
When analysing a system’s behavior, it is not uncommon to encounter some kind of problem or difficulty. For example, we might want to improve a process—whether by better distributing workloads, avoiding long wait times, or increasing its performance. However, it is extremely difficult to know whether the change we are implementing will bring us closer to or further away from the goals we hope to achieve.
When analysing a system’s behavior, it is not uncommon to encounter some kind of problem or difficulty. For example, we might want to improve a process—whether by better distributing workloads, avoiding long wait times, or increasing its performance. However, it is extremely difficult to know whether the change we are implementing will bring us closer to or further away from the goals we hope to achieve.
Let’s imagine that our mission is to increase the profits generated by a leisure center thanks to the visitors who come there. Among other things, we could consider lowering the price, but also raising it. Which of these two options would increase total revenue?
Perhaps, by lowering prices, visitor traffic would increase so much that profits would rise. However, if we raised the price, traffic might not drop too much, which would also lead to increased revenue. On the other hand, perhaps lowering prices would cause maintenance costs to rise so much that we would lose money. Or it could be that a price increase would result in a significant loss of traffic, negatively affecting revenue.
So, we have a dilemma. How can we decide what the solution would be to achieve our goal? Another option would be to run A/B tests on parts of our system. That way, we could gather information on the effect of the changes we implement. However, this task is sometimes not entirely practical or may even become impossible. In these cases, it’s common to run simulations.
What are simulations?
A simulation is a representation of a real-world system. However, it is important to keep in mind that every simulation is imperfect. This is because reality cannot be fully captured in a simplified model. Therefore, we must decide which aspects of reality to simulate, which to simplify, and what assumptions to make.
With this in mind, we will now introduce one of the simplest tools used to perform simulations: the Markov chain.
What is a Markov chain?
A Markov chain is a process that allows us to model the probability of transitioning between different states. For example, if a customer is in a specific section of the supermarket, there is a certain probability that they will visit the following sections.
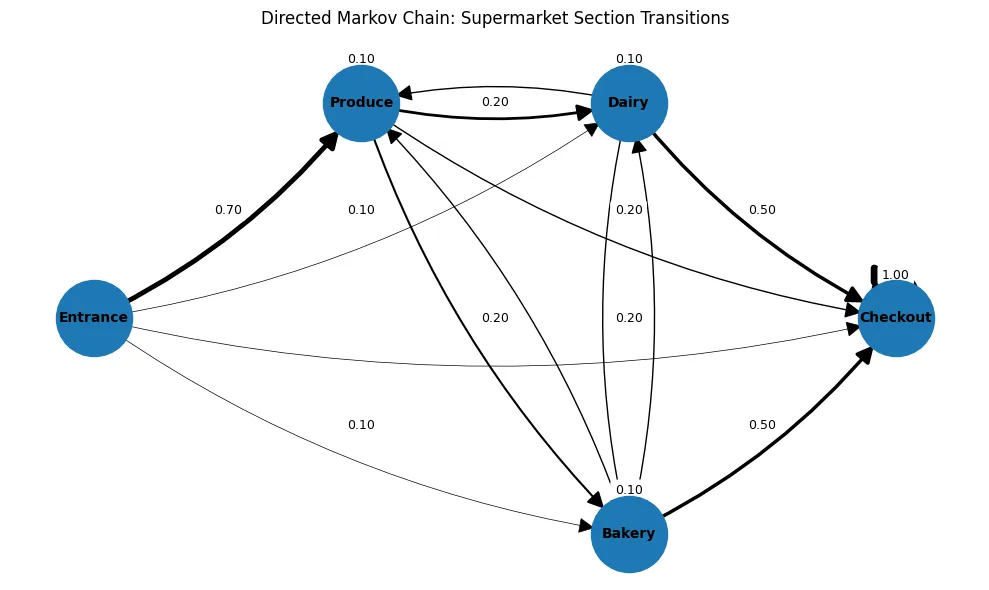
This type of model is based on a key assumption: that time does not affect the transition. In other words, if the customer was previously in the “Dairy” section, it doesn’t matter if they were in “Produce” three transitions earlier. Only the current moment matters.
A model like this is extremely simplified. It’s clear that, in reality, the past does affect current decisions. So, why might such a simplified model be useful?
As we mentioned earlier, every model is presumably flawed. Reality is too complex, and capturing all those complexities is an impossible task. However, to better understand a system, it is not necessary to capture its full diversity. In this sense, Markov chains are an extremely simple tool that helps us understand the system much better relative to their implementation cost.
Markov chain example
To illustrate the use of this model, we will create a hypothetical scenario. We have a website and want to increase the amount of traffic reaching the “Signup” page, as we suspect that other pages are drawing too much traffic.
First, we tracked how different users navigate the website. This way, for each section of the website, we determine where the user went next. For example, they navigated from “Home” to “Features.”
Deriving the Markov chain that represents our data is very simple. We simply sum all identical transitions and then divide by the total number of occurrences of that state.
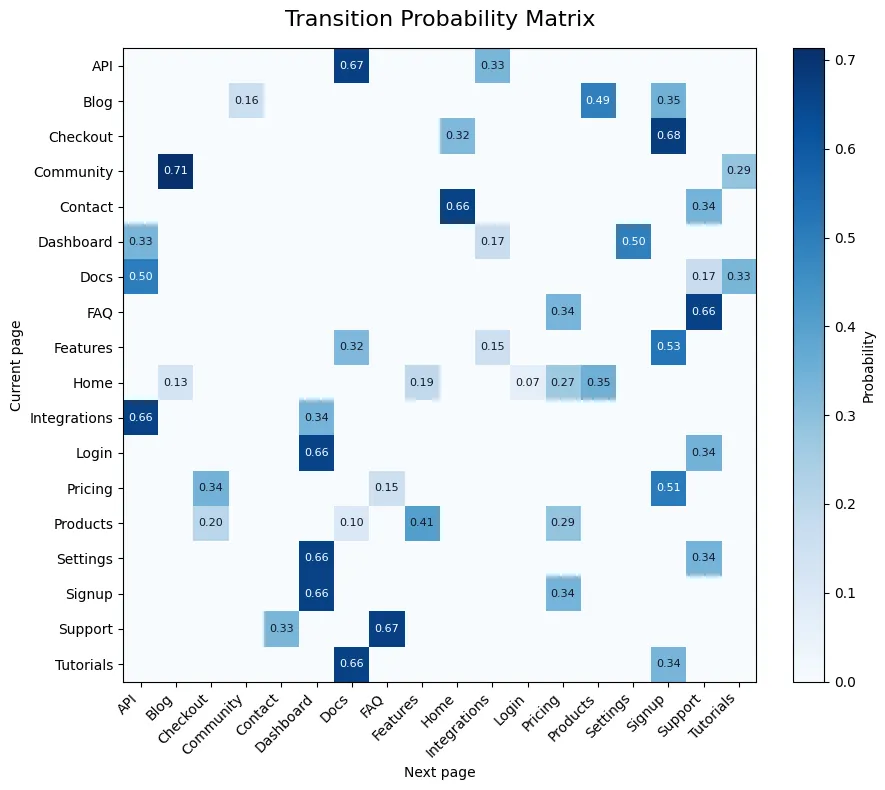
Understanding user behavior
Now we have a simplified representation of user behavior. From this, we can see which pages drive traffic to other pages. For example, we see that the “Tutorials” page leads to “Signup” with a 34% probability, similar to the “Blog” page at 35%.
If we use the model as it is now, we can replicate several of the possible paths a user took to reach “Signup.”
Home -> Features -> Docs -> Tutorials -> Signup
Home -> Pricing -> Signup
Home -> Login -> Dashboard -> Settings -> Support -> Contact -> Home -> Pricing -> Checkout -> Signup
Home -> Pricing -> Signup
Home -> Products -> Pricing -> Signup
Home -> Blog -> Signup
Home -> Products -> Docs -> Support -> FAQ -> Support -> FAQ -> Pricing -> Checkout -> Signup
Home -> Pricing -> Checkout -> Signup
Home -> Blog -> Signup
Home -> Features -> Docs -> API -> Docs -> Support -> FAQ -> Pricing -> Signup
Home -> Products -> Features -> Docs -> Tutorials -> SignupThe problem is that right now we’re just mimicking reality, and this doesn’t give us much information beyond a representation of something that already exists. However, we can simulate different scenarios using the model we’ve created by altering the representation of the system’s state. For example, let’s simulate the most basic scenario: removing certain links to other pages.
Simulating a change in the system
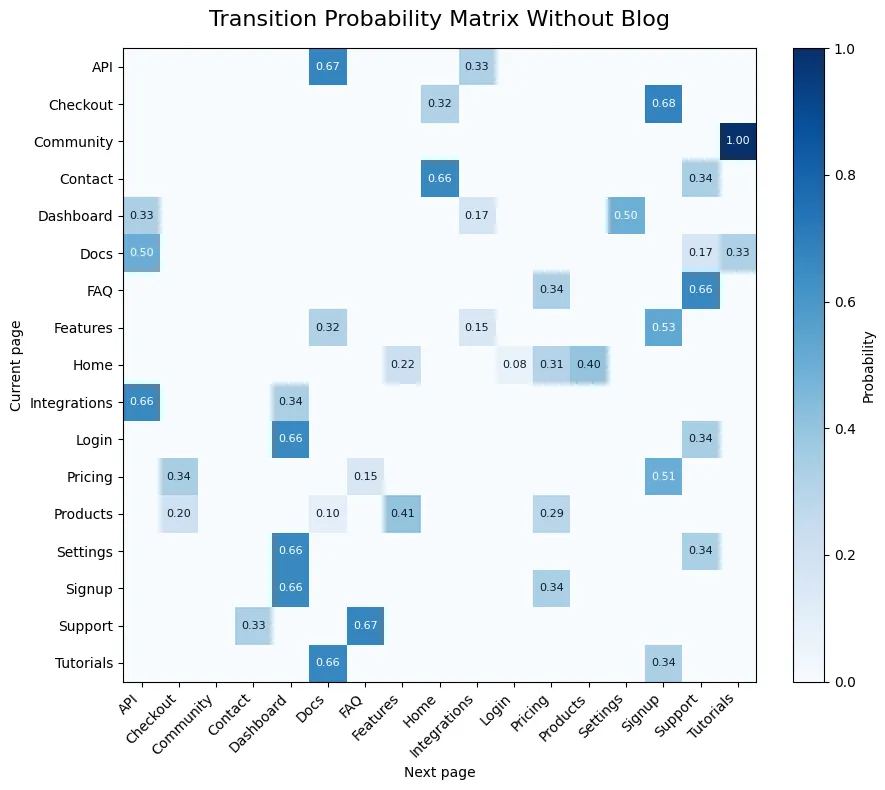
For this example, we decided that the Blog requires too much investment for what is considered a low return in terms of the number of users who visit “Signup.” Therefore, we decided to simulate the effect of removing “Blog” from the model.
To measure the effect, we’ll run a simple simulation. We’ll generate 10,000 simulations of the paths a user might take to reach the “Signup” page and calculate the average distance and its variance. This will give us a rough idea of the impact this change would have.
| Mid-level jumps | Standard deviation | |
| With Blog | 6.65 | 3.98 |
| Without Blog | 6.69 | 4.02 |
Looking at the results, we see that removing “Blog” would not have the desired effect due to the high standard deviation. However, it also does not appear that it would have a negative impact.
In this way, we have a quick (though not very precise) approximation of the effect of changes in a system. Thus, we get an initial idea of how it would behave in the face of a variation without the need for costly testing. Obviously, this process does not replace proper testing, but it can be a first step toward justifying more detailed testing.
Conclusion
In this post, we’ve looked at an introduction to the concept of simulation. We’ve also analysed one of the many models we can use to perform it: the Markov chain.
Furthermore, we’ve seen how this model can be used to simulate a system’s behavior and how it helps us understand whether certain decisions can steer the system toward a desired goal.
If you found this post useful, we encourage you to check out other articles in the Algorithms category on our blog and visit the Damavis website to learn more about the services we offer.
