
En 2020 Apache Spark publicó su versión 3.0.0 con la que se introdujeron cambios en la API para la definición de fuentes de datos personalizadas, conocida dentro del entorno de Spark como Custom Data Source. Estas eran usadas anteriormente a través de DatasourceV2, la cual generaba confusiones y una implementación poco intuitiva debido a algunas abstracciones e incompatibilidades. En Spark 3, a pesar de seguir usando el nombre de DatasourceV2, ha aumentado el número de clases, métodos y abstracciones facilitando la comprensión, la implementación de la API y la posibilidad de combinarla con otras interfaces.
¿Por qué crear un Custom Data Source?
Generalmente, los conectores predeterminados nos servirán para la gran mayoría de casos. Aún así puede ocurrir que trabajemos con algún almacén de datos donde necesitemos un mayor control sobre la fuente de la que leemos o queramos aprovecharnos de alguna de las ventajas que nos puede aportar una fuente personalizada.
El uso de una fuente de datos personalizada puede aportarnos un rendimiento mucho mayor frente al uso de los conectores predeterminados. Además, cuando usamos este tipo de conector, una vez se alcanza el máximo de memoria de un spark executor, se empezarán a volcar los datos al disco, de manera que la memoria no será un problema, a diferencia de la lectura a través de un conector predeterminado.
Spark 2 y principales motivos para el cambio
En la v2.3.0 de Spark aparecía DataSourceV2 que integraba cualquier fuente personalizada de datos y eliminaba las limitaciones de DataSourceV1. Esta interfaz es solo una etiqueta, ya que es una interfaz vacía. Por esto, no es útil para la lectura o escritura de datos por sí sola. En nuestro caso, la combinaremos con la interfaz ReadSupport, la cual añade soporte de lectura a nuestra fuente de datos personalizada. Esta interfaz complementaria es la que permitirá llevar a cabo la instanciación de un DataSourceReader, que a su vez instancia InputPartitions los cuales se envían a los executors de Spark e instancian InputPartitionReaders para la lectura de datos final.
La siguiente imagen muestra las clases y los métodos empleados en esta versión de la API:
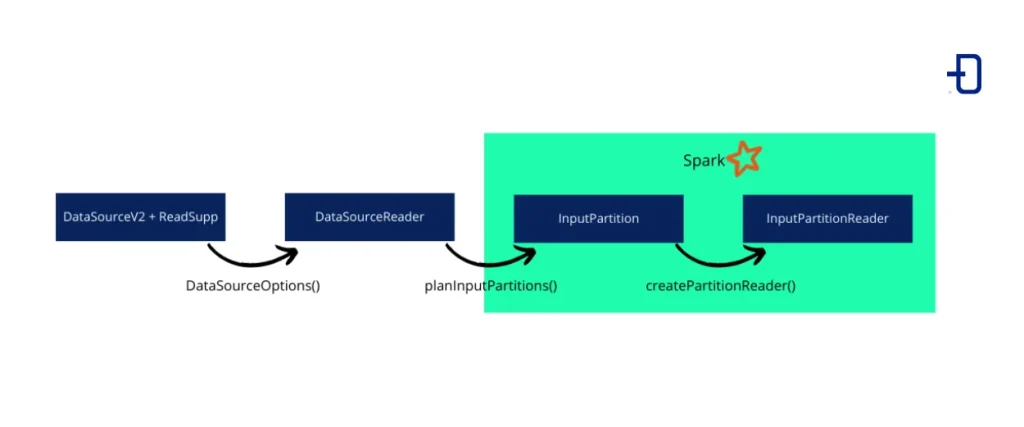
La API ya en esta versión fue marcada con la etiqueta @evolving, es decir, seguiría siendo modificada en nuevas versiones. A medida que era implementada, ya se encontraron con algunas dificultades en el uso que fueron motivo añadido al futuro cambio:
- Confusión en el orden de invocación de interfaces mixtas. Algunas interfaces, como pushdown o column pruning, aportaban flexibilidad pero no era claro dónde debían ser invocadas.
- Las API para Streaming y para Batch no eran del todo compatibles, teniendo que lanzar excepciones para controlar las funcionalidades no soportadas.
- La lectura columnar no era fácil de definir y debía controlarse mediante excepciones.
- Algunas de las clases, como
DataSourceReader, tenían más responsabilidades que las que parecía indicar el nombre. Esto generaba confusión debido a este y otros nombres de clases o interfaces.
Todas estas fueron las motivaciones para proponer un cambio para la versión 3.0.0 de Spark para solventar los inconvenientes presentados.
Cómo funciona la API en Spark 3
A continuación, podemos ver un pequeño esquema con la propuesta de cambio para la lectura de datos:
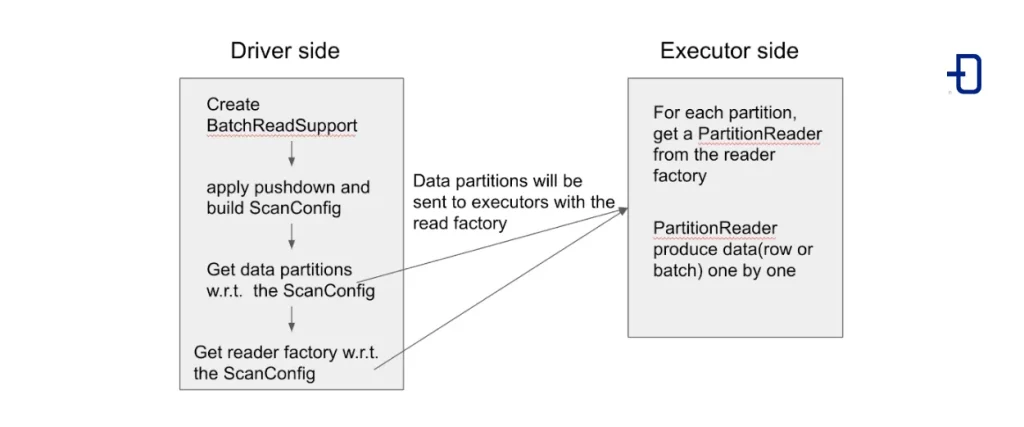
Clases, interfaces y métodos
Las distintas clases, interfaces y los correspondientes métodos que finalmente fueron implementados son los siguientes:
- TableProvider. Obtiene una tabla (dataset estructurado) que puede leer y escribir. Es junto a esta interfaz con la que debemos crear nuestra clase, que será la que indicaremos como
format(MyClass)en una llamadaspark.format(MyClass).read()para hacer uso de la API.
# MyClass extends TableProvider:
def inferSchema(caseInsensitiveStringMap: CaseInsensitiveStringMap): StructType
def getTable(structType: StructType, transforms: Array[Transform], map: util.Map[String, String])- Table. Representa un dataset lógico y se combina con la interfaz
SupportsReadoSupportsWrite. También añadimos la lógica para inferir el schema. - SupportsRead. Interfaz que indica la operación soportada por nuestro
CustomDataSource. En nuestro caso será la lectura de datos.
# MyTable extends Table with SupportsRead:
def name:String
def schema:StructType
def capabilities: TableCapability
def newScanBuilder(options: CaseInsensitiveStringMap): ScanBuilder- ScanBuilder. Se encarga de crear una instancia de la clase
Scan.
# MyScanBuilder extends ScanBuilder
def build(): Scan- Scan. Se combina con la interfaz Batch para crear
InputPartitions. - Batch. Creación de la lista de
InputPartitionsy delreaderFactory. Interfaz combinada conScan.
# MyScan extends Scan with Batch:
def readSchema(): StructType
def toBatch: Batch# Métodos de la interfaz Batch:
def planInputPartitions(): Array[InputPartition]
def createReaderFactory(): PartitionReaderFactory- PartitionReaderFactory. Ya en el executor de Spark, esta clase creará los reader finales para la lectura de datos. Del
InputPartitionpasado por parámetro al método se encarga Spark. Una vez enviado elInputPartitional executor, la propia instancia de la clase se encarga de pasarse como parámetro.
# MyReaderFactory extends PartitionReaderFactory:
def createReader(partition: InputPartition): PartitionReader[InternalRow]- PartitionReader. Lectura de datos. Los métodos no han cambiado desde la versión anterior.
# MyPartitionReader extends PartitionReader
def next : Boolean
def get : T
def close() : UnitCon esta modificación de la API y su extensión conseguimos una mejor comprensión de la misma, las responsabilidades de los distintos elementos y del orden de invocación que se sigue hasta llegar a la lectura final de los datos.
Por otro lado, se disponen de algunas clases como ScanBuilder o PartitionReaderFactory que podrían extenderse para crear clases completamente personalizadas simplemente añadiendo el correspondiente método para que sean instanciadas, facilitando también el uso junto a otras API existentes.
Flujo de trabajo desde la consulta hasta la lectura de datos
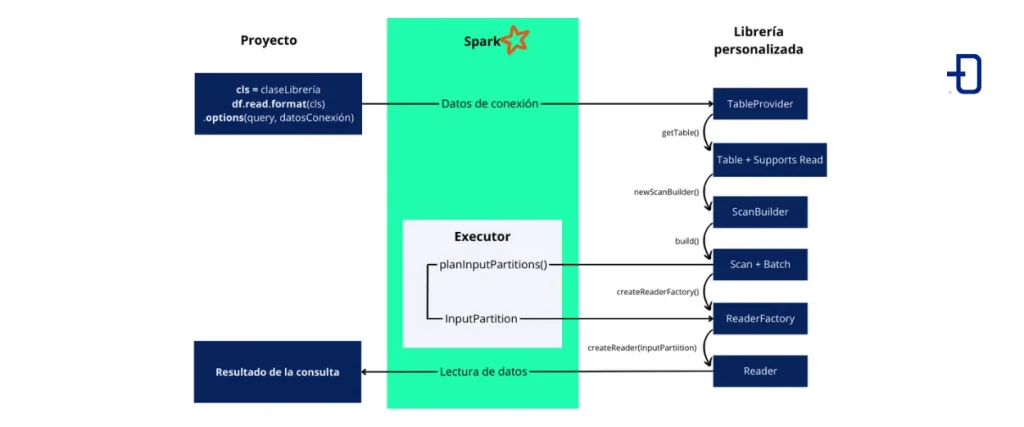
Consideremos uno o varios proyectos donde queremos personalizar la fuente de los datos o bien un mejor rendimiento que el que nos puede aportar el conector predeterminado. Dentro de dicho proyecto ejecutaremos el método .read sobre nuestra clase que implementa la interfaz tableProvider para comenzar con su lectura. El resto de métodos y clases necesarios asumimos que están implementados en una librería externa.
La siguiente imagen muestra el flujo de ejecución hasta el resultado de la consulta a los datos:
Conclusión
La actualización a la versión 3.0.0 de Spark ha traído los cambios comentados en cuanto a la definición de una fuente de datos personalizada, en nuestro caso, para la lectura de los mismos. El uso de este tipo de fuentes de datos nos puede aportar algunas ventajas y soluciones que no consiguen los conectores comunes.
Además, hemos visto los principales cambios para la nueva versión, sus ventajas y soluciones a problemas de la versión anterior, presentando un pequeño ejemplo a alto nivel del flujo de trabajo.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
