
La detección de pose humana es una tarea bastante relevante en el campo de la visión por computador, que consiste en identificar la postura de una figura humana a partir de una imagen. Dicha pose se define a partir de una serie de puntos clave, que habitualmente serán articulaciones, de forma que el objetivo será encontrar la posición (x, y) de cada uno de esos puntos, o (x, y, z) en el caso de que queramos identificar también la profundidad. Según la opción elegida, hablaremos de detección de pose 2D ó 3D.
En este artículo, buscaremos dar una visión general de la temática así como desarrollar con mayor profundidad el funcionamiento de una arquitectura bastante completa, BlazePose. También se realizarán algunos casos de uso, donde podremos ver la potencia que tienen este tipo de modelos.
Ideas generales
En [1] se propone una taxonomía que refleja bastante bien las aproximaciones más comunes al problema. De un lado, podemos diferenciar entre estimar la pose de una única persona cuya posición es conocida y estimar la pose en una imagen con múltiples personas con posiciones desconocidas. En el primer caso, sabemos que tenemos que identificar los n puntos clave que representan la pose, mientras que en el segundo, no conocemos ni las posiciones de las personas, ni la cantidad que hay, y, por tanto, tampoco el número de puntos clave en la imagen.
En el contexto de la estimación de múltiples personas, podemos encontrar dos líneas principales:
- Top-down Approach: Primero detectamos las personas que aparecen en la imagen, obteniendo la caja de cada una (segmento de la imagen que contiene a la persona), y después aplicamos alguna técnica para obtener los puntos clave para cada persona identificada.
- Bottom-up Approach: En primer lugar, localizamos todos los puntos clave de la imagen y luego los agrupamos para formar personas.

Para obtener la posición de los puntos clave, existen dos enfoques principales: los mapas de calor y la regresión directa. Los mapas de calor suelen ser generados con una distribución gaussiana bidimensional centrada en el punto clave, mientras que en la regresión directa se busca obtener directamente la posición del punto en cada una de las dimensiones [2].

BlazePose
En este post, trabajaremos con BlazePose [3], una arquitectura para la detección de pose de una única persona en 3D basada en redes neuronales convolucionales, a través de la implementación disponible en el framework MediaPipe. Se trata de un modelo que emplea tanto mapas de calor como regresión directa y, además de tener una gran precisión, es capaz de realizar inferencia en tiempo real en un dispositivo móvil, siendo esto muy significativo si tenemos en cuenta que este tipo de modelos suelen ser pesados y bastante lentos.
Detección de persona
El primer paso es identificar la región de la imagen en la que se encuentra la persona, para lo que se emplea un detector de posición basado en la cara. Los autores parten de la premisa de que esta parte del cuerpo es una forma fácil y poco costosa de identificar a una persona. Dicho detector, además de identificar la cara, nos da información como el punto central de la cadera, la circunferencia circunscrita a la persona y el ángulo que tiene el tronco del cuerpo en la misma.
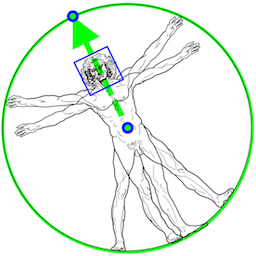
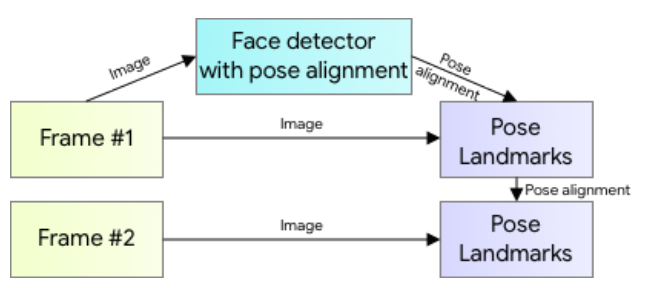
Si estamos trabajando sobre un vídeo, no será necesario realizar esta detección en cada frame, si no que podremos usarla en el primero y a partir de ahí emplear la pose detectada en el frame anterior. De esta forma, el pipeline de inferencia sigue el esquema mostrado en la figura 4. No obstante, si en algún momento se pierde la posición, se volverá a ejecutar el detector sobre el siguiente frame.
Puntos clave
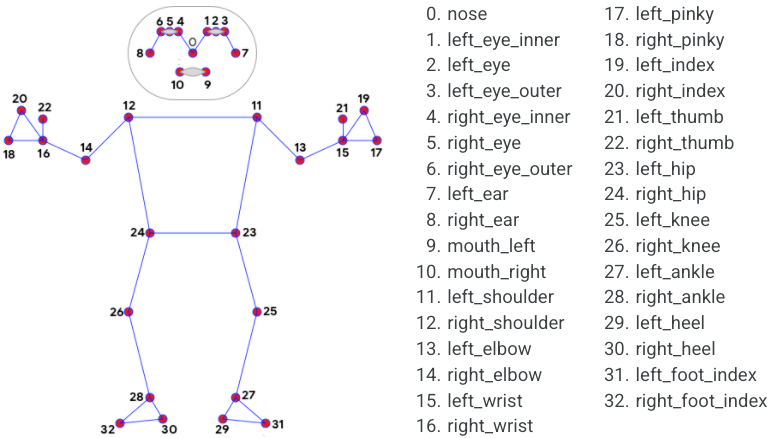
Existen múltiples representaciones de la pose humana usando diferentes combinaciones de puntos clave, pero, en concreto, BlazePose emplea una selección de 33 puntos. En la figura 5 podemos ver dichos puntos y su respectiva equivalencia.
Arquitectura de la red neuronal
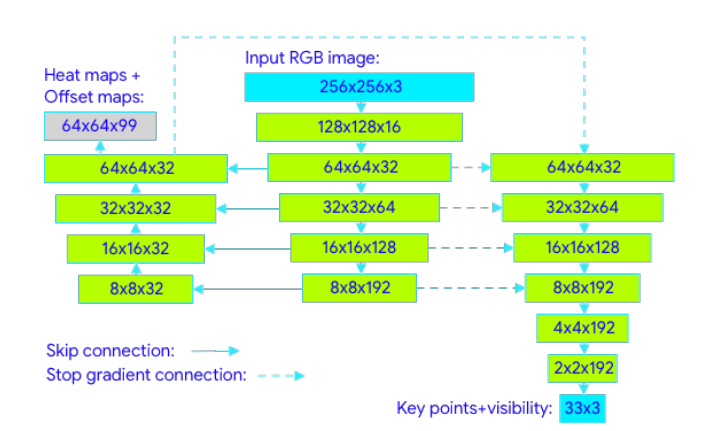
La red recibe como entrada una imagen RGB del segmento que contiene a la persona, redimensionada a 256×256 y girada de forma que el ángulo sea de 90º grados al eje x. La información pasa por una serie de capas convolucionales en las que se van extrayendo características a más alto nivel. Nótese que las conexiones entre columnas representan Skip Connections (atajos), que permiten alcanzar un balance entre características de diferentes niveles.
Por un lado, las columnas central e izquierda forman una arquitectura encoder-decoder en forma de U para generar los mapas de calor y offset, muy empleada para tareas de segmentación en imágenes. En la U, la columna central se construye con capas convolucionales, mientras que en la izquierda se recuperan las dimensiones originales usando convoluciones transpuestas [4]. El mapa de calor y el offset solo se emplean para el entrenamiento, sirviendo para entrenar el embedding que luego se usará para la regresión.
Por el contrario, el regresor sigue una arquitectura encoder, donde tras capas convolucionales con Skip Connections y un par de capas convencionales para realizar la regresión, se obtienen los 33 puntos (x, y, z). Como se puede ver en la figura, la columna de la derecha recibe conexiones con gradiente apagado, es decir, recibe la información pero no se retropropaga el error.
Experimentación
En primer lugar, vamos a importar las librerías necesarias: OpenCV (cv2) para trabajar con imágenes, mediapipe para el modelo y matplotlib para mostrar gráficamente los resultados.
import cv2
import mediapipe as mp
import matplotlib.pyplot as pltInicializamos el modelo y algunas herramientas para el posterior dibujado de los resultados. En el parámetro static_image_mode estamos estableciendo que todas las inferencias se van a realizar de forma estática, por lo que no se aplica la dinámica específica para vídeo en la que se aprovechan los resultados del frame anterior para no tener que volver a detectar la posición de la persona.
Por otra parte, en min_detection_confidence se establece el grado mínimo de confianza [0,1] para considerar válida una detección. Finalmente, model_complexity determina la versión del modelo a construir. En concreto, existen 3 versiones, 0, 1 y 2, de más pequeñas a más grandes. Las versiones más pesadas tendrán mayor precisión pero también más latencia, por lo que no siempre serán la mejor opción.
pose = mp.solutions.pose.Pose(static_image_mode=True,
min_detection_confidence=0.3,
model_complexity=2)
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_stylesAhora se define la función que usaremos para mostrar los resultados de la detección.
def drawPose(img, results,title="Detected Pose"):
img_copy = img.copy()
if results.pose_landmarks:
style=mp_drawing_styles.get_default_pose_landmarks_style()
mp_drawing.draw_landmarks(
image=img_copy,
landmark_list=results.pose_landmarks,
landmark_drawing_spec=style,
connections=mp.solutions.pose.POSE_CONNECTIONS)
fig = plt.figure(figsize = [10, 10])
plt.title(title)
plt.axis('off')
plt.imshow(img_copy[:,:,::-1])
plt.show()Para aplicar la detección de pose solo tendremos que cargar la imagen y pasarsela al método process del modelo. Esto devolverá la información de los puntos detectados siguiendo la codificación desarrollada anteriormente. Si empleamos la función drawPose definida anteriormente, obtenemos los puntos superpuestos a la imagen original.
img1 = cv2.imread('forrest.png')
results1 = pose.process(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB))
drawPose(img1,results1,"Forrest Gump Pose")
Observamos excelentes resultados, probemos ahora con otra imagen.
mg2 = cv2.imread('jedi.jpg')
results2 = pose.process(cv2.cvtColor(img2, cv2.COLOR_BGR2RGB))
drawPose(img2, results2,"Jedi Pose")
Aunque hay algunos fallos leves en los puntos de las manos, en general volvemos a obtener buenos resultados. Mostremos ahora la pose detectada en 3 dimensiones. Hay que tener en cuenta que al estar el eje girado para poder ver mejor la profundidad, es posible que la pose se vea distinta, pero es debido al ángulo.
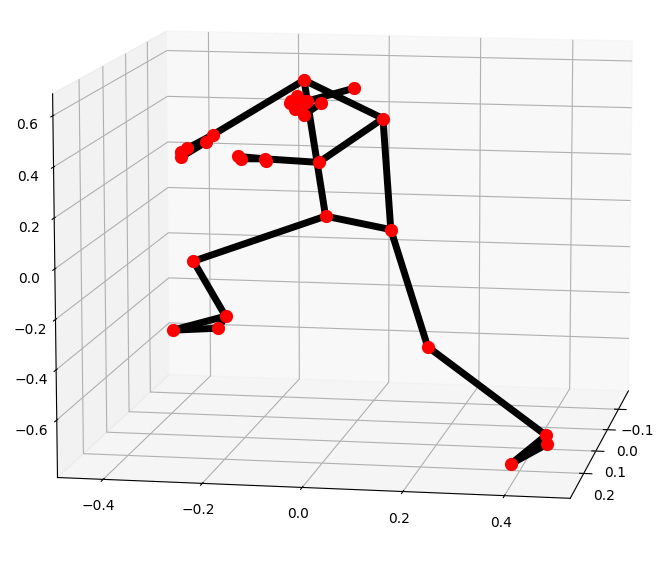
Este gráfico permite ver con claridad que se está realizando correctamente la inferencia de la profundidad, por ejemplo en la posición de las piernas.
Conclusión
En este post se ha introducido el campo de la detección de pose y hemos visto cómo podemos resolver problemas de este tipo fácilmente a través de la implementación disponible en mediapipe.
En futuros artículos, veremos cómo podemos clasificar una pose una vez que ha sido detectada, es decir, dado un conjunto de puntos clave que conforman una pose, asignar una clase a dicha pose, como podrían ser posturas de yoga o el hecho de estar sentado o de pie.
Si te has quedado con ganas de más redes neuronales, puedes seguir con alguno de los posts disponibles en nuestro Blog:
- Perceptrón Simple: Definición Matemática y Propiedades
- El Perceptrón Simple: Implementación en Python
- Creación de una red convolucional con Tensorflow
- Redes neuronales convolucionales aplicadas al juego Hungry Geese
Bibliografía
[1] Ce Zheng, Wenhan Wu, Taojiannan Yang, Sijie Zhu, Chen Chen, Ruixu Liu, Ju Shen, Nasser Kehtarnavaz and Mubarak Shah. «Deep Learning-Based Human Pose Estimation: A Survey». 2020.
[2] Yanjie Li, Sen Yang, Shoukui Zhang, Zhicheng Wang, Wankou Yang, Shu-Tao Xia, and Erjin Zhou. «Is 2D Heatmap Representation Even Necessary for Human Pose Estimation?» 2021.
[3] Valentin Bazarevsky, Ivan Grishchenko, Karthik Raveendran, Tyler Zhu, Fan Zhang and Matthias Grundmann. «BlazePose: On-device Real-time Body Pose tracking». 2020.
[4] Alejandro Newell, Kaiyu Yang, and Jia Deng. «Stacked Hourglass Networks for Human Pose Estimation». 2016.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Science para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
