
La detección de objetos es una rama de la visión artificial que se centra en identificar la presencia y localización de objetos en imágenes. Es utilizada en una amplia variedad de aplicaciones, desde sistemas de vigilancia, análisis de imágenes médicas hasta la conducción autónoma.
Esta técnica implica la utilización de algoritmos y metodologías de aprendizaje automático para reconocer patrones en las imágenes con los que poder detectar la presencia de los objetos deseados. En los últimos años, han visto la luz varios enfoques y modelos distintos como Faster R-CNN, YOLO y SSD.
En este post, sobrevolamos rápidamente algunos conceptos fundamentales de este campo y nos centraremos en la arquitectura YOLO para realizar una pequeña experimentación.
¿Cómo funciona la detección de objetos?
Partimos de una red convolucional (CNN), que nos permite dada una imagen obtener una clasificación de la misma.
Seguidamente, mediante un algoritmo, buscamos regiones que pueden ser de interés, por ejemplo zonas contiguas de tonos parecidos y bordes, para introducirlas en nuestra CNN y determinar su clasificación. Finalmente, podemos determinar cuáles de las regiones contiene a nuestro objeto y poder indicar su posición.
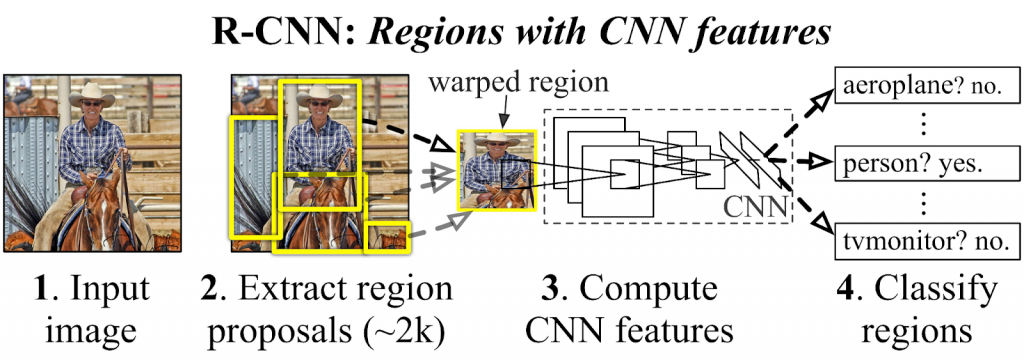
Si bien esta forma de detectar objetos parece sencilla y eficaz, plantea un problema relacionado con las anteriormente mencionadas regiones de interés. ¿Qué ocurre si distintas áreas solapan al mismo objeto?
Para solucionar esto, se utilizan en conjunto las técnicas de IoU y NMS:
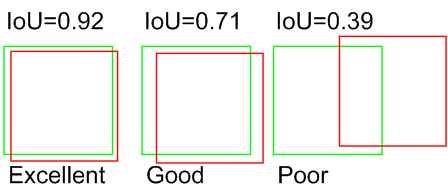
Intersection over Union (IoU) calcula la relación entre el área de intersección de dos regiones y el área de unión de las mismas.
Non-maximum Suppression (NMS) elimina detecciones superpuestas, manteniendo solo la detección con la puntuación más alta.

Detección de objetos con YOLO
En 2016 nace YOLO “You Only Look Once”, un modelo de detección de objetos altamente eficiente y preciso que ha demostrado grandes capacidades para detectar objetos en tiempo real.
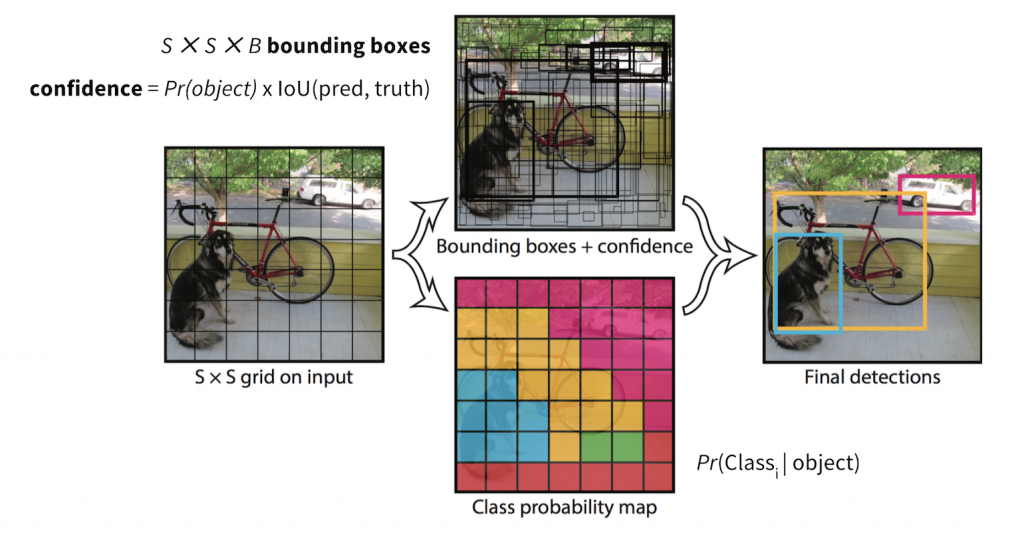
Yolo reutiliza las técnicas mencionadas anteriormente pero además parte de un concepto algo diferente al del resto de modelos, hace sus predicciones basadas en la imagen completa en lugar de trabajar por regiones de interés. Durante su entrenamiento, divide las imágenes en una cuadrícula y se encarga de aprender las probabilidades de encontrar los objetos en las distintas celdas de ésta.
Experimentación con Icevision
Icevision es una biblioteca de visión por computador de código abierto que simplifica el desarrollo de aplicaciones de detección de objetos y segmentación. Esta biblioteca basada en Pytorch y Fastai nos proporciona herramientas de carga y transformación de imágenes para entrenar y evaluar modelos.
Durante nuestro ejemplo utilizaremos YoloV5, la versión más reciente incluida en Icevision.
Empezamos importando la librería:
from icevision.all import *Vamos a descargar el siguiente dataset de prueba:
url = "https://cvbp-secondary.z19.web.core.windows.net/datasets/object_detection/odFridgeObjects.zip"
dest_dir = "fridge"
data_dir = icedata.load_data(url, dest_dir)Seguidamente, leemos nuestros datos y los dividimos en entrenamiento y validación (por defecto 80% – 20%). Para la lectura, Icevision nos brinda distintos parsers, además de la posibilidad de crear parsers a medida. En nuestro caso, nuestro dataset tiene el formato VOC.
parser = parsers.VOCBBoxParser(annotations_dir=data_dir / "odFridgeObjects/annotations", images_dir=data_dir / "odFridgeObjects/images")
train_records, valid_records = parser.parse()Antes de inyectar los datos a nuestro modelo, podemos transformar nuestras imágenes (ya que necesitamos que todas sean del mismo tamaño). Incluso podemos aplicar técnicas de Data Augmentation (no se realizará en este post).
image_size = 384
train_tfms = tfms.A.Adapter([*tfms.A.aug_tfms(size=image_size, presize=512), tfms.A.Normalize()])
valid_tfms = tfms.A.Adapter([*tfms.A.resize_and_pad(image_size), tfms.A.Normalize()])
train_ds = Dataset(train_records, train_tfms)
valid_ds = Dataset(valid_records, valid_tfms)Una vez tenemos nuestro dataset preparado, tan solo nos queda seleccionar el modelo y crear los Data Loaders para el entrenamiento.
extra_args = {'img_size':image_size}
model_type = models.ultralytics.yolov5
backbone = model_type.backbones.smallIndicamos que queremos nuestro modelo pre entrenado, ya que nosotros realizaremos “fine tuning” (ajustaremos el modelo a nuestra tarea con nuestro conjunto de datos más pequeño).
model = model_type.model(backbone=backbone(pretrained=True), num_classes=len(parser.class_map), **extra_args)
train_dl = model_type.train_dl(train_ds, batch_size=8, num_workers=4, shuffle=True)
valid_dl = model_type.valid_dl(valid_ds, batch_size=8, num_workers=4, shuffle=False)Finalmente, procedemos a entrenar nuestro modelo. En este caso, utilizaremos Fastai para la tarea, indicando que queremos que el entrenamiento realice 20 épocas con un learning rate de 0.00158.
learn = model_type.fastai.learner(dls=[train_dl, valid_dl], model=model, metrics=metrics)
learn.fine_tune(20, 0.00158, freeze_epochs=1)Tras el entrenamiento, podemos ver algunas predicciones:
model_type.show_results(model, valid_ds, detection_threshold=.5)
¡Nada mal! En la izquierda tenemos las etiquetas utilizadas para el entrenamiento y a la derecha la predicción real de nuestro modelo.
Conclusión
En conclusión, la detección de objetos mediante el uso de Deep Learning es una técnica muy útil y ampliamente utilizada en distintos campos de la visión artificial. En este post, hemos explicado levemente el funcionamiento general de esta técnica para finalmente centrarnos en la arquitectura YOLO y terminar con un ejemplo práctico de uso con la librería Icevision.
Aunque no se ha mencionado en este post, hay que tener en cuenta que la calidad de estos modelos depende en gran medida de la calidad y la cantidad de los datos utilizados para sus entrenamientos.
Finalmente, cabe destacar que este campo se encuentra en constante evolución y promete seguir siendo un área de investigación interesante para un futuro.
Si te ha parecido interesante este post, te animamos a leer Detección de poses humanas mediante Deep Learning o a visitar la categoría Data Science para ver otros artículos similares a este. ¡No olvides compartirlo en redes sociales y dejarnos un comentario sobre qué te ha parecido!
