
Hoy en día, cuando se habla de modelos de redes neuronales, es común que se mencione cuántas tarjetas gráficas necesitan. En el caso de los más grandes, se habla de cuántas tarjetas se necesitan, y cuántos GB de RAM pueden requerir de una gráfica, en los más pequeños. Pero raramente se cuestiona por qué exactamente la tarjeta gráfica es la herramienta preferida. Después de todo, no hace mucho, estaba limitada a cálculos relacionados a gráficos, no al aprendizaje máquina.
Por eso, en este post, enseñaremos un resumen de la arquitectura de la tarjeta gráfica y un ejemplo de una operación acelerada por esta para demostrar su uso. Debido a que en este artículo se programa un ejemplo usando CUDA, todo lo mencionado es específicamente sobre tarjetas gráficas NVIDIA, aun si los conceptos son aplicables a otras tarjetas.
Resumen de la arquitectura
Para entender la arquitectura, es importante entender, en primer lugar, su mayor diferencia con una CPU clásica. Una CPU clásica ejecuta en una arquitectura SISD (Single Instruction Single Data), es decir, una stream singular de instrucciones se ejecuta sobre una stream singular de datos. Esto significa que existe un program counter por procesador y este solo puede cargar un dato a la vez.
En las tarjetas gráficas, en cambio, nos encontramos con SIMT (Single Instruction Multiple Threads), es decir, múltiples procesadores se alimentan de un solo program counter. Esto en la práctica significa que un grupo de procesadores ejecutan el mismo flujo de instrucciones sobre una data stream cada uno.
Esta diferencia quiere decir que, por arquitectura propia, la gráfica es masivamente paralela y este paralelismo es la base de la eficiencia de la gráfica. Esto lo podemos observar en el número de «procesadores» que una tarjeta gráfica tiene comparado con el de una CPU. Por ejemplo, la NVIDIA A100, una gráfica muy popular para aprendizaje máquina, tiene 6912 procesadores.
Pero es un paralelismo limitado, no toda tarea que se pueda dividir en subtareas puede hacer uso de esta arquitectura ya que, debido al modelo SIMT, un simple if puede ralentizar el proceso de forma considerable.
Organización de los recursos
Los recursos mencionados anteriormente no pueden ser accesibles directamente, hace falta una API que los exponga. En este caso, hablaremos de CUDA y de cómo expone los recursos de computación al programador.
Los threads son la unidad más esencial. Cada thread es un set de instrucciones a ejecutar y se ejecuta en un y solo un procesador (CUDA core). Por encima de los threads están los bloques de threads, que conceptualmente son una agrupación de threads que no deben exceder de una cantidad límite (dependiendo de la tarjeta, la cifra suele ser de 1024). Además, tienen una pequeña cantidad de memoria compartida entre todo thread perteneciente al bloque y es posible sincronizar los que se encuentren en el mismo bloque.
Finalmente, están las grids del kernel, que organizan los bloques pero no comparten nada entre ellas excepto la memoria principal, y ni siquiera se pueden sincronizar entre sí. De esta manera, es posible invocar el número de threads necesarios usando una grid de bloques de threads.
La falta de recursos de sincronización fuera del nivel de bloque significa que el paralelismo tiene que exhibir una propiedad para poder hacer uso de la gráfica, ha de ser task parallel. Idealmente, querríamos que sea un set de instrucciones que se ha de ejecutar en todo dato y siempre es el mismo set de instrucciones. Esto limita la cantidad de operaciones disponibles, pero hay una operación que es la base de las redes neuronales modernas que se beneficia mucho de este tipo de paralelismo: la multiplicación de matrices.
Pequeño ejemplo
Para mostrar el efecto de ejecutar una operación en gráfica, lo compararemos con la misma operación en CPU usando la implementación de sklearn. Todo el código está disponible en el GitHub de Damavis.
El ejemplo consistirá en computar toda similitud de coseno entre un vector de 300 elementos y 2.2 millones de vectores de 300 elementos, en específico, todo el modelo de embedding de palabras GloVe.
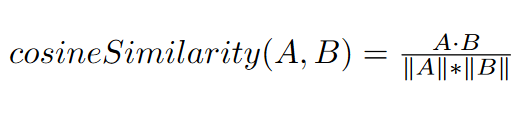
Primero es necesario definir el kernel, la función que se ejecutará en la tarjeta gráfica, lo cual se hace en CUDA, que como lenguaje es muy similar a C.
__global__ void cosineSimilarity (const unsigned int limit, const float* A, float* distanceOut,float* C_model, const float normA) {La definición del kernel requiere de limit, que indica cuántas operaciones calculamos, ya que debido a cómo funciona el especificar threads es muy común que se tengan más threads que datos. En este caso, lo normal es ignorar estos threads extras.
El kernel también requiere del vector A, contra el que computamos la similaridad del coseno; distanceOut, donde enviamos el resultado de la operación; C_model, donde guardamos todos los vectores; y normA, que es la norma L2 de A.
__shared__ float fastA[300];Esta es la memoria compartida entre bloques de threads que mencionamos previamente. Esta memoria es de acceso rápido, ya que es el equivalente a la caché de nivel L1, la caché más pequeña y más rápida en la CPU, excepto que está manejada explícitamente por el usuario.
const unsigned int id = blockIdx.x * blockDim.x + threadIdx.x;
if (threadIdx.x < 300) {
fastA[threadIdx.x] = A[threadIdx.x]; // only one embeding is on A
}Cargamos el vector A en memoria compartida, ya que A será leído entero por múltiples threads, siendo un buen candidato para esta. Ya que no podemos asegurarnos que los threads que han cargado el vector a memoria estén sincronizados, forzamos una sincronización con __syncthreads(), si no, podría ser que se intenten leer datos y estos todavía no estén cargados.
if (id < limit) {
float acum = 0;
float c_norm = 0;
const unsigned int row = id / 8; // Get row
const unsigned int interiorId = threadIdx.x % 8; // Get id within row
for (unsigned int i = interiorId; i < 300; i += 8) {
float cvalAux = C_model[row*300+i];
acum += fastA[i]*cvalAux; // Accumulate within the accumulator
c_norm += cvalAux*cvalAux;
}
acum += __shfl_down_sync(0xffffffff, acum, 4); // Reduction
acum += __shfl_down_sync(0xffffffff, acum, 2); // Reduction
acum += __shfl_down_sync(0xffffffff, acum, 1); // Reduction
c_norm += __shfl_down_sync(0xffffffff, c_norm, 4);
c_norm += __shfl_down_sync(0xffffffff, c_norm, 2);
c_norm += __shfl_down_sync(0xffffffff, c_norm, 1);Computamos el producto interior y la norma L2, solo usando los threads que están por debajo del límite. Para hacer mejor uso del ancho de banda de la memoria de la tarjeta gráfica, hacemos que múltiples threads trabajen en un solo producto interior, en específico, ocho. Generalmente, debido a la arquitectura de la memoria, esto dará mejores resultados, por lo tanto es, en general, mejor leer con stride y no secuencialmente si es posible para así hacer mejor uso de los recursos disponibles.
Finalmente, acumula los valores de los ocho threads en uno solo, usando la función __shfl_down_sync(). Esto permite compartir datos entre threads que pertenecen a un mismo SM (Streaming Multiprocessor). No profundizaremos sobre qué es un SM, pero, en resumen, los bloques de threads son ejecutados por SMs, y un SM suele consistir de 32 threads. Pero no explicaremos más en este post, ya que requiere conocimientos más avanzados de la arquitectura y no es necesario, pues se podría hacer esta misma operación de reducción en la memoria compartida.
if (interiorId == 0) { // Final step and write results
float simVal=(acum / (normA * sqrtf(c_norm)));
distanceOut[row] = simVal;
}
}
}Debido a que sólo computamos una similitud de coseno por 8 threads, solo escribimos el resultado si es el thread relegado a ello. En este caso, si es múltiplo de 8, es el thread relegado.
Una vez tenemos el kernel definido, queda ejecutar este desde Python para hacer nuestra prueba contra sklearn. Usamos pyCUDA para ello.
c_model_gpu = cuda.mem_alloc(embeddings.nbytes)
grid_dot = ((rows // 64) + 1, 1)
block_dot = (512, 1, 1)
cosine_similarity.prepare(("I", "P", "P", "P","F"))
a_gpu = cuda.mem_alloc(300*4)
distances_gpu = cuda.mem_alloc(rows*4)
norm=numpy.linalg.norm(word)
cuda.memcpy_htod(a_gpu, word)
cosine_similarity.prepared_call(grid_dot, block_dot, rows * 8, a_gpu, distances_gpu, c_model_gpu,norm)
cuda.memcpy_dtoh(final_result,distances_gpu)Ejecutando el kernel contra la implementación de sklearn de cosine similarity – sklearn.metrics.pairwise.cosine_similarity – unas 100 veces, obtenemos un speedup casi 70 veces mayor, usando la tarjeta gráfica «NVIDIA GeForce GTX 1650 Mobile» con 1024 procesadores contra la CPU «Intel(R) Core(TM) i7-9750H». Ambos son piezas de hardware relativamente débiles en el mundo del Deep Learning, pero especialmente la gráfica es la pieza más débil.
| CPU | GPU | |
| Tiempo medio | 2.131s | 0.0278s |
| Desviación estándar | 0.303s | 0.000269s |
| Speedup sobre CPU | 1 | 76.74 |
Conclusión
En resumen, la tarjeta gráfica es usada debido a que en las cargas específicas de trabajo requeridas para Deep Learning, su modelo de ejecución es extremadamente apropiado, más que el de la propia CPU, y esto se debe a que las tarjetas gráficas llevan intentando lidiar con el problema de cómo hacer una multiplicación entre matrices más eficiente desde su incepción. Esto permite que las gráficas obtengan speedups masivos cuando se comparan con las CPUs.
Hasta aquí nuestro post de hoy. Si te ha parecido interesante, te invitamos a visitar la categoría Algoritmos para ver otros artículos similares y a compartirlo en redes con tus contactos. ¡Hasta pronto!
