
¿Qué es MongoDB?
MongoDB es una base de datos NOSQL de código abierto. Esto implica que los datos no han de necesariamente seguir un esquema. Todos los datos son almacenados en un formato documental similar a JSON conocido como BSON o Binary JSON y tendrán un formato similar al siguiente:
{
_id: "123",
nombre: "Pepe",
email: "pepe@gmail.com",
}Este formato da una flexibilidad ideal para que MongoDB sea un candidato muy relevante en proyectos de Big Data. Esta idea se ve sustentada por el hecho de que MongoDB fue ya diseñado como una base de datos distribuída, lo cual implica que la alta disponibilidad y escalabilidad horizontal están ya presentes y se pueden aprovechar con facilidad.
Para imaginar la potencia de MongoDB podemos pensar en un caso como el almacenamiento de los resultados de una encuesta. Estas pueden tener preguntas anidadas en otras preguntas o tener un número variable de preguntas en cada tipo de encuesta. Estas casuísticas no son triviales en una base de datos SQL, pero se pueden modelar como listas de respuestas en MongoDB.
Instalación de MongoDB
MongoDB proporciona un clúster ya gestionado llamado MongoDB Atlas, es posible también realizar una instalación manual de MongoDB, a continuación describiremos las principales formas de instalación.
Instalación en Docker
Docker es un proyecto de código abierto que permite desplegar aplicaciones dentro de contenedores virtuales y autosuficientes.
Tras instalar Docker y Docker Compose, podemos crear una plantilla llamada mongo-docker.yml:
version: "3.8"
services:
mongo:
image: mongo:5.0
container_name: mongo
environment:
- MONGO_INITDB_ROOT_USERNAME=admin
- MONGO_INITDB_ROOT_PASSWORD=pass
restart: unless-stopped
ports:
- "27017:27017"
volumes:
- ./database/db:/data/db
- ./database/dev.archive:/Databases/dev.archive
- ./database/production:/Databases/production
mongo-express:
image: mongo-express
container_name: mexpress
environment:
- ME_CONFIG_MONGODB_ADMINUSERNAME=admin
- ME_CONFIG_MONGODB_ADMINPASSWORD=pass
- ME_CONFIG_MONGODB_URL=mongodb://admin:pass@mongo:27017/?authSource=admin
- ME_CONFIG_BASICAUTH_USERNAME=mexpress
- ME_CONFIG_BASICAUTH_PASSWORD=mexpress
links:
- mongo
restart: unless-stopped
ports:
- "8081:8081"Con esta plantilla definimos una instancia de MongoDB y una instancia de Mongo Express, un panel de administración que permite interactuar con la base de datos. Para ejecutar las aplicaciones debemos entrar el directorio que contiene la plantilla y ejecutar el comando:
docker-compose -f mongo-docker.yml upAsí, se descargará e instalará la versión 4.2 de MongoDB y Mongo Express la primera vez que se ejecute el comando, por lo que tardará un poco más. Cabe destacar que el clúster de MongoDB usará el usuario “admin” y la contraseña “pass” para la autenticación. Podremos ahora acceder al clúster de MongoDB a través de cualquier cliente de base de datos en el puerto 27017 o al portal web en http://localhost:8081 con el usuario y contraseña “mexpress”. Para apagar el clúster, podemos usar el comando:
docker-compose -f mongo-docker.yml downInstalación local
MongoDB está disponible en los mayores sistemas operativos y proporciona dos versiones principales, una versión para empresas basada en suscripción y una versión para la comunidad, la cual es gratuita y será usada.
La instalación se podrá realizar con el gestor de paquetes de cada sistema operativo y se puede encontrar una guía detallada en la documentación oficial.
Uso de un clúster en la nube
Se pueden usar instancias alojadas en servicios como Mongo Atlas los cuales cobrarán por norma general cuotas por almacenamientos y datos transferidos. Por norma general estos servicios proporcionarán panel de administración o herramientas para el manejo del clúster de MongoDB. En caso de Mongo Atlas, la principal herramienta será la Atlas CLI o su interfaz web. Además, proporciona un clúster gratuito para trabajar con la tecnología.
Interacción con un clúster de Mongo
Existen varios clientes con una interfaz gráfica, como Mongo Compass y Studio 3T (también conocido como Robo 3T). A lo largo de este artículo, usaremos Studio 3T en su versión gratuita para interactuar con MongoDB. Podemos conectarnos al clúster con la siguiente configuración (Usaremos el clúster levantado en docker):

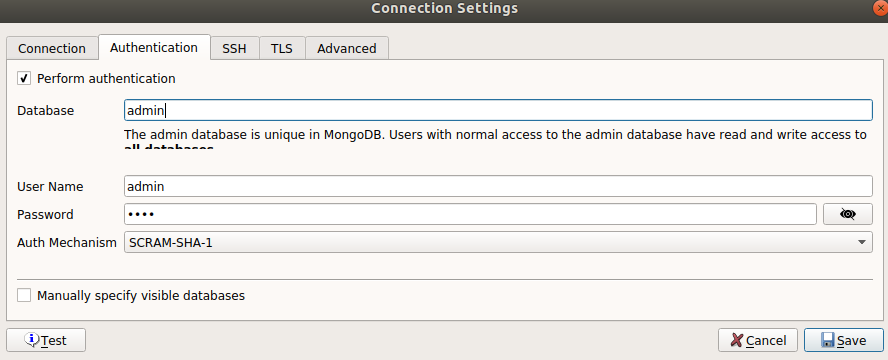
En este caso, podemos identificarnos como usuario administrador, ya que no hemos creado ningún otro usuario. Si quisiéramos hacerlo, se pueden seguir estas instrucciones para la creación de usuarios. En primer lugar, vamos a conectarnos al portal web en http://localhost:8081 y crear una nueva base de datos:
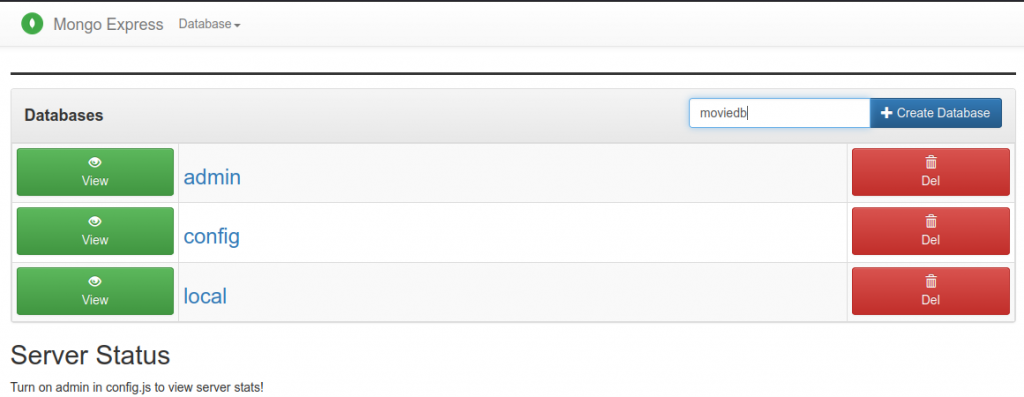
Tras darle al botón de create database, podemos abrir Robo 3T o el cliente elegido, seleccionar la nueva base de datos y hacer click derecho para abrir una instancia de Mongo Shell que trabajará sobre esta base de datos.

Vamos a crear una pequeña colección (equivalente a una tabla en SQL) con información de películas para trabajar con las operaciones elementales de MongoDB. Esta sentencia no es necesaria, ya que MongoDB también creará la colección cuando se insertan datos en esta por primera vez, sin embargo nos permitirá especificar opciones para tener mayor control:
db.createCollection('movies')Podemos insertar registros mediante la función insertOne o insertMany de la siguiente manera:
db.movies.insertMany([
{
title: 'Titanic',
year: 1997,
genres: [ 'Drama', 'Romance' ],
rated: 'PG-13',
languages: [ 'English', 'French', 'German', 'Swedish', 'Italian', 'Russian', 'Spanish' ],
released: ISODate("1997-12-19T00:00:00.000Z"),
awards: {
wins: 127,
nominations: 63,
text: 'Won 11 Oscars. Another 116 wins & 63 nominations.'
},
cast: [ 'Leonardo DiCaprio', 'Kate Winslet', 'Billy Zane', 'Kathy Bates' ],
directors: [ 'James Cameron' ]
},
{
title: 'Casablanca',
genres: [ 'Drama', 'Romance', 'War' ],
rated: 'PG',
cast: [ 'Humphrey Bogart', 'Ingrid Bergman', 'Paul Henreid', 'Claude Rains' ],
languages: [ 'English', 'French', 'German', 'Italian' ],
released: ISODate("1943-01-23T00:00:00.000Z"),
directors: [ 'Michael Curtiz' ],
awards: {
wins: 9,
nominations: 6,
text: 'Won 3 Oscars. Another 6 wins & 6 nominations.'
},
lastupdated: '2015-09-04 00:22:54.600000000',
year: 1942
}
])Para obtener los datos de esta colección, podemos usar la función find sobre la colección. Esta función nos permite especificar un filtro que aplicar, en una primera instancia, podemos dejarlo vacío para recoger todos los datos de la colección:
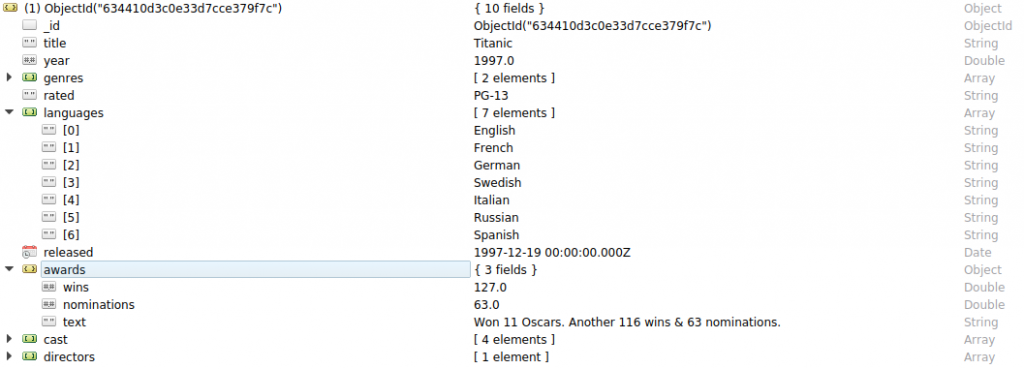
db.movies.find({})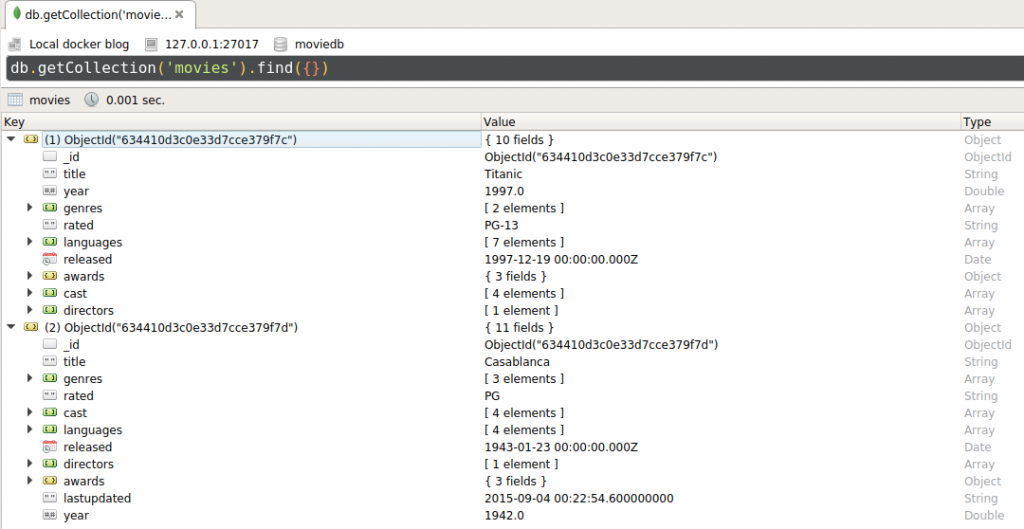
Al ver el resultado de esta operación, podemos observar que ha aparecido un nuevo campo _id. Este campo es generado automáticamente por MongoDB y contiene la siguiente información:
- Un timestamp de 4 bytes, representando el momento de la creación del objeto.
- Un valor aleatorio de 5 bytes generado según la máquina y el proceso.
- Un contador incremental de 3 bytes, que es inicializado a un valor aleatorio.
MongoDB garantiza que este campo sea único, será usado por defecto como clave primaria y estará indexado. En caso de requerirse, podemos establecer un valor customizado para este campo pero debemos asegurarnos de que este valor sea único para todos los documentos de la colección.
Podemos aplicar filtros tan complejos como deseemos, vamos a buscar todas las películas que están disponibles en inglés y hayan obtenido más de 100 premios:
db.movies.find({
$and: [
{ "languages": "English" },
{ "awards.wins": { $gt: 100 } }
]
})
Además, podemos indicar si deseamos ver todos los campos en los resultados o no, supongamos que solo queremos averiguar el título de las películas en el caso anterior:
db.movies.find({
$and: [
{ "languages": "English" },
{ "awards.wins": { $gt: 100 } }
]
}, { _id: 0, title: 1 } )Con el siguiente resultado:

Conclusión
Hemos visto la superficie de las funcionalidades de MongoDB, sin embargo, quedan muchos puntos por discutir: la creación de índices, la interacción con distintos lenguajes de programación… Además de las posibilidades a la hora de hacer peticiones a las colecciones que abren los pipelines de agregación, las cuales podrás seguir investigando en un post anterior sobre Pipelines de agregación en MongoDB.
En futuros artículos, trataremos la interacción con MongoDB con lenguajes como Scala o Python, además de discutir alternativas a esta tecnología.
Si te ha parecido útil este post, te recomendamos visitar la categoría Software y a compartirlo con tus contactos para que ellos también puedan leerlo y opinar. ¡Nos vemos en redes!
