
Nota: el código de este post ha sido probado utilizando Apache Hadoop 2.10.1. Por favor, consulta el post de Introducción a Apache Hadoop para configurar esta versión de Hadoop en caso de que no lo hayas hecho todavía.
Como ya explicamos anteriormente, Hadoop consta de diferentes componentes entre los que destacan HDFS, MapReduce y YARN. Por un lado, HDFS es un sistema de archivos distribuido, MapReduce es un motor de computación distribuido y, por último, YARN es el gestor que determina cómo se ejecutan los jobs de MapReduce en el clúster.
En la Introducción a Apache Hadoop configuramos un HDFS, pero no podíamos ejecutar jobs en paralelo debido a que no se configuró Apache YARN. Esto implica que MapReduce no se podía llevar a cabo, así que vamos a hacerlo en este post.
Cómo crear usuarios en YARN
Al configurar los servicios de software, es recomendable dar de alta usuarios con permisos limitados para mantener las prácticas adecuadas de los administradores de sistemas.
Antes de configurar un usuario, debes elegir una ubicación donde colocar tu distribución de software para dar permisos al usuario correspondiente y así poder operar dentro de dicha ubicación. Puedes elegir la que más te convenga. Como explicamos en el post de Introducción a Apache Hadoop, en nuestro caso, hemos creado una carpeta en la ubicación /opt/hadoop y un usuario llamado hdoop, que es el propietario de dicha ubicación.
Archivos de configuración
Otra buena práctica de los administradores de sistemas es copiar los archivos de configuración que se van a cambiar en un directorio específico que puede estar vinculado a un sistema de control de versiones (VCS). De este modo, las actualizaciones de software pueden realizarse sin perder ninguna configuración debido a su independencia de la nueva distribución de software descargada.
En la Introducción a Apache Hadoop mostramos cómo seguir esta buena práctica. Con el usuario hdoop, creamos el directorio /opt/hadoop/config-files, que es donde se moverán los archivos de configuración.
Configuración básica de YARN
Los jobs de MapReduce pueden ejecutarse utilizando diferentes frameworks. Dos de estos frameworks son local y yarn. Cuando se utiliza el primero, ningún gestor de clusteres organiza cómo debe paralelizarse un job, por lo que no se produce paralelismo. El segundo requiere que se ejecute Apache YARN, el cual permitirá ejecuciones paralelas.
Para cambiar el framework local (que es la configuración por defecto de Hadoop) y así poder ejecutar jobs de MapReduce utilizando el framework yarn, debemos cambiar la configuración /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml.
Como se ha explicado en la sección anterior, siempre que haya que cambiar un archivo de configuración, es una buena práctica separarlo de la distribución de software para poder enlazarlo con un VCS. Así que vamos a mover este archivo de configuración a /opt/hadoop/config-file y crear un enlace simbólico
mv hadoop/etc/hadoop/yarn-site.xml config-files/
ln -s ~/config-files/yarn-site.xml ~/hadoop/etc/hadoop/yarn-site.xmlA continuación, añade la siguiente propiedad a este archivo de configuración:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>El siguiente paso es cambiar el archivo de configuración /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml. Hay que tener en cuenta que si el archivo de configuración mapred-site.xml sólo existe con el sufijo .template, hay que crear una copia de dicho archivo sin este sufijo. Como antes, primero vamos a mover este archivo a nuestro directorio VCS:
mv hadoop/etc/hadoop/mapred-site.xml.template config-files/mapred-site.xml
ln -s ~/config-files/mapred-site.xml ~/hadoop/etc/hadoop/mapred-site.xmlA continuación, añade la siguiente propiedad:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>Lo creas o no, si sólo se quiere la configuración más básica, esto es todo lo que necesitamos hacer antes de lanzar YARN.
Ejecución de YARN
Así que vamos a lanzarlo. Para ejecutar YARN, ejecuta el siguiente comando:
/opt/hadoop/hadoop/sbin/start-yarn.shPuedes acceder a la UI de Hadoop, donde se pueden ver todos los jobs de MapReduce, gestionados por YARN. Para ver la UI accede a la URL http://localhost:8088/cluster:
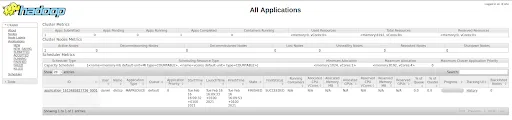
Como puedes ver en la parte inferior de la imagen, hay una nota que dice “No data available in table”. Esto se debe a que aún no hemos ejecutado ningún job. Cada vez que enviemos un job de MapReduce veremos que se crea una fila de dicha ejecución, también llamada Aplicación.
Veamos YARN en acción con un ejemplo.
Ejemplo práctico de Apache YARN
Para ver Apache YARN en acción, vamos a realizar un ejemplo sencillo. Creamos un archivo de texto de 1GB en nuestra máquina local, lo copiamos a HDFS y luego copiamos el archivo ya en HDFS a otro directorio dentro de HDFS.
Crear un archivo de texto
Primero, vamos a crear dicho archivo de texto con el siguiente comando:
dd if=/dev/zero of=filename.big bs=1 count=1 seek=1073741823Comprueba si se ha creado correctamente un archivo llamado filename.big.
El siguiente paso es copiar este archivo a tu HDFS. En nuestro caso, hemos construido un HDFS de demostración en localhost. Puedes hacer lo mismo que nosotros o utilizar cualquier otra distribución de HDFS como S3 de AWS o Azure Data Lake Gen 2 entre otros. Si quieres optar por nuestro enfoque, consulta el artículo de Introducción a Apache Hadoop donde se lanza un HDFS local.
Para asegurarnos de que nuestro HDFS está funcionando, vamos a acceder a la URL http://localhost:50070/. Debe aparecer la siguiente interfaz de usuario:
Copiar el archivo en HDFS
Ahora, vamos a copiar el archivo de texto creado a nivel local en HDFS con el siguiente comando:
hdfs dfs -copyFromLocal filename.big hdfs:///Ten en cuenta que se supone que la ruta de los binarios de Hadoop se añaden a la variable de entorno PATH. El comando anterior no ha ejecutado un job MapReduce, por lo que no se ha producido ningún paralelismo.
Dado que ya tenemos datos en HDFS, a partir de ahora sólo trabajaremos con datos en este sistema de archivos distribuido. Vamos a copiar el archivo que ya existe en HDFS en una carpeta llamada copied. Pero primero tenemos que crear dicho directorio:
hdfs dfs -mkdir hdfs:///copiedEn este punto, la raíz de tu HDFS debe contener lo siguiente:
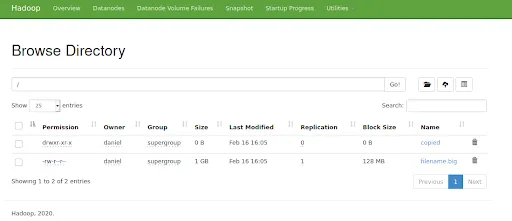
Fíjate en que el archivo filename.big y la carpeta copied han sido creados.
Ahora, copiamos el archivo filename.big al directorio copied. Hay dos formas de hacerlo:
- Una forma es ejecutar la copia sin MapReduce y, por tanto, sin YARN. Ejecuta el siguiente comando para copiar de esta manera:
hdfs dfs -cp hdfs:///filename.big hdfs:///copied/
Si compruebas la UI de Hadoop, verás que no se ha lanzado ninguna aplicación. Esto se debe a que no se ha ejecutado ningún job de MapReduce, por lo que no se produce ningún paralelismo.
- La otra forma de copiar este archivo de texto es ejecutar un job de MapReduce, donde la tarea se ejecuta en paralelo y es gestionada por Apache YARN. Para ello, ejecuta el siguiente comando:
hadoop distcp hdfs:///filename.big hdfs:///copied/
Comprobación del resultado
De una forma u otra, el archivo se copia en la carpeta copied. Por lo tanto, si listamos los elementos dentro de esta carpeta, veremos el siguiente resultado:

La diferencia del segundo enfoque con respecto al primero es que un job de MapReduce ha sido gestionado por YARN. Para comprobarlo, accede de nuevo a la UI de Hadoop:
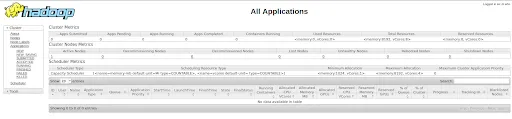
Fíjate en que, donde antes teníamos el mensaje “No data available in table”, ahora tenemos una aplicación con el estado final SUCCEEDED.
Conclusión
¡Genial! Hemos terminado con la introducción a Apache YARN. Hay mucho más que conocer sobre este gestor de clusters, pues en este post sólo hemos arañado la superficie. Tenemos la intención de hacer posts más avanzados donde mostraremos cómo afinar esta herramienta para aumentar el paralelismo, añadir más memoria, etc. ¡No te pierdas nuestras actualizaciones!
Si te ha parecido útil este post, compártelo con tus contactos para que ellos también puedan leerlo y opinar. ¡Nos vemos en redes!
