
Por lo general, cuando comenzamos a trabajar en una nueva integración donde es necesario conectarse a los servicios de AWS en las etapas tempranas del desarrollo, es más fácil y rápido trabajar solo de forma local. Para ello, podemos hacer uso de la herramienta de LocalStack que nos permitirá hacer un mock sobre los servicios de AWS.
¿Qué es LocalStack?
Según sus creadores, Localstack es definido como “A fully functional local AWS cloud stack. Develop and test your cloud & Serverless apps offline!”. Esta herramienta nos proporciona una gama de servicios, de forma gratuita, que nos facilitará el ciclo de desarrollo y testing de un pipeline o integración.
Entre los servicios gratuitos que disponen están: dynamodb, ec2, S3, redshift, lambda, sns, sqs, kinesis, entre otros.
Teniendo esto en cuenta, se podría probar toda una integración recogiendo datos de S3 u otra fuente o realizar algún tipo transformación utilizando, por ejemplo, Spark y subirlo nuevamente a otro bucket de S3. Todo esto sin salir de nuestro entorno de desarrollo.
Integración de Airflow con Localstack
Lo primero que necesitaremos es tener Docker instalado (puedes consultar el post de Introducción a la dockerización y personalización de Apache Airflow para ver cómo se hace) y elegir la imagen de Airflow con la que queremos trabajar. Tenemos que tener en cuenta que la versión de Airflow mínima necesaria es la 2.2.0, ya que tendríamos problemas de compatibilidad si elegimos la última versión del paquete de proveedores de Amazon.
El docker-compose final tendrá 2 configuraciones principales: la configuración de Airflow por un lado y la de LocalStack por otro.
Respecto a la configuración de LocalStack, es importante destacar que se puede agregar una nueva variable de entorno para limitar los servicios que se quieren ejecutar.
environment:
- SERVICES: s3,s3api,dinamodbUna vez tengamos los contenedores levantados, debemos instalar awslocal, haciendo uso del comando pip install awscli-local. AWS local es un wrapper sobre la interfaz de comando de AWS donde se simplifican las peticiones que realizaremos a LocalStack, como podemos ver en el siguiente ejemplo:
- Utilizando aws-cli:
aws --endpoint-url=http://localhost:4566 s3 ls - Utilizando awslocal:
awslocal s3 ls
Probando LocalStack con Airflow y AWS
Para hacer esta prueba sobre LocalStack, sería interesante contemplar el siguiente escenario:
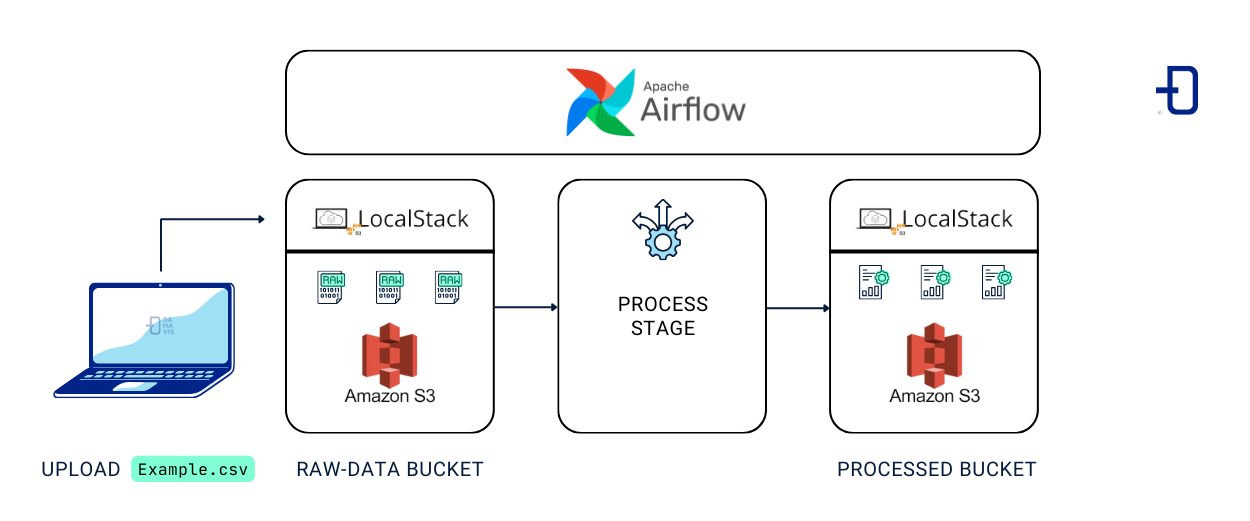
Primero, creamos la estructura de nuestro bucket de S3 desde nuestro host utilizando awslocal. El bucket raw-data se creará como punto de entrada para los datos que no han sido procesados y processed-data para los datos que se han sido manipulados. También, subiremos un fichero (csv) de nuestro ordenador local al bucket de S3 de LocalStack.
Nota: Este paso también se podría hacer utilizando Airflow, pero considero interesante ver cómo podemos manipular el bucket mediante nuestro host y, en los siguientes pasos, como se podría realizar la integración mediante Airflow.
Después, realizamos la conexión de Airflow al contenedor de Localstack.
Por último, ejecutaremos un Dag que descargará el fichero de ejemplo del bucket raw-data, le aplicamos una transformación y luego lo subiremos al bucket processed-data.
Creación de la estructura en S3
$ awslocal s3api create-bucket --bucket raw-data
{
"Location": "/raw-data"
}
$ awslocal s3 cp resources/example.csv s3://raw-data/example.csv
upload: resources/example.csv to s3://raw-data/example.csv
$ awslocal s3api create-bucket --bucket processed-data
{
"Location": "/processed-data"
}Si revisamos el bucket desde el navegador, podemos ver que, efectivamente, estos se han creado y que el documento se ha cargado satisfactoriamente.
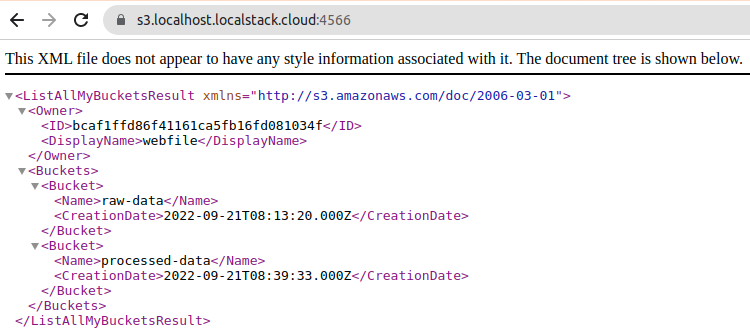
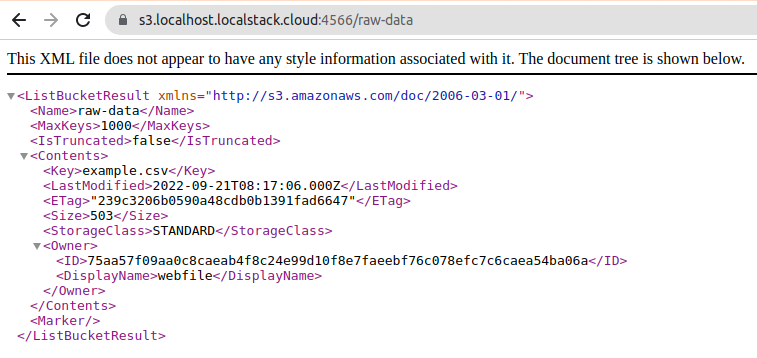
Conectando Airflow con LocalStack
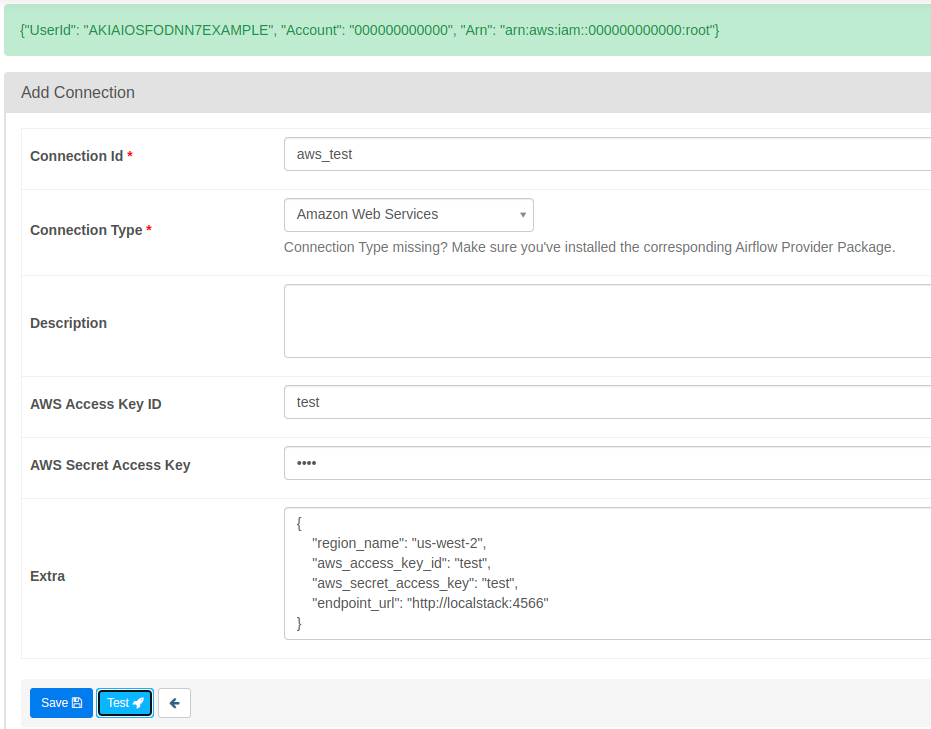
Partimos desde http://localhost:8080 que nos abrirá la ventana de Airflow. Vamos a conexiones y creamos una nueva conexión del tipo Amazon Web Services. En el parámetro ”Extra” agregamos el siguiente JSON.
{
"region_name": "us-west-2",
"aws_access_key_id": "test",
"aws_secret_access_key": “test",
"endpoint_url": "http://localstack:4566"
}En el JSON anterior, la parte más importante es el parámetro endpoint_url, que le indica a Airflow qué endpoint atacar para establecer la conexión con nuestro contenedor de LocalStack.
Al probar la conexión, tendremos el siguiente output que nos informará de que la conexión está lista para ser utilizada.
Realizando el DAG y probando la integración
Para esta demostración, haremos uso del operador S3FileTransformOperator. Este operador descargará los datos desde S3 a nuestro nodo worker, aplicará una transformación utilizando la ruta del script proporcionada y subirá los datos a S3 al bucket destino indicado.
Al utilizar este tipo de operadores, hay que tener en cuenta el volumen de datos que estamos manejando. Airflow no es una herramienta para manipular el dato, sino que debe utilizarse como orquestador de los procesos que manipulan el dato.
from datetime import datetime
from airflow.models import DAG
from airflow.operators.bash import BashOperator
from airflow.models.variable import Variable
from airflow.providers.amazon.aws.operators.s3 import S3FileTransformOperator
SOURCE_KEY = Variable.get("s3_source_key", "s3://raw-data/example.csv")
DEST_KEY = Variable.get("s3_dest_key", "s3://processed-data/example-{{ ts }}.csv")
DEFAULT_ARGS = {
'start_date': datetime(2022, 9, 20),
'schedule_interval': '@hourly',
'catchup': False,
}
with DAG(dag_id='localstack_concept_example',
default_args=DEFAULT_ARGS) as dag:
starting_process = BashOperator(
task_id='starting_process',
bash_command="echo starting process")
transforming_s3_file = S3FileTransformOperator(
task_id='transforming_s3_file',
source_s3_key=SOURCE_KEY,
dest_s3_key=DEST_KEY,
transform_script="/bin/cp",
replace=False)
end_process = BashOperator(
task_id='end_process',
bash_command="echo SUCCESS!")
starting_process >> transforming_s3_file >> end_processUna vez ejecutado el DAG obtendremos la siguiente respuesta:
[2022-09-21, 10:16:58 UTC] {s3.py:567} INFO - Downloading source S3 file s3://raw-data/example.csv
[2022-09-21, 10:16:59 UTC] {s3.py:573} INFO - Dumping S3 file s3://raw-data/example.csv contents to local file /tmp/tmpet619eys
[2022-09-21, 10:16:59 UTC] {s3.py:589} INFO - Output:
[2022-09-21, 10:16:59 UTC] {s3.py:600} INFO - Transform script successful. Output temporarily located at /tmp/tmputbuquyr
[2022-09-21, 10:16:59 UTC] {s3.py:603} INFO - Uploading transformed file to S3
[2022-09-21, 10:16:59 UTC] {s3.py:610} INFO - Upload successfulSi revisamos el bucket, podemos ver que el archivo se ha creado, por lo que el proceso se ha realizado correctamente.
$ awslocal s3 ls s3://processed-data
2022-09-21 12:16:59 503 example-2022-09-21T10:16:56.771385+00:00.csvConclusión
En este post hemos visto qué simple y sencillo es realizar una integración con Airflow y LocalStack para comenzar a desarrollar pipelines sin salir de nuestro entorno local, siendo una buena herramienta para comenzar con el desarrollo en una etapa temprana sin incurrir en gastos innecesarios.
Hasta aquí nuestro post de hoy. Si te ha parecido interesante, te animamos a visitar la categoría Software para ver artículos similares y a compartirlo en redes con tus contactos. ¡Hasta pronto!
