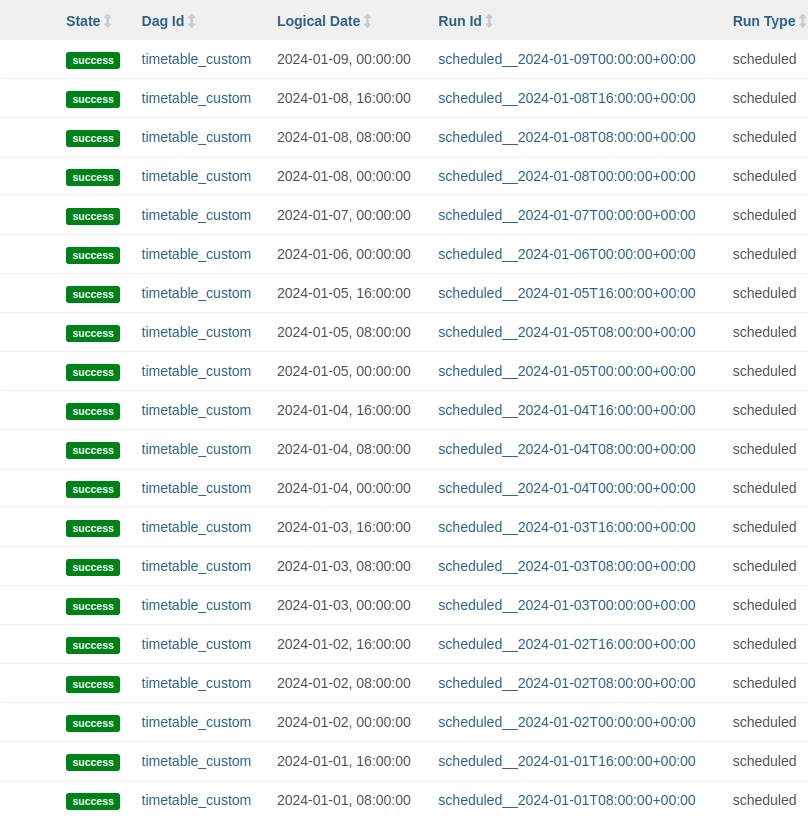
Triggers en Apache Airflow
Las opciones de cron, timedelta y timetables permiten definir DAGs que se ejecuten según momentos o intervalos de tiempo. No obstante, estas opciones no contemplan la posibilidad de lanzar DAGs basados en eventos. Si se quisiera lanzar un DAG dependiendo del estado de otro DAG, la única posibilidad dadas estas herramientas sería lanzar un DAG periódico y añadirle una tarea de sensor. Esto puede no ser óptimo si esta tarea se queda mucho tiempo esperando o si se quiere lanzar el DAG de manera irregular.
Una de las posibilidades para lanzar el DAG basándose en eventos es hacer un trigger a ese DAG. La manera más simple es acceder a la UI de Airflow y darle al botón de play. Esto generará una DAGRun manual. Otra forma es usar el operador TriggerDagRunOperator para, desde otro DAG, lanzar un trigger al DAG deseado. Esto puede ser útil si existen dos procesos que actualizan una tabla y hay un tercer proceso que lee de esta tabla.
Un ejemplo de tarea podría ser este:
trigger_task = TriggerDagRunOperator(
task_id='trigger_task',
trigger_dag_id='dag_triggered',
dag=dag
)En este caso, se empezaría a ejecutar el DAG dag_triggered cuando finalice esta tarea. A los DAGs que siempre se quieran ejecutar a través de triggers se les podrá asignar schedule=None.
En la UI, en Browse > DAG dependencies se puede encontrar una vista que muestra las relaciones entre DAGs. Se muestran los sensores, los triggers y los datasets, que se ven a continuación.
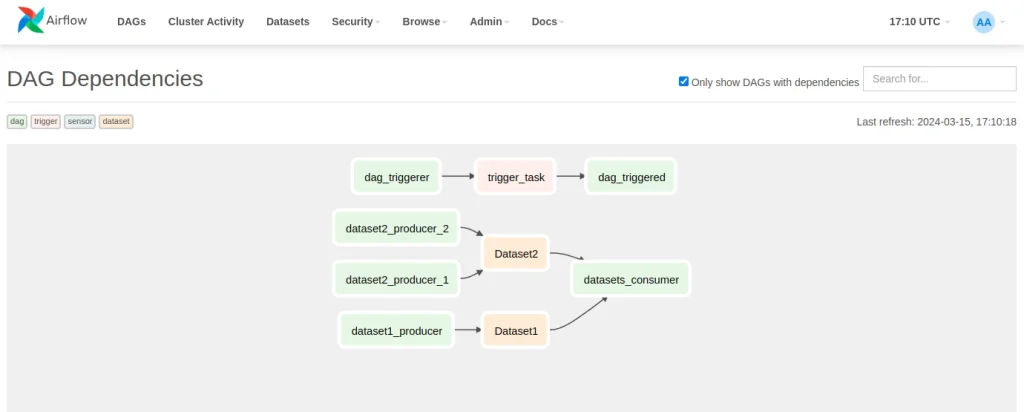
Datasets: Qué son y cómo funcionan
En la versión 2.4, Airflow introdujo el concepto de dataset. Los datasets son otra manera de ejecutar DAGs basándose en eventos mucho más flexible que los triggers, ya que cualquier tarea puede producir datasets y se pueden configurar el DAG para que necesite más de una condición para ejecutarse.
El funcionamiento de los datasets es muy simple: hay tareas productoras de datasets a través del parámetro outlets=[my_datasets] y DAGs que consumen datasets a través del parámetro schedule=[my_datasets]. Un dataset se define como una URI (por ejemplo, Dataset(«s3://dataset-bucket/example.csv«)). Conceptualmente, las tareas productoras modifican este csv y el DAG consumidor tiene que ejecutarse porque se han cambiado los datos. No obstante, Airflow no lee ningún fichero. A nivel práctico, un dataset es simplemente una string que identifica el objeto.
Ejemplo de tarea productora:
dag = DAG(
dag_id='dataset1_producer_1',
start_date=datetime(2024, 1, 1),
schedule='00 * * * *'
)
task_1 = PythonOperator(
task_id="task_1",
dag=dag,
python_callable=lambda: time.sleep(5),
outlets=[Dataset('Dataset1')]
)Ejemplo de DAG consumidor:
dag = DAG(
dag_id='datasets_consumer',
start_date=datetime(2024, 1, 1),
schedule=[Dataset('Dataset1'), Dataset('Dataset2')]
)Cuando un DAG depende de múltiples dataset, este se ejecutará cuando todos los datasets se hayan actualizado al menos una vez desde la última vez que el DAG se ejecutó. En la parte superior de la UI, Airflow proporciona una vista de datasets para poder visualizar las relaciones entre datasets y DAGs. En este ejemplo, hay un productor de Dataset1, dos productores de Dataset2 y un consumidor que lee de los dos datasets:
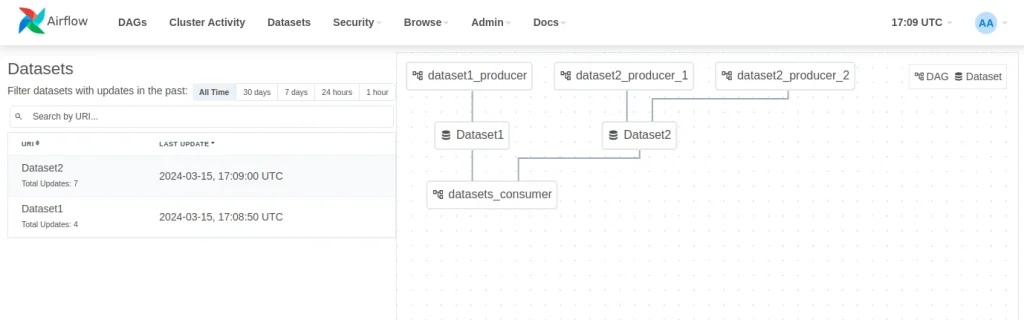
Conclusión
En este artículo, se han detallado las diferentes maneras en que se pueden desplegar los DAGs en Airflow. Por otro lado, hemos analizado ciertas opciones que existen para lanzar el DAG según momentos o intervalos de tiempo (cron y timetables) y otras que permiten lanzar el DAG basándose en eventos (triggers y datasets).
Visita el Github de Damavis para acceder a todos los ejemplos que hemos visto en este post.
¡Eso es todo! Si este artículo te ha resultado interesante, te animamos a visitar la etiqueta Airflow para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
