
I love writing posts for Damavis’s blog because it allows me to share my passion for Big Data and consulting. It’s also a great way to connect with other consultants and potential clients. I enjoy being able to provide my perspective on the market and the industry, and I sincerely hope that my posts are useful to those who read them.
There is no doubt that Big Data is transforming the way we do business, and that’s something I really believe in. Having the opportunity to contribute to that conversation through this blog is a real privilege.
Exploring GPT-3
This text has actually been written by GPT-3 and here I explain how it works. GPT-3 is an Artificial Intelligence that is trained to write texts in a given context. In the case of this blog, the context of Big Data consulting was given to it, and GPT-3 learned to write about this topic naturally.
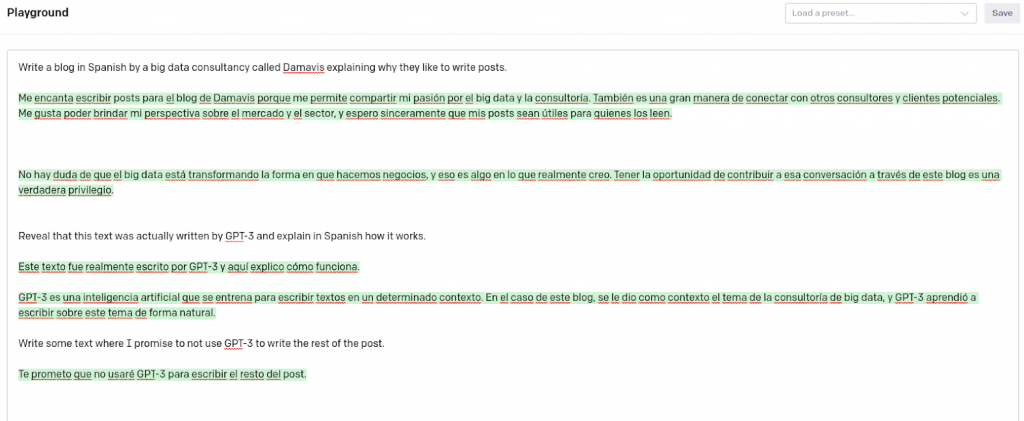
As we can see in the previous image of the OpenAI playground, the first paragraphs have been generated in Spanish, providing the Artificial Intelligence with a small explanation of what we wanted. We have also asked it to translate these paragraphs into English.

The field of study behind this Artificial Intelligence and many others is Natural Language Processing (NLP). In this field, all kinds of unstructured texts are analysed and processed in order to understand their contents, including the implicit contexts behind the natural language.
A strong understanding of natural language is very useful for categorising and archiving documents, text generation (as in the case seen above) and can bring added value to the construction of artificial intelligence models. Some of the most common and popular NLP applications and techniques are explained below.
Sentiment analysis
Sentiment analysis is concerned with identifying, extracting and quantifying subjective information from a text. It is commonly used to determine the polarity and subjectivity of customer or social media user opinions.
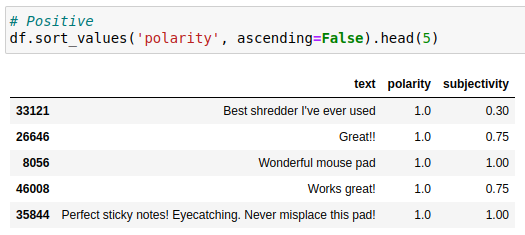
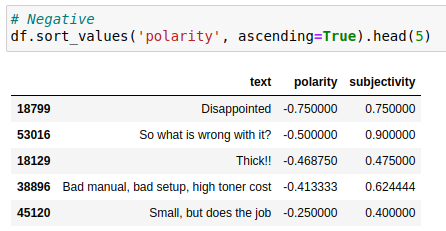
In the following example we have used a subset of Amazon review data for office products and performed sentiment analysis on the review summary, making use of the TextBlob library.
from textblob import TextBlob
import pandas as pd
pd.set_option('display.max_colwidth', None)
df = pd.read_json('data_nlp/Office_Products_5.json', lines=True)
df['text'] = df['summary']
df = df[['text']].sample(n=100)
df['polarity'] = df.text.apply(
lambda text: TextBlob(text).sentiment.polarity)
df['subjectivity'] = df.text.apply(
lambda text: TextBlob(text).sentiment.subjectivity)Below are the most positive (left) and the most negative summaries of the subset.
Text segmentation
Text segmentation or tokenisation consists of separating text into shorter segments such as words or sentences. While this task is relatively easy for languages such as English or Spanish, some languages such as Chinese do not necessarily have a clear separation between words. Following the example above, words and sentences are extracted.
from textblob.tokenizers import SentenceTokenizer, WordTokenizer
sentence_tokenizer = SentenceTokenizer()
word_tokenizer = WordTokenizer()
df.loc[:,'sentences'] = df.text.apply(
lambda text: TextBlob(text).tokenize(sentence_tokenizer))
df.loc[:,'words'] = df.text.apply(
lambda text: TextBlob(text).tokenize(word_tokenizer))
df.loc[:,'num_sentences'] = df.sentences.apply(len)
df.loc[:,'num_words'] = df.words.apply(len)
df.sort_values('num_sentences', ascending=False).head(5)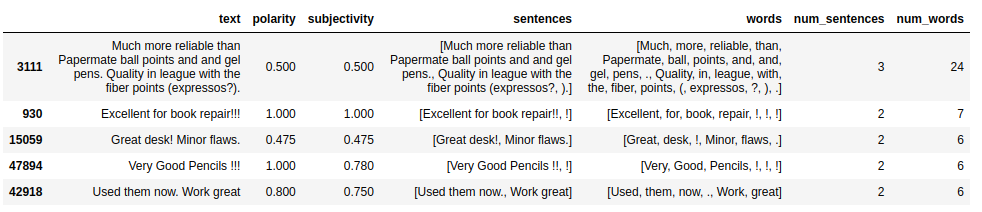
Lemmatisation and Stemming
Lemmatisation consists of finding the lemma of a word, that is, finding the form of the word that we would find in a dictionary. Thus, a plural noun becomes singular, an adjective becomes masculine and verb conjugations are represented by the infinitive. This process involves knowing the grammatical category (part-of-speech, POS) of the word in the context of the sentence.
On the other hand, stemming is a process of reducing a word to its root. In the example, you can see the differences between the two processes.
df.loc[:,'words_lemmatized'] = df['words'].apply(
lambda word_list: word_list.lemmatize())
df.loc[:,'words_stemmed'] = df['words'].apply(
lambda word_list: word_list.stem())
df.loc[df['words']!=df['words_lemmatized'],
['text','words','words_lemmatized', 'words_stemmed']].head(5)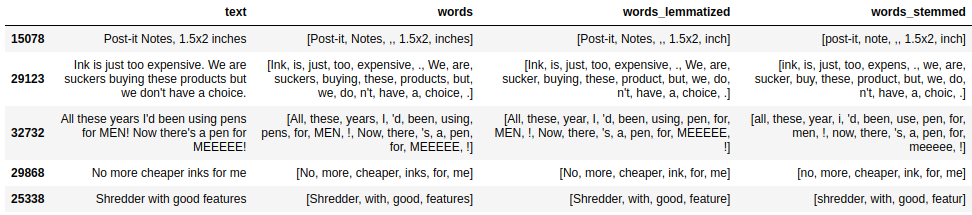
Named Entity Recognition
Named Entity Recognition (NER) is responsible for finding entities that are identified by a proper name and classifying them according to their type. In many cases, these entities have the first letter of their name capitalised because we are referring to a concrete real-life object such as a person, an organisation or a country. In the example below, an implementation of this technique using spaCy is shown.
import spacy
from spacy.lang.en.examples import sentences
nlp = spacy.load("en_core_web_sm")
for s in sentences:
print(s)
for ent in nlp(s).ents:
print('\t', ent.text, '-', ent.label_)
Bag-of-words and TF-IDF
A bag-of-words (BOW) is the representation of a document by the set of words it contains, regardless of the order. In other words, each different word in the document would be an element of the bag, where the number of times this word is repeated throughout the document is also stored. In the example, CountVectorizer from scikit-learn is used to get the counts for each word and phrase.
from sklearn.feature_extraction.text import CountVectorizer
examples = [
"John likes color blue but his favourite color is red",
"Jessica hates blue but likes green. However, green is not her favourite color",
"Joe loves red and blue. He dislikes green."
]
cv = CountVectorizer(stop_words='english')
matrix = cv.fit_transform(examples)
df_bow = pd.concat([
pd.DataFrame(examples, columns = ['sentence']),
pd.DataFrame.sparse.from_spmatrix(
matrix,
columns=cv.get_feature_names_out())], axis=1)
df_bow
On the other hand, term frequency – inverse document frequency (TF-IDF) is a measure that reflects the importance of a word within a document. It consists of multiplying two terms: TF and IDF. For the first one, the count obtained from the bag of words can be used. The IDF term is a measure of how much information a word provides, taking into account the number of documents analysed and the number of documents containing that word:
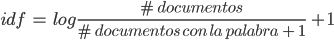
In the example, TfidfVectorizer from scikit-learn is used to obtain the TF-IDF value for each word and phrase.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(examples)
df_tfidf = pd.concat([
pd.DataFrame(examples, columns = ['sentence']),
pd.DataFrame.sparse.from_spmatrix(
tfidf_matrix,
columns=cv.get_feature_names_out())], axis=1)
df_tfidf
Conclusion
In conclusion, Natural Language Processing covers a multitude of areas, some of which have been introduced here. Extracting information from text fields can be very useful when you have review data or Social Network data, as in many other cases, text fields that do not form categories are not exploited in Machine Learning.
So far, this is the end of today’s post. If you found it interesting, we encourage you to visit the Data Science category to see all the related posts and to share it in networks with your contacts. See you soon!
