
Object detection is a branch of computer vision that focuses on identifying the presence and location of objects in images. It is used in a wide variety of applications, from surveillance systems, medical image analysis to autonomous driving.
This technique involves the use of machine learning algorithms and methodologies to recognize patterns in images in order to detect the presence of desired objects. In recent years, several different approaches and models have come to light, such as Faster R-CNN, YOLO and SSD.
In this post, we will quickly go over some fundamental concepts in this field and focus on the YOLO architecture for a small experimentation.
How does object detection work?
We start from a convolutional network (CNN), which allows us to obtain a classification of an image.
Pre-trained on ImageNet-21k (14 million images, 21,843 classes).
Then, using an algorithm, we search for regions that may be of interest, for example contiguous areas of similar shades and edges, and feed them into our CNN to determine their classification. Finally, we can determine which of the regions contains our object and indicate its position.
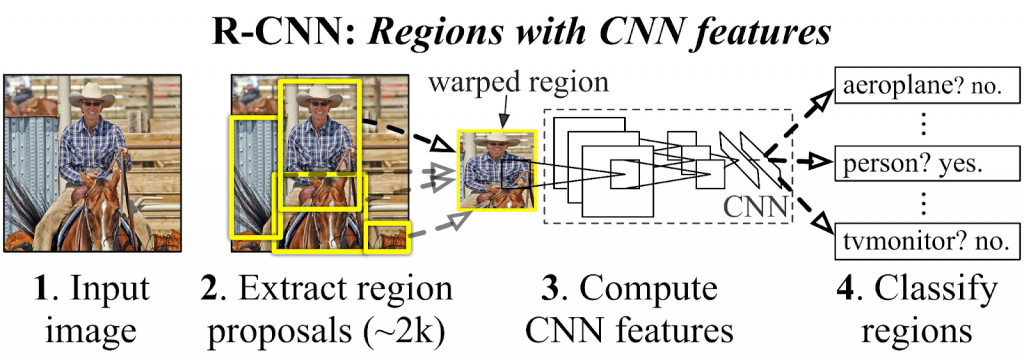
Although this way of detecting objects seems simple and efficient, there is a problem related to the aforementioned regions of interest: what happens if different areas overlap the same object?
To solve this, IoU and NMS techniques are used together:
Intersection over Union (IoU) calculates the ratio between the area of intersection of two regions and the area where they meet.
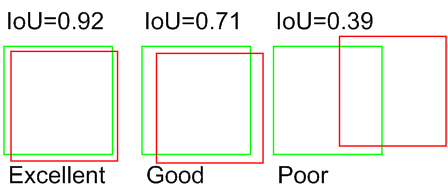
Non-maximum Suppression (NMS) eliminates overlapping detections, keeping only the detection with the highest score.

Object detection with YOLO
In 2016 YOLO “You Only Look Once” was born, a highly efficient and accurate object detection model that has demonstrated great capabilities to detect objects in real time.
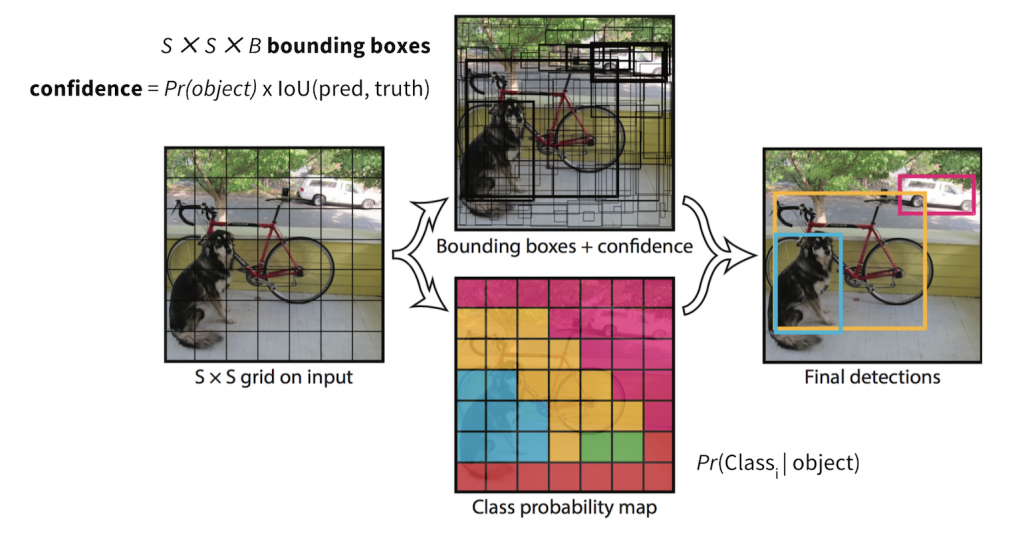
Yolo reuses the aforementioned techniques but also starts from a somewhat different concept than the rest of the models, it makes its predictions based on the whole image instead of working by regions of interest. During its training, it divides the images into a grid and learns the probabilities of finding the objects in the different cells of the grid.
Experimentation with Icevision
Icevision is an open source computer vision library that simplifies the development of object detection and segmentation applications. This Pytorch and Fastai-based library provides image loading and transformation tools for training and evaluating models.
During our example we will use YoloV5, the latest version included in Icevision.
We start by importing the library:
from icevision.all import *We will download the following test dataset:
url = "https://cvbp-secondary.z19.web.core.windows.net/datasets/object_detection/odFridgeObjects.zip"
dest_dir = "fridge"
data_dir = icedata.load_data(url, dest_dir)We then read our data and divide it into training and validation (default 80% – 20%). For reading, Icevision provides us with different parsers, as well as the possibility to create custom parsers. In our case, our dataset has the VOC format.
parser = parsers.VOCBBoxParser(annotations_dir=data_dir / "odFridgeObjects/annotations", images_dir=data_dir / "odFridgeObjects/images")
train_records, valid_records = parser.parse()Before injecting the data into our model, we can transform our images (as we need them all to be the same size). We can even apply Data Augmentation techniques (not to be done in this post).
image_size = 384
train_tfms = tfms.A.Adapter([*tfms.A.aug_tfms(size=image_size, presize=512), tfms.A.Normalize()])
valid_tfms = tfms.A.Adapter([*tfms.A.resize_and_pad(image_size), tfms.A.Normalize()])
train_ds = Dataset(train_records, train_tfms)
valid_ds = Dataset(valid_records, valid_tfms)Once we have our dataset ready, we only need to select the model and create the Data Loaders for the training.
extra_args = {'img_size':image_size}
model_type = models.ultralytics.yolov5
backbone = model_type.backbones.smallWe indicate that we want our model pre-trained, as we will be “fine tuning” (adjusting the model to our task with our smaller data set).
model = model_type.model(backbone=backbone(pretrained=True), num_classes=len(parser.class_map), **extra_args)
train_dl = model_type.train_dl(train_ds, batch_size=8, num_workers=4, shuffle=True)
valid_dl = model_type.valid_dl(valid_ds, batch_size=8, num_workers=4, shuffle=False)Finally, we proceed to train our model. In this case, we will use Fastai for the task, indicating that we want the training to perform 20 epochs with a learning rate of 0.00158.
learn = model_type.fastai.learner(dls=[train_dl, valid_dl], model=model, metrics=metrics)
learn.fine_tune(20, 0.00158, freeze_epochs=1)After the training, we can see some predictions:
model_type.show_results(model, valid_ds, detection_threshold=.5)
Not bad! On the left we have the labels used for training and on the right the actual prediction of our model.
Conclusion
In conclusion, object detection using Deep Learning is a very useful and widely used technique in different fields of computer vision. In this post, we have slightly explained the general operation of this technique to finally focus on the YOLO architecture and finish with a practical example of use with the Icevision library.
Although not mentioned in this post, it should be noted that the quality of these models depends to a large extent on the quality and quantity of the data used for their training.
Finally, it should be noted that this field is constantly evolving and promises to continue to be an interesting area of research in the future.
If you found this post interesting, we encourage you to read Detection of human poses through Deep Learning or visit the Data Science category to see other articles similar to this one. Don’t forget to share it on social networks and leave us a comment about what you thought!
