
In our previous post about Reinforcement Learning, we made an introduction to this area through one of its most popular techniques: Q-learning. We laid the groundwork by talking about Markov decision processes, policies and value functions, and we saw a first approach to this method with its tabular version.
This time, we will extend classical Q-learning with the use of neural networks. Therefore, in case you are not familiar with the concepts mentioned above, we recommend you to take a look at the article Reinforcement Learning: Q-learning. At the same time, it may also be a good idea to refresh Deep Learning concepts with the following articles:
- Convolutional Neural Networks applied to the game Hungry Geese
- Creating a convolutional network with Tensorflow
- Simple Perceptron: Mathematical definition and properties
- Simple Perceptron: Python implementation
A star is born
In 2015, DeepMind introduced DQN (Deep Q Network) and the field that we know today as Deep Reinforcement Learning was born. It was originally applied to Atari video games, where it not only beat the state of the art but also obtained higher results than human experts to everyone’s astonishment.
In this new architecture, the q-table, in which the q-values for each pair (state, action) are stored, is replaced by a neural network that approximates the q-value of performing each available action in a state. In the following figure we can see the schematics of each version:
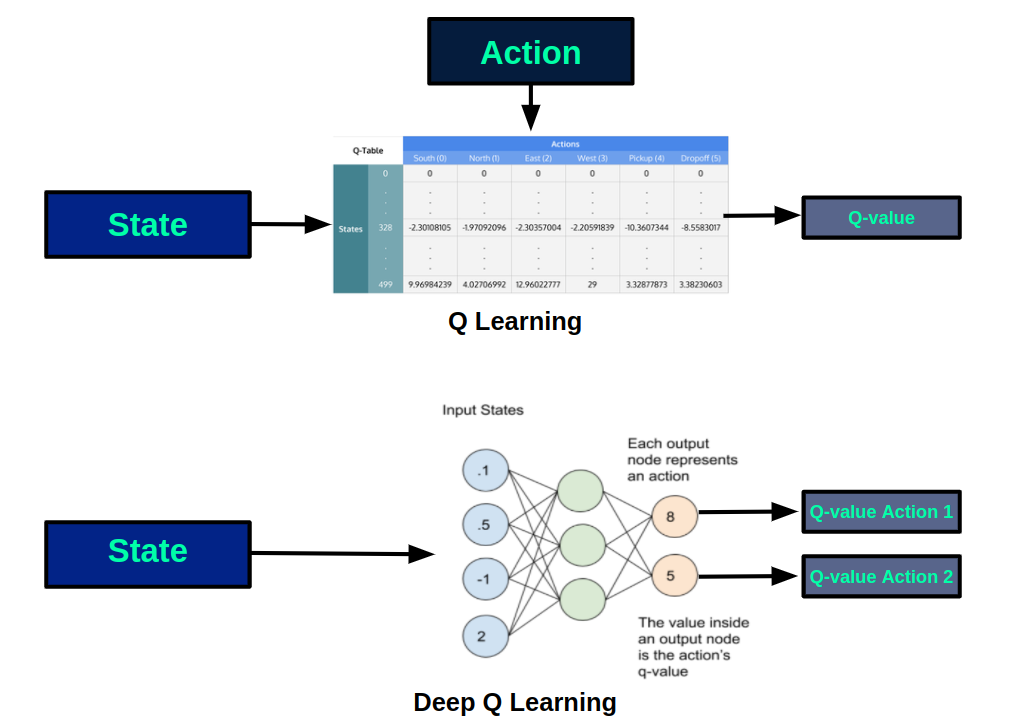
Using a neural network we have multiple benefits compared to the tabular version. On one hand, it is impossible to store in a table the states of very large or continuous environments, while this is no problem for a neural network. In addition, the learning obtained in one state is transferred to similar states, so it is possible to make good estimations for states that have not been visited previously.
Training the model
Before going into the training algorithm, it is worth explaining a very powerful concept used in the training algorithm: Experience replay.
Interacting with the environment to obtain information on the impact of actions has a cost. If we discard information after using it, we are losing the opportunity to use it again in the future. To make even more use of the information obtained, Experience replay proposes to store the information from the experience obtained, so that it can be used again in the future to learn. In this way, the information obtained (state, action, reward, next state) is stored in a memory of a certain size. For example, it could be implemented with a queue in which, when information from a new transition arrives, the oldest one leaves.
During training, we will use some criteria to balance exploration and exploitation and feed our memory with new information. At the same time, we will take mini-batches of transitions from the memory, which we will use to optimize the model parameters, considering the error between the approximation of our model and what the selected experience shows us.
The pseudocode of the learning process is shown below:

Conclusion
In this post we have introduced Deep Reinforcement Learning through the model that originated it: Deep Q Network. It should not only be valued for its performance but also for what it meant, since it put the focus on the use of neural networks in the field of reinforcement learning, giving rise to a host of new approaches and lines of research.
If you liked this post, we encourage you to visit the Algorithms category to see other articles similar to this one and to share it on social networks. See you soon!
