
Hace unas semanas, hablamos en nuestro blog sobre Reconocimiento de objetos con Deep Learning, explicando dicha técnica y algunos de sus algoritmos.
En este post, procederemos a analizar un área similar conocido como segmentación semántica de imágenes, una técnica de visión por computador en auge en campos tales como la medicina, la conducción automática o la cartografía por satélite.

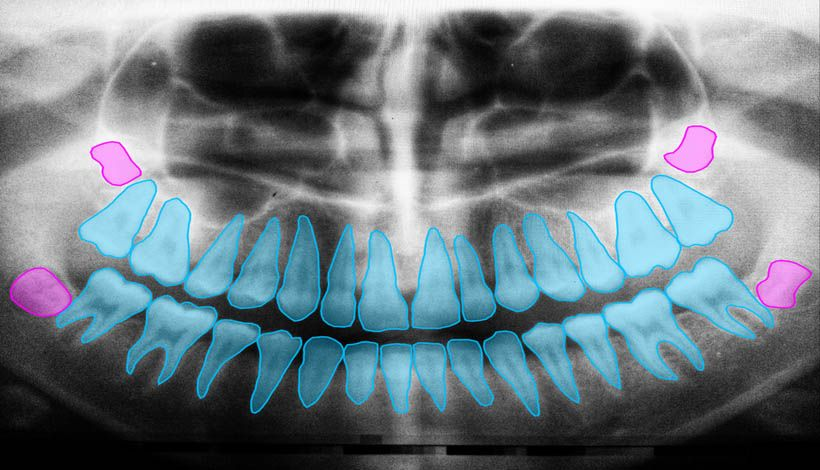
Diferencia entre segmentación de imágenes y detección de objetos
A primera vista, las dos técnicas pueden ser muy parecidas, pero en realidad son bastante diferentes.
La detección de objetos intenta detectar los límites de objetos formando cajas y, además, también intenta identificar dichos objetos. Por otra parte, la segmentación semántica de una imagen consiste en clasificar todos los píxeles de ésta en una de las clases posibles.

Como se puede observar en la imagen, a la hora de detectar objetos se ha encontrado un área rectangular, mientras que la segmentación semántica ha creado una máscara para su separación.
¿Cómo funciona la segmentación semántica de imágenes?
Hay muchas maneras de realizar la segmentación semántica de una imagen, pero la mayoría de técnicas siguen un patrón común que consiste en dividir el proceso en dos etapas conocidas como encoding y decoding. En este post, nos vamos a centrar en la arquitectura U-Net, un modelo desarrollado específicamente para la segmentación de imágenes médicas.
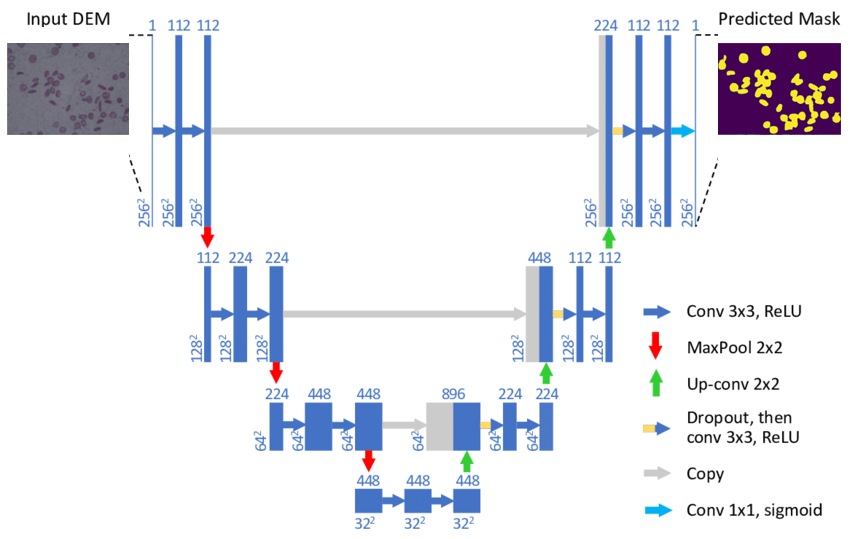
La primera etapa de encoding se basa en reducir la dimensionalidad espacial mediante capas de pooling combinadas con convoluciones. El objetivo de este proceso es crear un mapa de características de la imagen y reducir el número de parámetros de la red.
La segunda etapa de decoding es completamente simétrica a la primera aumentando la dimensionalidad de la imagen hasta llegar al tamaño original mediante la combinación de up-sampling y convoluciones.
Hay que destacar que las capas de la etapa de encoding están dando sus salidas a sus respectivas capas de la etapa de decoding. Esto se hace para mantener el contexto de la clasificación y así poder reducir la cantidad de información perdida al reducir la dimensionalidad de la imágen en la primera etapa.
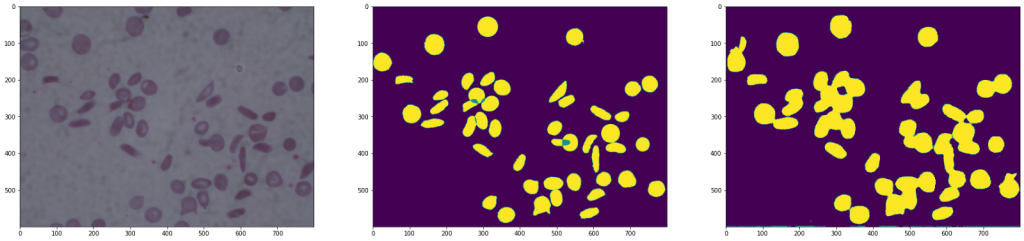
Resultado de una U-Net
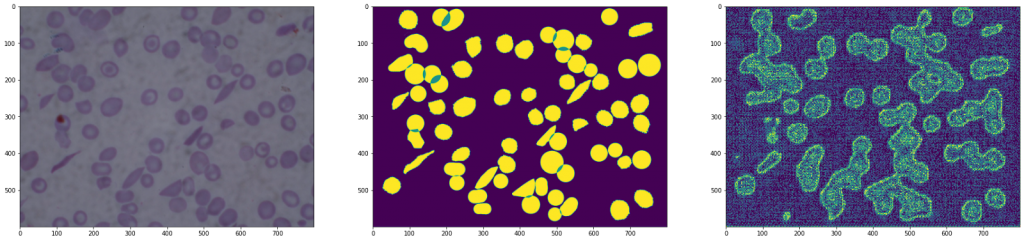
Resultado de una arquitectura sin la copia de los resultados
Tal y como se puede observar en las imágenes, la segunda arquitectura muestra una imagen con mucho ruido, ya que se ha perdido información al realizar el downsampling seguido del up-sampling.
Experimentación con PyTorch
Pytorch es un framework de machine learning basado en la librería Torch. Se utiliza tanto en aplicaciones de visión por computador como en NLP (Natural language Processing).
Primero vamos a descargar y cargar el dataset. Este se trata de un conjunto de imágenes de MRIs de 394 x 394.
url = 'https://mymldatasets.s3.eu-de.cloud-object-storage.appdomain.cloud/MRIs.zip'
wget.download(url)
with zipfile.ZipFile('MRIs.zip', 'r') as zip_ref:
zip_ref.extractall('.')
path = Path('./MRIs')
imgs = [path/'MRIs'/i for i in os.listdir(path/'MRIs')]
ixs = [i.split('_')[-1] for i in os.listdir(path/'MRIs')]
masks = [path/'Segmentations'/f'segm_{ix}' for ix in ixs]class Dataset(torch.utils.data.Dataset):
def __init__(self, X, y, n_classes=3):
self.X = X
self.y = y
self.n_classes = n_classes
def __len__(self):
return len(self.X)
def __getitem__(self, ix):
img = np.load(self.X[ix])
mask = np.load(self.y[ix])
img = torch.tensor(img).unsqueeze(0)
mask = (np.arange(self.n_classes) == mask[...,None]).astype(np.float32)
return img, torch.from_numpy(mask).permute(2,0,1)
dataset = {
'train': Dataset(imgs[:-100], masks[:-100]),
'test': Dataset(imgs[-100:], masks[-100:])
}
dataloader = {
'train': torch.utils.data.DataLoader(dataset['train'], batch_size=16, shuffle=True, pin_memory=True),
'test': torch.utils.data.DataLoader(dataset['test'], batch_size=32, pin_memory=True)
}
imgs, masks = next(iter(dataloader['train']))Ahora vamos a implementar el modelo U-Net. Este se trata de una de muchas variaciones posibles a la hora de implementarlo, así que os alentamos a escribir vuestra propia implementación.
def conv3x3_bn(ci, co):
return torch.nn.Sequential(
torch.nn.Conv2d(ci, co, 3, padding=1),
torch.nn.BatchNorm2d(co),
torch.nn.ReLU(inplace=True)
)
def encoder_conv(ci, co):
return torch.nn.Sequential(
torch.nn.MaxPool2d(2),
conv3x3_bn(ci, co),
conv3x3_bn(co, co),
)
class deconv(torch.nn.Module):
def __init__(self, ci, co):
super(deconv, self).__init__()
self.upsample = torch.nn.ConvTranspose2d(ci, co, 2, stride=2)
self.conv1 = conv3x3_bn(ci, co)
self.conv2 = conv3x3_bn(co, co)
def forward(self, x1, x2):
x1 = self.upsample(x1)
diffX = x2.size()[2] - x1.size()[2]
diffY = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, (diffX, 0, diffY, 0))
x = torch.cat([x2, x1], dim=1)
x = self.conv1(x)
x = self.conv2(x)
return x
class UNet(torch.nn.Module):
def __init__(self, n_classes=3, in_channels=1):
super().__init__()
c = [16, 32, 64, 128]
self.conv1 = torch.nn.Sequential(
conv3x3_bn(in_channels, c[0]),
conv3x3_bn(c[0], c[0]),
)
# Encoder
self.conv2 = encoder_conv(c[0], c[1])
self.conv3 = encoder_conv(c[1], c[2])
self.conv4 = encoder_conv(c[2], c[3])
# Decoder
self.deconv1 = deconv(c[3],c[2])
self.deconv2 = deconv(c[2],c[1])
self.deconv3 = deconv(c[1],c[0])
self.out = torch.nn.Conv2d(c[0], n_classes, 3, padding=1)
def forward(self, x):
# Encoder
x1 = self.conv1(x)
x2 = self.conv2(x1)
x3 = self.conv3(x2)
x = self.conv4(x3)
# Decoder
x = self.deconv1(x, x3)
x = self.deconv2(x, x2)
x = self.deconv3(x, x1)
x = self.out(x)
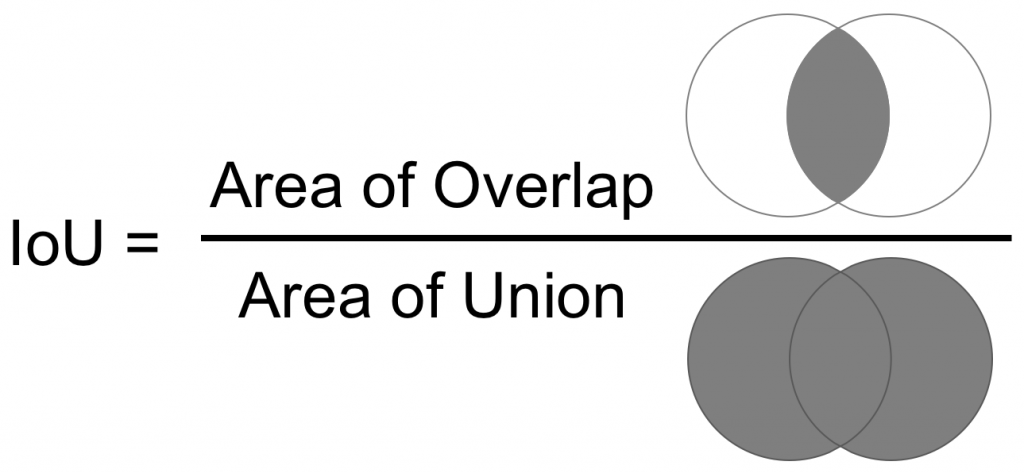
return xFinalmente, para el entrenamiento del modelo, vamos a utilizar la IoU (Intersection over Union), que se trata del ratio entre el área de solapamiento y la de unión entre las dos máscaras (la predicha y el ground truth).
Y hemos implementado la siguiente función de fit para realizar el entrenamiento:
device = "cuda" if torch.cuda.is_available() else "cpu"
def fit(model, dataloader, epochs=100, lr=3e-4):
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = torch.nn.BCEWithLogitsLoss()
model.to(device)
hist = {'loss': [], 'iou': [], 'test_loss': [], 'test_iou': []}
for epoch in range(1, epochs+1):
bar = tqdm(dataloader['train'])
train_loss, train_iou = [], []
model.train()
for imgs, masks in bar:
imgs, masks = imgs.to(device), masks.to(device)
optimizer.zero_grad()
y_hat = model(imgs)
loss = criterion(y_hat, masks)
loss.backward()
optimizer.step()
ious = iou(y_hat, masks)
train_loss.append(loss.item())
train_iou.append(ious)
bar.set_description(f"loss {np.mean(train_loss):.5f} iou {np.mean(train_iou):.5f}")
hist['loss'].append(np.mean(train_loss))
hist['iou'].append(np.mean(train_iou))
bar = tqdm(dataloader['test'])
test_loss, test_iou = [], []
model.eval()
with torch.no_grad():
for imgs, masks in bar:
imgs, masks = imgs.to(device), masks.to(device)
y_hat = model(imgs)
loss = criterion(y_hat, masks)
ious = iou(y_hat, masks)
test_loss.append(loss.item())
test_iou.append(ious)
bar.set_description(f"test_loss {np.mean(test_loss):.5f} test_iou {np.mean(test_iou):.5f}")
hist['test_loss'].append(np.mean(test_loss))
hist['test_iou'].append(np.mean(test_iou))
print(f"\nEpoch {epoch}/{epochs} loss {np.mean(train_loss):.5f} iou {np.mean(train_iou):.5f} test_loss {np.mean(test_loss):.5f} test_iou {np.mean(test_iou):.5f}")
return histmodel = UNet()
hist = fit(model, dataloader, epochs=30)Tras entrenar el modelo, podemos ver el siguiente resultado:
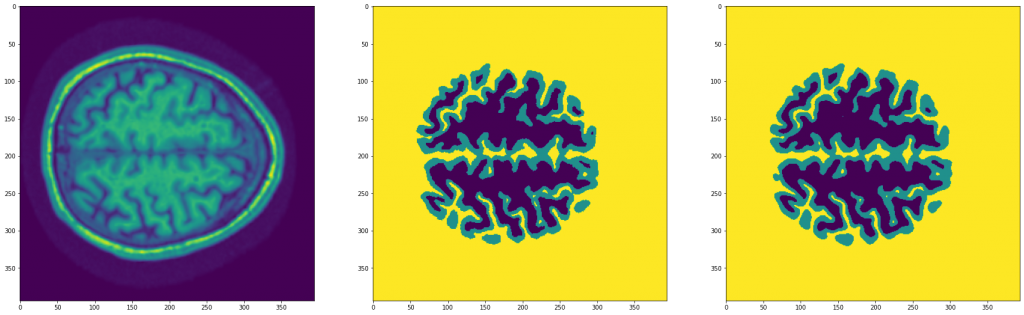
Como se puede observar, ha dado muy buenos resultados.
Conclusión
La segmentación semántica de imágenes es un campo de la visión por computador muy útil e interesante, cuyos usos podrán traer grandes beneficios en campos de investigación y desarrollo muy distintos entre ellos.
En este post, nos hemos centrado en la U-Net debido a su excelente rendimiento, pero hay que mencionar la gran variedad de modelos como por ejemplo FCN, SegNet y DeepLab que también son perfectamente válidos.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Algoritmos para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
