
Airflow es un framework de código abierto para desarrollar, orquestar y monitorizar flujos de trabajo en batch. En caso de no estar familiarizado con él, y para entender mejor el contenido de este artículo, es recomendable repasar los conceptos básicos de Apache Airflow que ya analizamos hace un tiempo en nuestro blog.
Como orquestador, el framework está provisto de algunas herramientas que le permiten controlar la ejecución de tareas a distinto nivel. Anteriormente, vimos el uso de sensores de Apache Airflow en detalle así como el manejo avanzado de dependencias entre distintos DAGs. El concepto más sencillo relacionado con el manejo de dependencias entre tareas del mismo DAG son las trigger rules. Este post, pretende ser un repaso sobre las opciones y posibilidades que Airflow ofrece al respecto.
¿Qué son las trigger rules?
En Airflow, los operadores poseen un argumento llamado trigger_rule que define los requisitos necesarios para que la tarea pueda proceder a ejecutarse en el flujo de trabajo. A nivel práctico, esto se traduce en definir las condiciones que tienen que haber cumplido las ejecuciones de las tareas anteriores en el flujo de trabajo (upstream), antes de dar luz verde para ejecutar la tarea siguiente (en la que se establece la trigger rule).
El valor por defecto de este argumento es all_success, con lo cual una tarea nunca se ejecutará a no ser que todas las tareas upstream inmediatamente anteriores también lo hayan hecho con éxito. Por ejemplo, en la vista siguiente, la tarea last_task se ha ejecutado porque todas las parallel_task_* de la 1 a la 5 se han ejecutado con éxito.
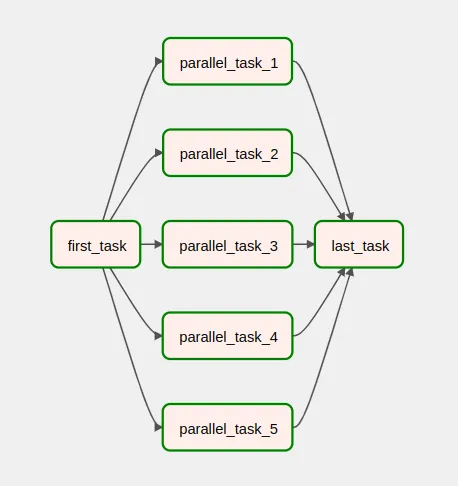
Descripción de las trigger rules
En Airflow, las instancias de tareas (task instances) pueden tener varios estados. Una lista de ellos está disponible en la Graph View de la UI:

Para entender las trigger rules básicas, basta con considerar los estados failed, skipped, success y upstream_failed. Son bastante autodescriptivos, aunque los definiremos de cara a entender mejor las condiciones lógicas subyacentes en el argumento.
- failed implica que una tarea falló.
- skipped quiere decir que la tarea no llegó a ejecutarse, aunque las tareas upstream no fallaron.
- succes significa que la tarea se ejecutó con éxito.
- upstream_failed hace referencia a que la tarea no se ejecutó porque las tareas upstream fallaron.
Tipos de trigger rules en Airflow
Incluyendo la opción all_success que hemos visto antes, Airflow ofrece las siguientes trigger rules:
| success | done* | skipped | failed | |
| none | none_skipped | none_failed / none_failed_min_one_success / none_failed_or_skipped | ||
| one | one_success | one_done | one_failed | |
| all | all_success | all_done | all_skipped | all_failed |
| always / dummy | always / dummy | always / dummy | always / dummy |
*done hace referencia a tareas efectivamente ejecutadas, con o sin éxito.
- none_skipped: Ninguna tarea upstream está en estado skipped.
- none_failed: Ninguna tarea upstream está en estado failed ni upstream_failed.
- none_failed_or_skipped: Ninguna tarea upstream está en estado skipped, failed o upstream_failed.
- none_failed_min_one_success: Ninguna tarea upstream está en estado failed ni upstream_failed y como mínimo una de ellas está en estado success.
- one_success: De las tareas upstream, por lo menos una está en estado success. Esta trigger rule no espera a que terminen las demás tareas.
- one_done: De las tareas upstream, por lo menos una se ejecutó (acabase en estado success o failed).
- one_failed: De las tareas upstream, por lo menos una está en estado failed o upstream_failed. Esta trigger rule no espera a que terminen las demás tareas.
- all_success: Todas las tareas upstream están en estado success.
- all_done: Todas las tareas upstream se han ejecutado (estén en estado success o failed).
- all_skipped: Todas las tareas upstream están en estado skipped.
- all_failed: Todas las tareas upstream están en estado failed o upstream failed.
- always: La tarea se ejecutará independientemente del estado de las tareas upstream.
Casos de uso de trigger rules
En muchos casos, la opción por defecto all_success es suficiente para garantizar que las tareas se ejecutan en el orden determinado por sus respectivas dependencias. En otras ocasiones, el flujo de trabajo puede contener ciertas complejidades que convierten all_success en una limitación.
Un caso claro viene dado con el uso de branching. Al condicionar la ejecución de una u otra tarea dependiendo de una condición, las tareas posteriores en el flujo de ejecución pueden depender de que solo una de ellas se haya ejecutado con éxito. Un caso de ejemplo con branching sería el siguiente:
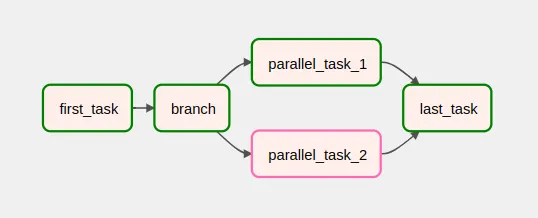
Unas veces, el branching determinará que se ejecuta parallel_task_1 y, otras, parallel_task_2. Sin embargo, con la trigger rule one_success la tarea last_task se ejecutará independientemente de cuál de ellas acabe en success.
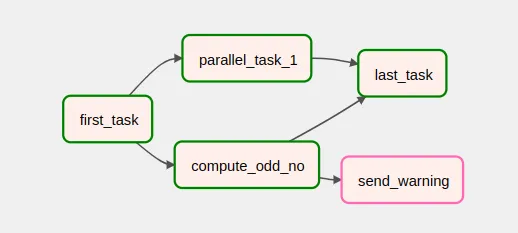
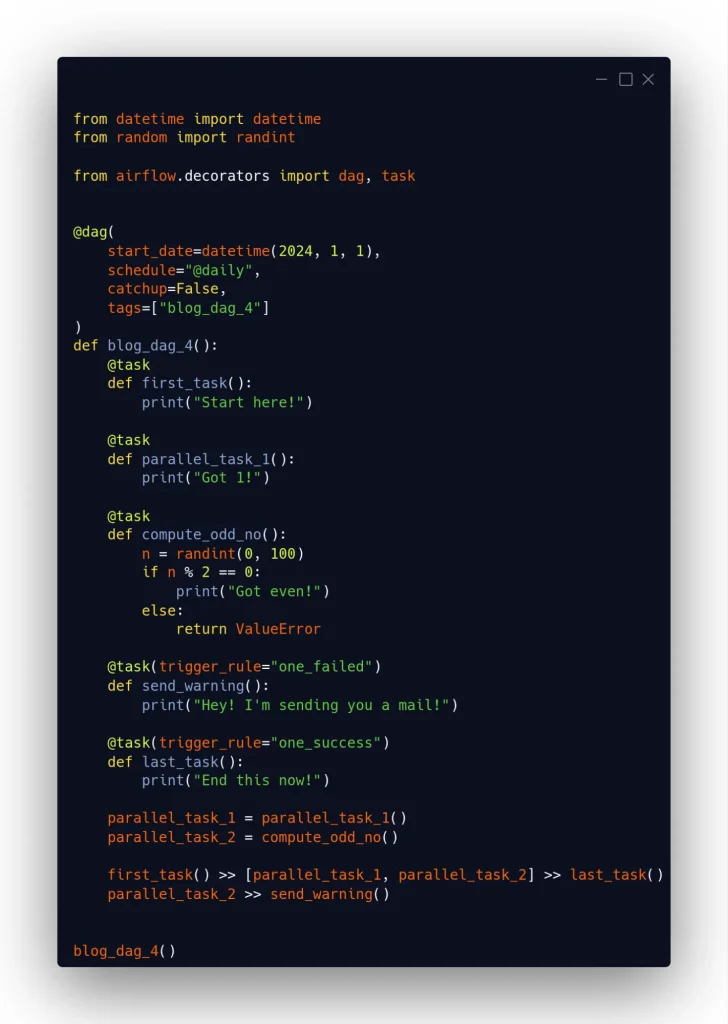
En este otro caso, a veces falla el proceso compute_odd_no. Cuando esto se produce, se ejecuta un proceso send_warning que, por ejemplo, enviaría una notificación. Y cuando compute_odd_no no falla, la tarea send_warning no se ejecuta.
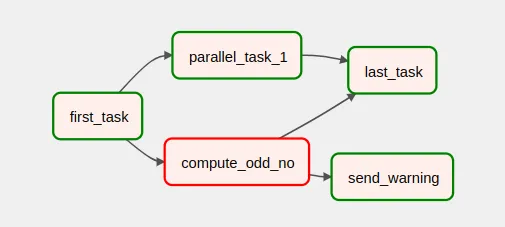
En este caso, last_task también tiene un trigger rule one_success. Es importante recalcar que, aun cuando ni parallel_task_1 ni compute_odd_no fallaran, la ejecución de last_task empezaría enseguida que uno de los dos hubiera terminado en success, sin esperar a que terminara el otro proceso.
Más allá de las trigger rules
Al principio de esta entrada, ya se refirió al uso de sensores y a la gestión de dependencias entre DAGs como elementos adicionales a las trigger rules para controlar el flujo de ejecución de tareas. Esto debería cubrir la mayoría de casos de uso en procesos ETL. Sin embargo, pueden existir situaciones en las que estas herramientas resulten insuficientes o demasiado complejas de integrar en comparación con la implementación de lógica en el código de las tareas.
Algunos ejemplos incluyen:
- Dependencias de estados específicos en los que una combinación de tareas upstream hayan terminado con unos estados determinados. Por ejemplo, si en el DAG 1 se quisiera ejecutar last_task solamente en el caso de que parallel_task_1 y parallel_task_2 hayan terminado en success y las otras 3 en failed.
- Dependencias basadas en la naturaleza del error eventualmente producido. Por ejemplo, ejecutar una tarea si la tarea upstream ha terminado con un error de tipo ValueError, pero no si el tipo del error es cualquier otro.
- Dependencias basadas en la estructura de los datos de entrada en un proceso.
- Dependencias que no se ajustan a la estructura de un DAG, como es el caso de tareas interdependientes.
En estos casos, es mejor manejar las dependencias a nivel interno de las tareas que con las herramientas que ofrece Airflow. En otros contextos, el manejo de dependencias dentro de las tareas puede ser preferible para reducir la complejidad en los DAGs. Será necesario ponderar estas complejidades para decidir cuál es la mejor solución en cada caso, teniendo en cuenta factores como la simplicidad e interpretabilidad del código.
Conclusión
En este post se han repasado las trigger rules que Apache Airflow ofrece para gestionar las dependencias entre tareas del mismo DAG. Las trigger rules disponibles son suficientes para orquestar la mayoría de casos de uso en procesos ETL y conocer las opciones puede ser útil para evitar tener que introducir complejidad en los DAGs. En todo caso, y como apunte final, cabe recordar que, incluso con las otras herramientas que Airflow ofrece, puede haber ejemplos en que no compense del todo usarlas o resulten insuficientes para gestionar algún tipo específico de dependencia.
¡Eso es todo! Si este artículo te ha resultado interesante, te animamos a visitar la etiqueta Airflow para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
