
Me encanta escribir posts para el blog de Damavis porque me permite compartir mi pasión por el Big Data y la consultoría. También es una gran manera de conectar con otros consultores y clientes potenciales. Me gusta poder brindar mi perspectiva sobre el mercado y el sector, y espero sinceramente que mis posts sean útiles para quienes los leen.
No hay duda de que el Big Data está transformando la forma en que hacemos negocios, y eso es algo en lo que realmente creo. Tener la oportunidad de contribuir a esa conversación a través de este blog es un verdadero privilegio.
Explorando GPT-3
Este texto ha sido realmente escrito por GPT-3 y aquí explico cómo funciona. GPT-3 es una Inteligencia Artificial que se entrena para escribir textos en un determinado contexto. En el caso de este blog, se le dio como contexto el tema de la consultoría de Big Data, y GPT-3 aprendió a escribir sobre este tema de forma natural.
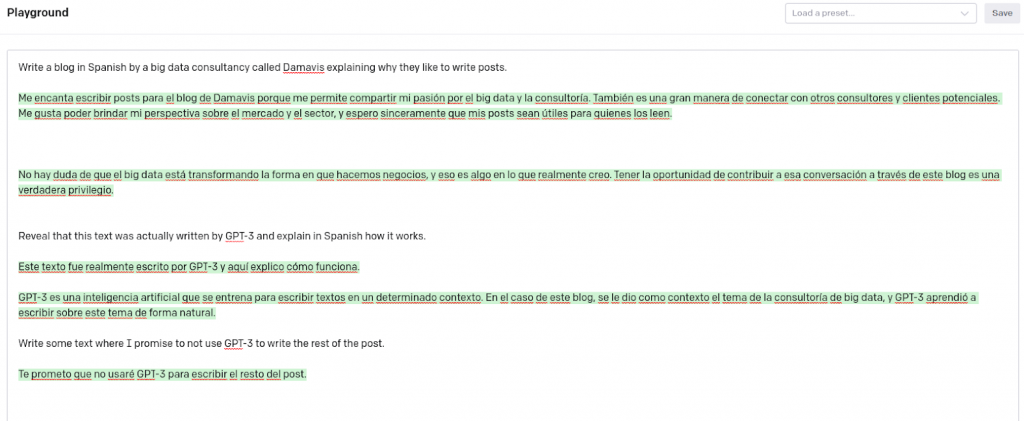
Como vemos en la imagen anterior del playground de OpenAI, los primeros párrafos han sido generados en español aportándole a la Inteligencia Artificial una pequeña explicación de lo que queríamos. También le hemos pedido que nos traduzca estos párrafos al inglés.

El campo de estudio que se encuentra detrás de esta Inteligencia Artificial y muchas otras es el Procesamiento del Lenguaje Natural (NLP). En este campo se analizan y se procesan todo tipo de textos desestructurados con el objetivo de entender sus contenidos, incluyendo los contextos implícitos que se esconden tras el lenguaje natural.
Una gran comprensión del lenguaje natural resulta muy útil para categorizar y archivar documentos, la generación texto (como el caso visto antes) y puede aportar un valor añadido a la construcción de modelos de inteligencia artificial. A continuación se explican algunas de las aplicaciones y técnicas más comunes y populares de NLP.
Análisis de sentimiento
El análisis de sentimientos se encarga de identificar, extraer y cuantificar información subjetiva de un texto. Es comúnmente utilizado para determinar la polaridad y la subjetividad de opiniones de clientes o usuarios de las redes sociales.
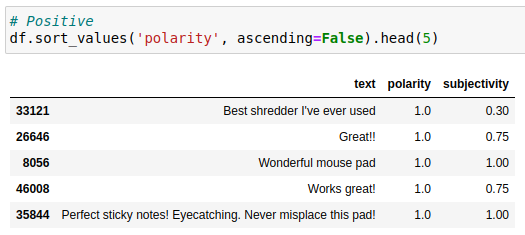
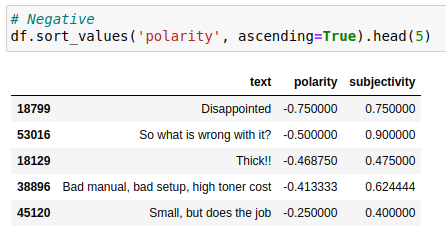
En el siguiente ejemplo se ha usado un subconjunto de datos de críticas de Amazon para productos de oficina y se ha hecho un análisis de sentimientos sobre el resumen de la crítica, haciendo uso de la librería TextBlob.
from textblob import TextBlob
import pandas as pd
pd.set_option('display.max_colwidth', None)
df = pd.read_json('data_nlp/Office_Products_5.json', lines=True)
df['text'] = df['summary']
df = df[['text']].sample(n=100)
df['polarity'] = df.text.apply(
lambda text: TextBlob(text).sentiment.polarity)
df['subjectivity'] = df.text.apply(
lambda text: TextBlob(text).sentiment.subjectivity)A continuación, se ven los resúmenes más positivos (izquierda) y los más negativos del subconjunto.
Segmentación de texto
La segmentación de texto o tokenización consiste en separar un texto en segmentos más cortos como palabras u oraciones. Si bien esta tarea es relativamente fácil para idiomas como el castellano o el inglés, algunas lenguas como el chino no necesariamente tienen una separación clara entre palabras. Siguiendo con el ejemplo anterior, se extraen las palabras y las frases.
from textblob.tokenizers import SentenceTokenizer, WordTokenizer
sentence_tokenizer = SentenceTokenizer()
word_tokenizer = WordTokenizer()
df.loc[:,'sentences'] = df.text.apply(
lambda text: TextBlob(text).tokenize(sentence_tokenizer))
df.loc[:,'words'] = df.text.apply(
lambda text: TextBlob(text).tokenize(word_tokenizer))
df.loc[:,'num_sentences'] = df.sentences.apply(len)
df.loc[:,'num_words'] = df.words.apply(len)
df.sort_values('num_sentences', ascending=False).head(5)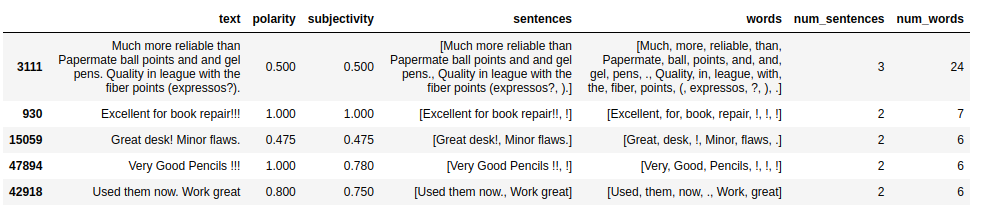
Lematización y Stemming
La lematización consiste en hallar el lema de una palabra, es decir, encontrar la forma de la palabra que encontraríamos en un diccionario. Por ello, un nombre en plural pasará a ser singular, un adjetivo será masculino y las conjugaciones verbales se representarán con el infinitivo. Este proceso implica saber la categoría gramatical (en inglés, part-of-speech, POS) de la palabra en el contexto de la oración.
Por otro lado, stemming es un proceso que consiste en reducir una palabra a su raíz. En el ejemplo, se pueden ver las diferencias entre los dos procesos.
df.loc[:,'words_lemmatized'] = df['words'].apply(
lambda word_list: word_list.lemmatize())
df.loc[:,'words_stemmed'] = df['words'].apply(
lambda word_list: word_list.stem())
df.loc[df['words']!=df['words_lemmatized'],
['text','words','words_lemmatized', 'words_stemmed']].head(5)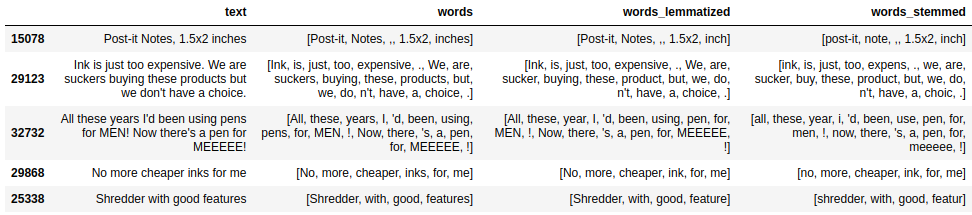
Reconocimiento de entidades nombradas
El Reconocimiento de Entidades Nombradas (NER) se encarga de encontrar entidades que se identifican con un nombre propio y a clasificarlas según su tipo. En muchas ocasiones, estas entidades tienen la primera letra de su nombre en mayúscula porque nos referimos a un objeto concreto de la vida real como una persona, una organización o un país. En el ejemplo a continuación, se muestra una implementación de esta técnica usando spaCy.
import spacy
from spacy.lang.en.examples import sentences
nlp = spacy.load("en_core_web_sm")
for s in sentences:
print(s)
for ent in nlp(s).ents:
print('\t', ent.text, '-', ent.label_)
Bolsa de palabras y TF-IDF
Una bolsa de palabras (bag-of-words, BOW) consiste en la representación de un documento mediante el conjunto de las palabras que contiene, sin importar el orden. Dicho de otra manera, cada palabra diferente del documento sería un elemento de la bolsa, donde también se almacena el número de veces que esta palabra se repite a lo largo del documento. En el ejemplo, se usa CountVectorizer de scikit-learn para obtener los recuentos por cada palabra y frase.
from sklearn.feature_extraction.text import CountVectorizer
examples = [
"John likes color blue but his favourite color is red",
"Jessica hates blue but likes green. However, green is not her favourite color",
"Joe loves red and blue. He dislikes green."
]
cv = CountVectorizer(stop_words='english')
matrix = cv.fit_transform(examples)
df_bow = pd.concat([
pd.DataFrame(examples, columns = ['sentence']),
pd.DataFrame.sparse.from_spmatrix(
matrix,
columns=cv.get_feature_names_out())], axis=1)
df_bow
Por otro lado, la frecuencia de término – frecuencia inversa de documento (TF-IDF) es una medida que refleja la importancia de una palabra dentro de un documento. Consiste en multiplicar dos términos: TF e IDF. Para el primero, se puede usar el recuento que se obtiene de la bolsa de palabras. El término IDF es una medida de cuánta información aporta una palabra, teniendo en cuenta el número de documentos analizados y el número de documentos que contienen dicha palabra:
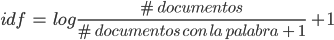
En el ejemplo, se usa TfidfVectorizer de scikit-learn para obtener el valor de TF-IDF por cada palabra y frase.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(examples)
df_tfidf = pd.concat([
pd.DataFrame(examples, columns = ['sentence']),
pd.DataFrame.sparse.from_spmatrix(
tfidf_matrix,
columns=cv.get_feature_names_out())], axis=1)
df_tfidf
Conclusión
En conclusión, el Procesamiento del Lenguaje Natural abarca una multitud de áreas, algunas de las cuales se han introducido aquí. La extracción de información de campos de texto puede ser de gran utilidad cuando se tienen datos de críticas o datos de Redes Sociales, ya que, en muchos otros casos, los campos de texto que no forman categorías no son explotados en Machine Learning.
Hasta aquí nuestro post de hoy. Si te ha parecido interesante, te animamos a visitar la categoría Data Science para ver todos los posts relacionados y a compartirlo en redes con tus contactos. ¡Hasta pronto!
