
En el post Procesamiento del Lenguaje Natural con Python se introdujo el concepto de NLP y se mostró un ejemplo de uso del conocido modelo de generación de texto GPT-3. En resumen, el sistema propuesto por OpenAI se trata de un modelo generativo de inteligencia artificial capaz de crear textos que emulan la capacidad de redacción de un humano.
Sin embargo, el campo del procesamiento del lenguaje natural no es exclusivo de los modelos generativos y en ámbitos como la visión por computador también encontramos este tipo de modelos, pero en este caso capaces de generar imágenes en lugar de texto.
En este post introduciremos uno de estos modelos generativos tan conocidos en la visión por computador como son las Redes Generativas Adversarias (GAN).
Antes de pasar a conocer este tipo de redes, si te propongo que identifiques cuáles de las imágenes que ves a continuación son reales y cuáles no, seguramente te veas en dificultades para decidirte. Incluso puede que te lleves una sorpresa si te digo que todas ellas han sido generadas de manera artificial a partir de una GAN.




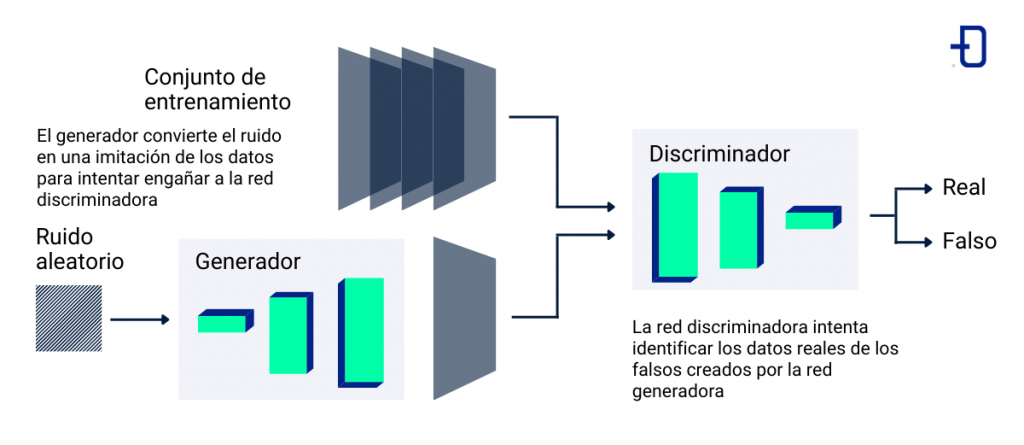
Estructura básica de una GAN
En 2014 un grupo de investigación de la Universidad de Montreal encabezado por el Dr. Ian Goodfellow propone un nuevo marco de trabajo sobre las redes neuronales generativas. En primer lugar, el objetivo principal de las redes generativas se basa en tratar de conseguir que un cierto dato adopte la distribución de otro conjunto de datos. Es decir, se busca que una entrada dada se asemeje tanto a la distribución deseada que el dato generado sea indistinguible de un dato real de dicha distribución. En otras palabras, si hablamos de imágenes, poder generar una imagen que parezca real.
Para conseguir dicho objetivo existen múltiples soluciones. Sin embargo, la solución propuesta con redes generativas adversarias es bastante intuitiva. Principalmente se basa en el uso de 2 redes que compiten entre sí. Por un lado disponemos de una red llamada generador G y otra red distinta llamada discriminador D.
El objetivo del generador es ser capaz de capturar la distribución de los datos y a partir de una serie de valores aleatorios generar una imagen que se asemeje en forma y contenido a las imágenes del conjunto de datos que se esté utilizando. En cambio, la tarea del discriminador será discernir entre si una imagen dada corresponde con una imagen real o si, por el contrario, ha sido generada mediante su red antagónica, el generador.
Si observamos este tipo de redes desde el punto de vista matemático, podemos ver que se trata de un problema asociado a la teoría de juegos. Concretamente se considera un juego de suma cero donde el generador trata de minimizar la misma función de pérdida que el discriminador tratará de maximizar.
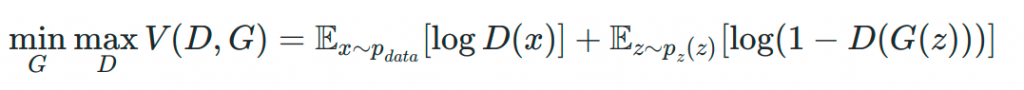
Atendiendo a la función de pérdida propuesta podemos distinguir los siguientes elementos:
- D(x) es la estimación de la probabilidad del discriminador de que una muestra x pertenezca al conjunto de datos real.
- Ex es el valor esperado de pertenencia de que la muestra x presente la misma distribución que los datos reales sobre todas las muestras reales.
- G(z) es el output del generador tomando como entrada una serie de valores aleatorios (ruido) denotado por z.
- D(G(z)) es la estimación del discriminador de que la salida obtenida por el generador es real o falsa.
- Ez es el valor esperado de la salida obtenida por el generador. De hecho, se trata de el valor esperado sobre la distribución de todas las muestras falsas, es decir, creadas por el generador.
Como se puede apreciar la fórmula deriva de la función de pérdida ampliamente utilizada en Machine Learning conocida como Entropía Cruzada.
Entrenamiento y problemas habituales
Tras conocer cómo es la estructura básica de este tipo de redes generativas podemos introducir cúal es la estrategia de entrenamiento habitual. Dado que este tipo de redes se compone realmente de dos redes independientes, el entrenamiento consiste en entrenar cada una de estas redes de manera conjunta.
En primer lugar, el generador producirá una imagen y esta será evaluada por el discriminador en la misma iteración del entrenamiento. Por tanto, el resultado del discriminador influirá en la actualización de pesos del generador y mediante el algoritmo de retropropagación se actualizarán ambas redes. Esto se repetirá en cada iteración del entrenamiento. Según la problemática que se enfrente sobre esta estrategia se aplican variaciones como dejar de entrenar el discriminador llegado a cierto punto o no aplicar la actualización de pesos del discriminador en todas las iteraciones.
A pesar de los buenos resultados que pueden generar las GAN es cierto que presentan algunas desventajas. Podemos enumerar tres de ellas:
- Convergencia inestable. Debido a la competición entre las dos redes el punto de equilibrio es difícil de conseguir. Esto genera que la función de pérdida durante el entrenamiento sea muy irregular y que los resultados puedan variar bastante entre épocas.
- Colapso de modo. Este problema sucede cuando el generador solo es capaz de generar un subconjunto de imágenes que adoptan la distribución de los datos objetivo y para cualquier valor de ruido genera la misma salida. El discriminador es incapaz de diferenciarlo de una imagen real, pero a su vez los resultados son todos extremadamente parecidos.
- Desvanecimiento de gradiente. Por el contrario, cuando el discriminador es capaz de distinguir demasiado bien entre los datos reales y artificiales la actualización de pesos que se produce en el generador es muy pequeña. Esto produce que los pesos de las capas más tempranas no varíen entre épocas y por tanto la red no aprenda.
Aunque la versión original de las GANs presenten estas desventajas existen multitud de variaciones que palian algunos de estos problemas.
Conclusión
En este post hemos visto una breve introducción teórica sobre otro tipo de red generativa. Habitualmente este tipo de redes son ampliamente utilizadas en el ámbito de la visión por computador debido a que encajan muy bien con redes convolucionales.
De hecho, cada vez es más habitual encontrar usos de estas redes en moda, diseño o incluso recreaciones digitales para videojuegos. No obstante, no se debe descuidar la parte ética debido a que estas redes saltaron a la fama tras utilizarse para crear famosos deepfakes.
En definitiva, un tipo de arquitectura neuronal compleja pero con un gran potencial. Si deseas conocer más sobre este tipo de redes y muchas otras no dejes de visitar el blog de Damavis.
