
In 2020 Apache Spark released version 3.0.0.0 which introduced some changes to the API for defining custom data sources, known within the Spark environment as Custom Data Source. These were previously used through DatasourceV2, which generated confusion and an unintuitive implementation due to some abstractions and incompatibilities. In Spark 3, despite continuing to use the name DatasourceV2, the number of classes, methods and abstractions has increased, making it easier to understand and implement the API and the possibility of combining it with other interfaces.
Why create a Custom Data Source?
Generally, the default connectors will be useful for the vast majority of cases. However, it may happen that we work with a data warehouse where we need more control over the source from which we read or we want to take advantage of some of the benefits that a custom source can provide.
The use of a custom data source can provide much better performance compared to the use of default connectors. Also, when using this type of connector, once the maximum memory of a spark executor is reached, data will start to be dumped to disk, so memory will not be an issue, unlike reading through a default connector.
Spark 2 and main reasons for the change
Spark v2.3.0 featured DatasourceV2 which integrated any custom data source and removed the limitations of DataSourceV1. This interface is just a label, as it is an empty interface. Because of this, it is not useful for reading or writing data by itself. In our case, we will combine it with the ReadSupport interface, which adds read support to our custom data source. This complementary interface is what will allow us to perform the instantiation of a DataSourceReader, which in turn instantiates InputPartitions which are sent to Spark executors and instantiate InputPartitionReaders for the final data reading.
The following image shows the classes and methods used in this version of the API:
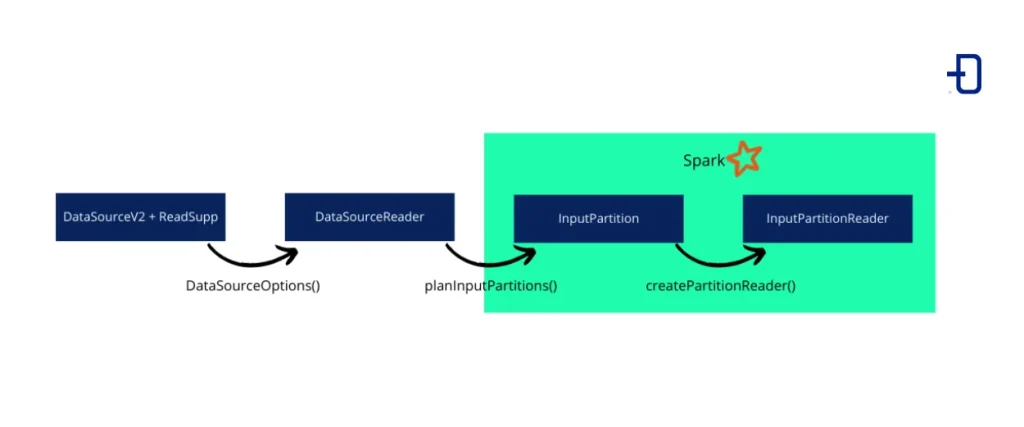
The API already in this version was marked with the @evolving tag, that is, it would continue to be modified in new versions. As it was implemented, some difficulties in its use were already encountered, which were an added reason for the future change:
- Confusion in the order of invocation of mixed interfaces. Some interfaces, such as pushdown or column pruning, provided flexibility but it was not clear where they should be invoked.
- APIs for Streaming and Batch were not fully compatible, having to throw exceptions to control unsupported functionality.
- Columnar reading was not easy to define and had to be controlled by exceptions.
- Some of the classes, such as
DataSourceReader, had more responsibilities than the name seemed to indicate. This generated confusion due to this and other class or interface names.
All these were the motivations for proposing a change for Spark version 3.0.0 to solve the drawbacks presented.
How the API works in Spark 3
Below, we can see a small schematic with the proposed change for reading data:
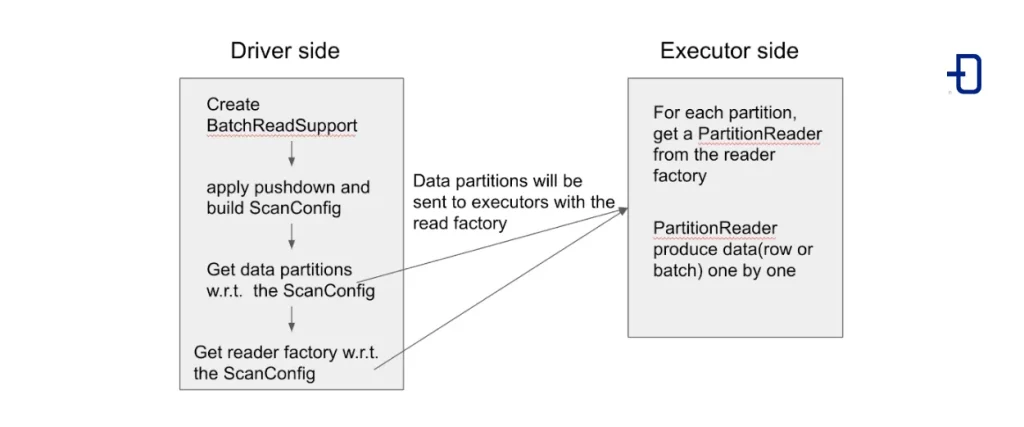
Classes, interfaces, and methods
The different classes, interfaces and the corresponding methods that were finally implemented are the following:
- TableProvider: It obtains a table (structured dataset) that can read and write. It is with this interface that we must create our class, which will be the one we will indicate as
format(MyClass)in a callspark.format(MyClass).read()to make use of the API.
# MyClass extends TableProvider:
def inferSchema(caseInsensitiveStringMap: CaseInsensitiveStringMap): StructType
def getTable(structType: StructType, transforms: Array[Transform], map: util.Map[String, String])- Table: Represents a logical dataset and is combined with the SupportsRead or SupportsWrite interface. We also add the logic to infer the schema.
- SupportsRead: Interface that indicates the operation supported by our CustomDataSource. In our case it will be the data reading.
# MyTable extends Table with SupportsRead:
def name:String
def schema:StructType
def capabilities: TableCapability
def newScanBuilder(options: CaseInsensitiveStringMap): ScanBuilder- ScanBuilder: It is in charge of creating an instance of the
Scanclass.
# MyScanBuilder extends ScanBuilder
def build(): Scan- Scan: Combines with the Batch interface to create
InputPartitions. - Batch: Creation of the
inputPartitionslist and thereaderFactory. Interface combined withScan.
# MyScan extends Scan with Batch:
def readSchema(): StructType
def toBatch: Batch# Batch interface methods:
def planInputPartitions(): Array[InputPartition]
def createReaderFactory(): PartitionReaderFactory- PartitionReaderFactory: Already in the Spark executor, this class will create the final readers for data reading. The
InputPartitionpassed as parameter to the method is taken care of by Spark. Once theInputPartitionis sent to the executor, the class instance itself is in charge of passing it as parameter.
# MyReaderFactory extends PartitionReaderFactory:
def createReader(partition: InputPartition): PartitionReader[InternalRow]- PartitionReader: Reading data. The methods have not changed since the previous version.
# MyPartitionReader extends PartitionReader;
def next : Boolean
def get : T
def close() : UnitWith this modification of the API and its extension we get a better understanding of the API, the responsibilities of the different elements and the invocation order followed until the final reading of the data.
On the other hand, there are some classes such as ScanBuilder or PartitionReaderFactory that could be extended to create completely customized classes by simply adding the corresponding method to be instantiated, also facilitating the use with other existing APIs.
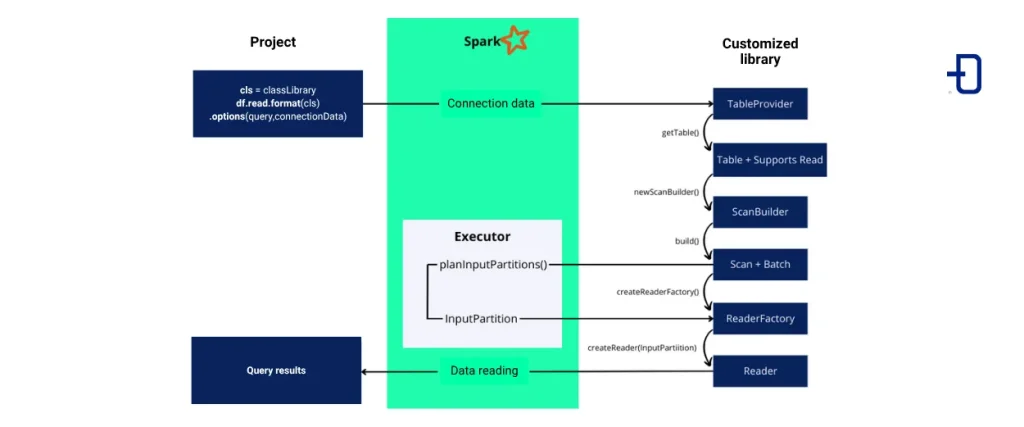
Workflow from query to data reading
Let’s consider one or more projects where we want to customize the data source or better performance than the default connector can provide. Within that project we will execute the .read method on our class that implements the tableProvider interface to start reading it. The rest of the necessary methods and classes we assume that they are implemented in an external library.
The following image shows the execution flow until the result of the data query:
Conclusion
The upgrade to Spark version 3.0.0.0 has brought the changes discussed above regarding the definition of a custom data source, in our case, for reading data. The use of this type of data sources can bring us some advantages and solutions that common connectors do not achieve.
In addition, we have seen the main changes for the new version, its advantages and solutions to problems of the previous version, presenting a small high-level example of the workflow.
If you found this article interesting, we encourage you to visit the Data Engineering category to see similar posts to this one and to share it on social networks. See you soon!
