
Noam Chomsky said that “Today’s language is no worse than yesterday’s. It is more practical. Like the world we live in”. And it is precisely this concept that we will discuss in this post: how technology has driven the evolution of language to facilitate and automate the communication process.
To do so, we will explore the latest revolutionary development in Artificial Intelligence and Natural Language Processing (NLP) that has come from Meta AI, Facebook’s AI research division: the NLLB-200 project.
NLLB: No Language Left Behind
Under the name No Language Left Behind (NLLB), Meta AI has unveiled an open source, neural network-based software that can perform real-time, automatic translation with unprecedented quality into 200 different languages.
The company has released the NLLB-200 system to boost and improve communication and eliminate language barriers between people from all countries. A project that will also represent a real revolution for the future metaverse.

One of the most outstanding aspects of the project is the extensive number of languages into which the model is able to translate, up to 200. Many of them either did not work properly or were not even included among the languages in the catalogue of the main current translation tools.
There are 75 minority languages that were impossible to access through existing machine translation tools and systems. The arrival of the NLLB-200 model will allow many users to access more web content, share it in their mother tongue and communicate with anyone else immediately without any language barriers.
In addition, the tool translates both spoken and written language interchangeably and is already capable of providing more than 25 billion translations per day across the company’s platforms, including Facebook and Instagram.
How the model works
How can NLLB-200 translate directly between 200 different languages? The procedure is divided into three phases: dataset creation, learning and evaluation.
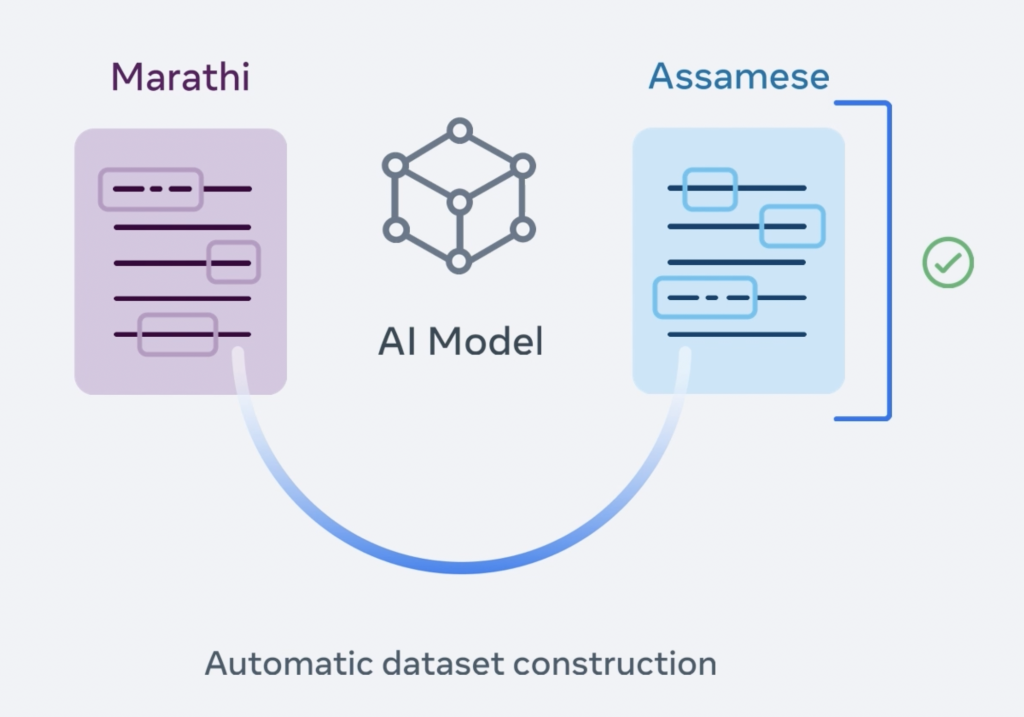
Phase 1: Automatic creation of the dataset
In this first step, the data to train the model is collected: sentences (either written or spoken) in the original language and the language to be translated into.
Phase 2: Learning
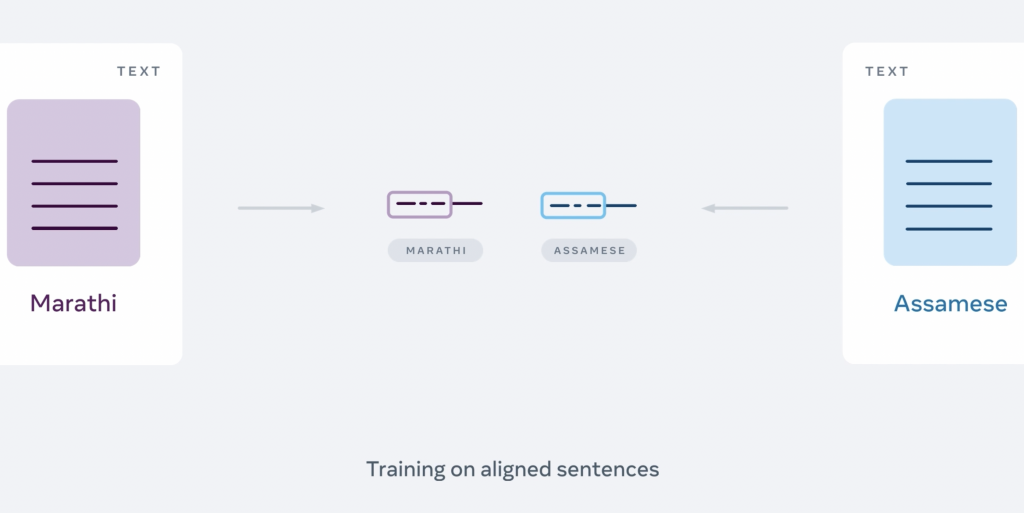
After the training data has been aligned in thousands of different directions, it is fed into the model, which consists of two parts:
- The first, the encoder, whose mission is to convert the source sentence into an internal vector representation.
- The second is the decoder, which takes this representation and generates the target language sentence.
Thanks to prior training, with thousands of example translations, very accurate results are obtained.
Phase 3: Evaluation
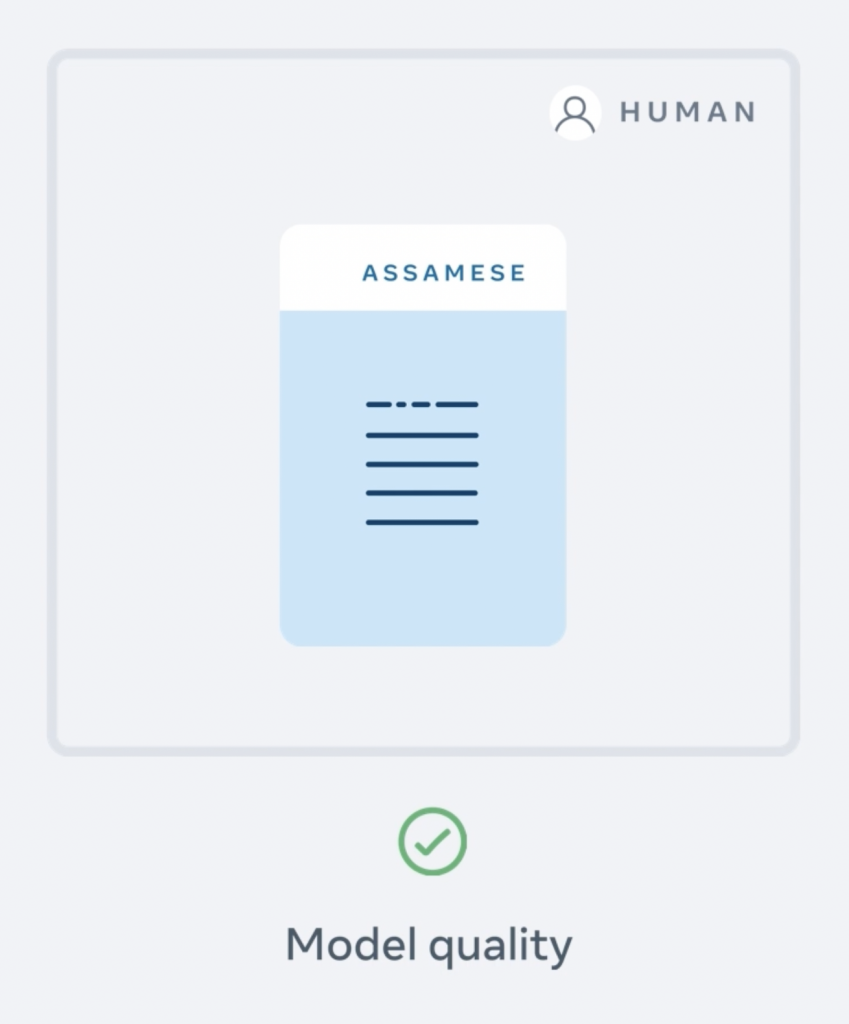
In this last phase, the model is evaluated by comparing it with human translations to check whether the result is of satisfactory quality.
The evaluation involves the detection and filtering of content that may be foul or offensive using toxicity lists that have been created for all the languages supported by the model.

Resources and project evolution
In 2020, the company announced M2M-100, a 100-language translation model that served as the impetus for collecting more data to continue training and improving this type of technology.
This led to FLORES-200, a new evaluation dataset that has been used to measure the performance of the NLLB-200. The model provides a quality of results that outperforms existing technologies by an average of 44%.
On the other hand, the LASER (language-agnostic sentence representations) tool has been improved, leading to the new version, LASER3, which compiles more accurate parallel texts in other languages.
Through the use of LID-200 models, more filtering and data cleaning steps have been added to significantly reduce noise and ensure good quality results.

Conclusion
There is no doubt that the most important thing about this breakthrough in Artificial Intelligence applied to the automatic translation of texts is that it will be the definitive boost for the metaverse, the virtual community in which Meta has been working and where it is investing resources and launching different initiatives to lead this new way of relating digitally.
It is also important to highlight and take into account the enormous potential offered by a system such as the NLLB-200 at a communicative level, making it possible to achieve translations in real time, or in a matter of seconds, between two different languages.
Article based on Meta AI blog and research.
That’s all! If you found this post interesting, we encourage you to visit the Algorithms category to see all the related posts and to share it on your networks. See you soon!
