
In the field of Data Engineering, efficient database design is essential to handle large volumes of data and provide effective analysis. Throughout my experience as a Data Engineer, I have worked with the main data relationship systems and have observed how the relationship models between tables play a crucial role in the organisation, improving the maintenance and optimisation of queries in our Data Warehouse.
Among the most prominent models are the star model, the snowflake model and the galaxy model. Each has its own characteristics, advantages and disadvantages, and are chosen based on specific business needs and data characteristics.
In this post, we will explore these three models in detail, providing clear guidance on when we should choose one or the other depending on our functional and non-functional needs.
Facts, dimensions and standardization
We can divide all our data into two categories: fact tables or dimension tables (masters).
Fact tables
Fact tables contain data about events that have occurred. A fact is usually presented as quantitative and transactional data, representing a key metric or business measure.
Example
In a Data Warehouse where we are storing billing information, the invoice_line table that contains the detailed information of each line within an invoice, would be a fact table.

We see that it is a fact table because it is a transactional table, it represents a detailed measure of a past event, it is used for the company’s operations and its existence depends on the event occurring.
Dimension or master tables
These tables are responsible for providing descriptive context within fact tables. They tend to be much more static than a fact table, that is, they do not grow as much as fact tables and change little. In business operations they tend to be cross-cutting and are used in different contexts.
Example
In our example, we see how the dimension “article” is the definition for the business of what a sales item is. In our case, it has a description, an associated photo, a price, and so on.

Normalised and denormalised tables
When we talk about normalised tables we refer to those tables that avoid storing repetitive data.
Normalized table:
| id_line | id_invoice | id_article | amount | total_price |
| line_1 | invoice_1 | article_a | 2 | 100 |
| line_2 | invoice_1 | article_b | 1 | 100 |
| line_3 | invoice_1 | article_a | 4 | 200 |
Denormalized table:
| id_line | id_invoice | article_description | article_dimensions | article_photo | amount | total_price |
| line_1 | invoice_1 | rectangle box | 100 x 200 | uri://photo_a | 2 | 100 |
| line_2 | invoice_1 | square box | 100 x 100 | uri://photo_b | 1 | 100 |
| line_3 | invoice_1 | rectangle box | 100 x 200 | uri://photo_c | 4 | 200 |
We see that in the denormalised table we have the repeated data while in the normalized table all the context is related by means of the id_article.
Star, Snowflake and Galaxy Models
Star Model
The star model is undoubtedly the most intuitive and one of the most widespread. The name comes from the fact that morphologically it looks like a star when the UML relational model of the tables is embodied.
The system follows some restrictions:
- In the center of the star there can only be a fact table.
- In the peaks we must have dimension type tables.
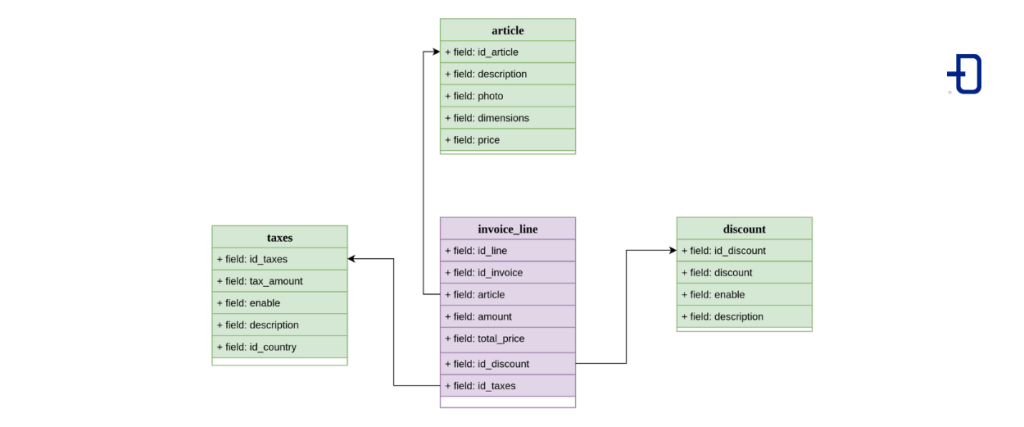
The model in code
SELECT
il.*, a.description, d.discount,t.tax_amount
FROM
invoice_line il
INNER JOIN article a ON a.id_article = il.id_article
INNER JOIN discount ON d.id_discount = il.id_discount
INNER JOIN taxes t ON t.taxes = il.taxesPROS
- It is the simplest of all the models, this makes it very easy to integrate into the organisation, as it is easily understandable.
- It is a model that has very good performance in queries, since we only involve a jump between data. There are always cases where such queries may involve a cardinality of data that can make this model inefficient, but they are usually very fast from a computational point of view.
CONS
- Scalability may be worse, as there is a more inefficient use of storage.
- Working with denormalised tables.
Snowflake Model
This model is an extension of the star model, where the dimensions orbiting around the fact table are related to other dimensions, adding complexity to the model but also allowing to generate a richer context. This model is often used in analytical OLAP models; when working with cubes, one tends to build this model to end up normalising the data into a single table.
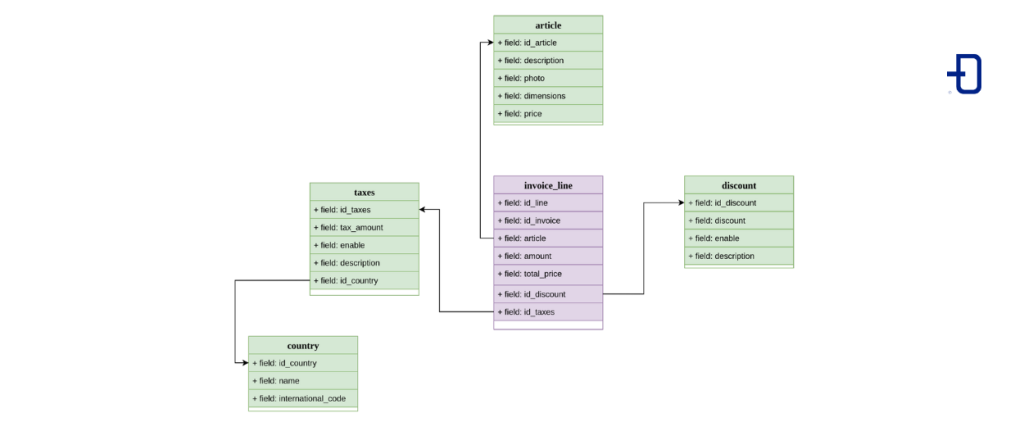
The model in code
SELECT
il.*, a.description, d.discount,t.tax_amount, t.tax_country
FROM
invoice_line il
INNER JOIN article a ON a.id_article = il.id_article
INNER JOIN discount ON d.id_discount = il.id_discount
INNER JOIN (
SELECT t.*,c.name as taxes_countryFROM taxes t
INNER JOIN country c ON t.id_country = c.id_country
) t ON t.id_taxes = il.id_taxesPROS
- Allows you to generate more context around a fact table.
- You work with normalized tables, data redundancy is avoided by adding more layers of context.
CONS
- The code is much more complex since we go to two join levels when working with a dimension.
Galaxy Model
Finally we see the galaxy model, which is an extension of the star model where we find that the fact table is related to another new fact table, which in turn can be related to more dimensions.
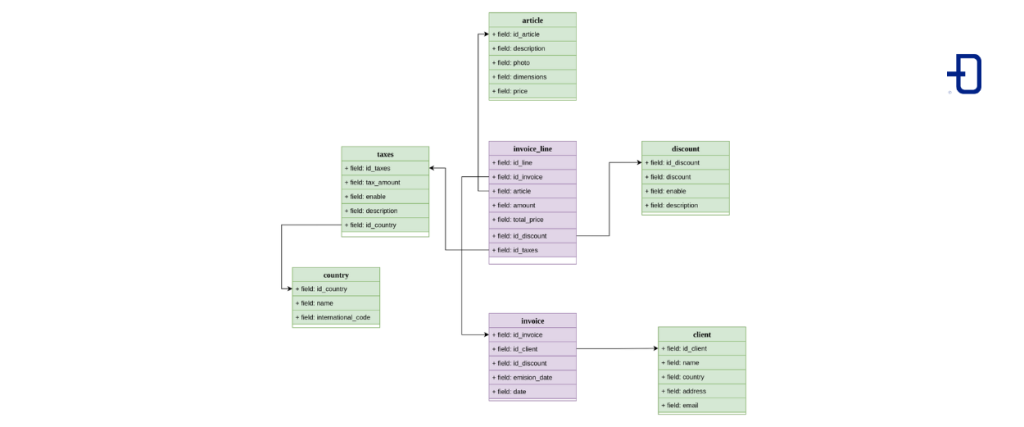
The model in code
SELECT
il.*, a.description, d.discount, t.tax_amount, t.tax_country, ic.client_email
FROM
invoice_line il
INNER JOIN article a ON a.id_article = il.id_article
INNER JOIN discount ON d.id_discount = il.id_discount
INNER JOIN (
SELECT t.*,c.name as taxes_countryFROM taxes t
INNER JOIN country c ON t.id_country = c.id_country
) t ON t.id_taxes = il.id_taxes
INNER JOIN (
SELECT i.*,c.email as client_email FROM invoice i
INNER JOIN clients c ON c.id_client = i.id_client
) ic ON ic.id_invoice = il.id_invoicePROS
- It allows to generate a much richer context.
CONS
- More complexity in understanding the whole Data Warehouse model.
- Poorer performance than the star model.
Conclusion
The most used model nowadays in the construction of a Data Warehouse is usually the star model. In my experience, there is no purist exercise of any of the models and, many times, we end up applying a mixed model, since sometimes the benefits of adding depth levels in the joins are greater than those of modifying existing tables during the life of the tables.
In general, the biggest benefit of using models such as snowflake and galaxy is that we save more disk space, since we have less repeated data. Also, the maintenance of the second-order tables is easier. However, this is not a huge benefit when you consider that the cost of storage is the cheapest thing today and that Data Warehouse solutions like Snowflake directly separate the cost of computation from storage, allowing the two to scale independently.
If response time is a critical factor for your system, a star model will certainly help you.
If you found this article interesting, we encourage you to visit the Data Engineering category to see more posts like this one and to share it on social networks with all your contacts. Don’t forget to mention us (@DamavisStudio) to let us know what you think!
