
Decía Noam Chomsky que “El lenguaje de hoy no es peor que el de ayer. Es más práctico. Como el mundo en que vivimos”. Y, precisamente, de ese concepto trata lo que abordaremos en este post: cómo la tecnología ha impulsado la evolución del lenguaje para facilitar y automatizar el proceso de comunicación.
Para ello, analizaremos la última y revolucionaria novedad en Inteligencia Artificial y Procesamiento del Lenguaje Natural (NPL) que ha llegado de la mano de Meta AI, la división de investigación en IA de Facebook: el proyecto NLLB-200.
NLLB: Ningún idioma se queda atrás
Bajo el nombre No Language Left Behind (NLLB), Meta AI ha presentado un software basado en redes neuronales y open source que puede realizar una traducción automática, en tiempo real y con una calidad sin precedentes, a 200 idiomas diferentes.
La compañía ha lanzado el sistema NLLB-200 para impulsar y mejorar la comunicación y eliminar las barreras idiomáticas entre personas de todos los países. Un proyecto que además supondrá una auténtica revolución para el futuro metaverso.

Uno de los aspectos más destacados del proyecto es el extenso número de lenguas a las que es capaz de traducir el modelo, hasta 200. Muchas de ellas, o no funcionaban correctamente, o ni siquiera estaban incluidas entre los idiomas del catálogo de las principales herramientas de traducción actuales.
Son 75 las lenguas minoritarias a las que era imposible acceder a través de las herramientas y sistemas de traducción automática existentes. La llegada del modelo NLLB-200 permitirá a muchos usuarios acceder a más contenidos de la web, compartirlo en su lengua materna y comunicarse con cualquier otra persona de forma inmediata sin ningún tipo de barreras idiomáticas.
Además, la herramienta traduce, indistintamente, tanto el lenguaje oral como el escrito y ya es capaz de proporcionar más de 25.000 millones de traducciones al día en las plataformas de la compañía, entre ellas, Facebook e Instagram.
Funcionamiento del modelo
¿Cómo puede el NLLB-200 traducir directamente entre 200 idiomas diferentes? El procedimiento se divide en tres fases: creación del dataset, aprendizaje y evaluación.
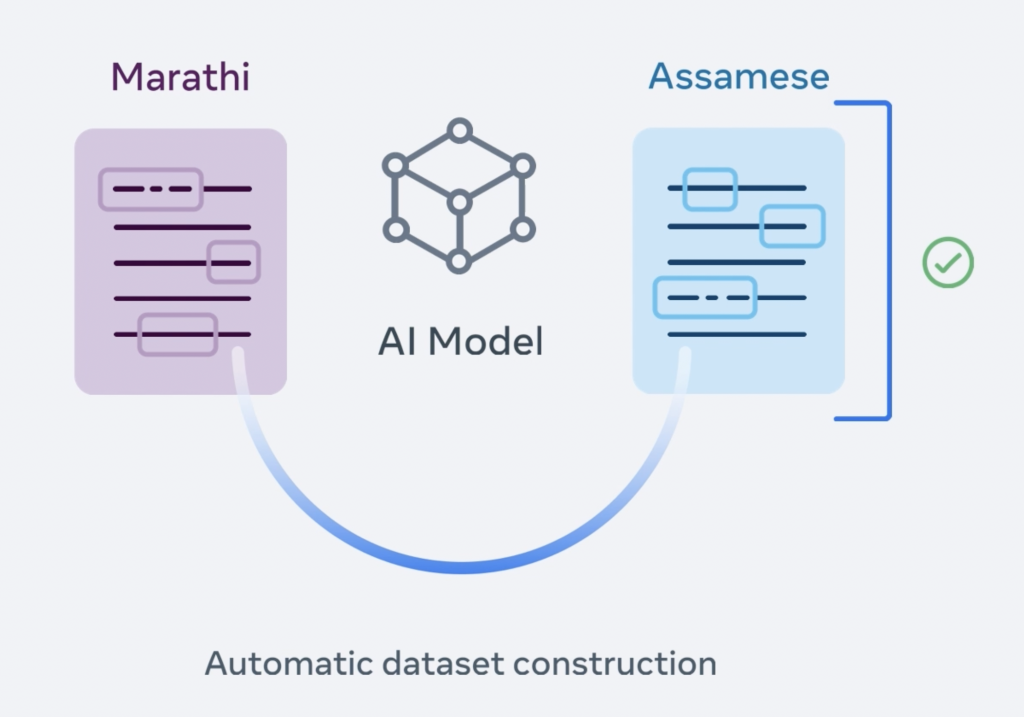
Fase 1: Creación automática del conjunto de datos
En este primer paso se recopilan los datos para entrenar el modelo: oraciones (ya sean escritas u orales) en el idioma original y el lenguaje al que se quiere traducir.
Fase 2: Aprendizaje
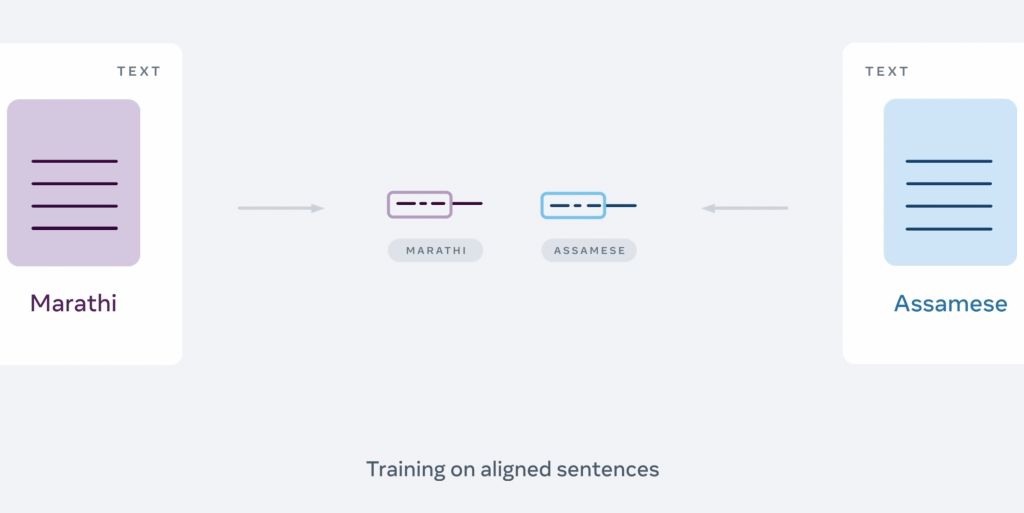
Después de tener los datos de entrenamiento alineados en miles de direcciones distintas, se introducen en el modelo, que se compone de dos partes:
- La primera, el codificador, cuya misión es convertir la frase de origen en una representación vectorial interna.
- Y, la segunda, el decodificador, que se encarga de tomar esta representación y generar la oración del idioma de destino.
Gracias al entrenamiento previo, con miles de traducciones de ejemplo, se obtienen resultados muy precisos.
Fase 3: Evaluación
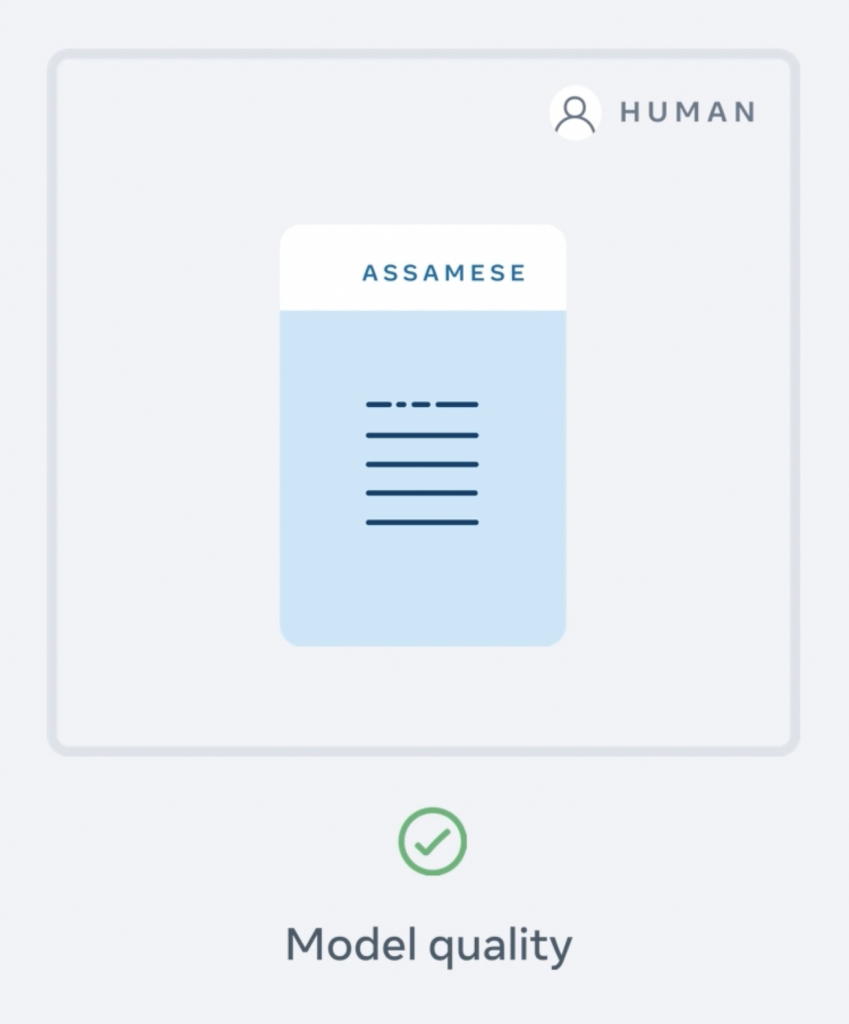
En esta última fase, se evalúa el modelo comparándolo con traducciones que han realizado humanos para comprobar si el resultado posee una calidad satisfactoria.
La evaluación comprende la detección y filtrado de contenido que pueda ser soez u ofensivo mediante el uso de listas de toxicidad que han sido creadas para todas las lenguas que admite el modelo.

Recursos y evolución del proyecto
En 2020 la compañía anunció el M2M-100, un modelo de traducción a 100 idiomas que sirvió de impulso para la recopilación de un mayor número de datos con el objetivo de continuar entrenando y mejorando este tipo de tecnología.
De esta forma, surgió FLORES-200, un nuevo conjunto de datos de evaluación que ha servido para medir el rendimiento del NLLB-200. El modelo ofrece una calidad de resultados que supera en un 44% de media a las tecnologías existentes en la actualidad.
Por otro lado, se ha mejorado la herramienta LASER (representaciones de oraciones agnósticas del lenguaje) dando paso a la nueva versión, LASER3, que recopila textos paralelos más precisos en otras lenguas.
A través del uso de modelos LID-200, se han añadido más pasos de filtrado y limpieza de los datos para disminuir significativamente el ruido y asegurar una buena calidad de los resultados.

Conclusión
Sin duda, lo más importante de este gran avance en Inteligencia Artificial aplicada a la traducción automática de textos es que supondrá el impulso definitivo para el metaverso, la comunidad virtual en la que lleva trabajando Meta y donde está invirtiendo recursos y poniendo en marcha distintas iniciativas para liderar esta nueva forma de relacionarse digitalmente.
También hay que destacar y tener en cuenta el enorme potencial que ofrece el poder contar con un sistema como el NLLB-200 a nivel comunicativo, permitiendo conseguir traducciones en tiempo real, o en cuestión de pocos segundos, entre dos lenguas distintas.
Artículo basado en el blog y la investigación de Meta AI.
¡Esto es todo! Si este post te ha parecido interesante, te animamos a visitar la categoría Algoritmos para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
