
RAG son siglas para «retrieval augmented generation», o en castellano “generación aumentada por recuperación”. Con RAG se pretende que un «gran modelo de lenguaje» (LLM en adelante, siglas en inglés de «Large Language Model») pueda utilizar información adicional suministrada por un usuario. Los LLM son entrenados en grandes cantidades de texto, obtenido generalmente de internet. Sin embargo, sería muy interesante que pudiesen responder a preguntas relativas a documentos privados de individuos y organizaciones, datos sobre los cuales no han sido entrenados.
Una posible solución a este problema es el reentrenamiento del modelo. Esto involucra modificar los parámetros internos del LLM entrenándolo sobre los nuevos documentos. Por desgracia, este proceso es computacionalmente muy costoso: tanto el propio proceso de reentrenamiento como el hardware necesario para desplegar un modelo quedan fuera del alcance de la mayoría.
El RAG pretende aumentar sus capacidades con nuevos datos sin estas desventajas, de una manera distinta, cediéndole en las interacciones la documentación necesaria para ofrecer respuestas en contextos nuevos o particulares.
Fundamentos de la técnica de RAG
A lo largo del artículo nos referiremos a una documentación privada, entendiéndose esta por colección arbitraria de documentos de texto, de cualquier naturaleza y formato (una colección de PDFs de artículos de investigación, HTML de páginas web, archivos en Markdown de una Wiki interna, tickets en un sistema de organización de trabajo, etcétera).
El objetivo es que un LLM nos responda preguntas relativas a esta documentación, de manera veraz y fiable.
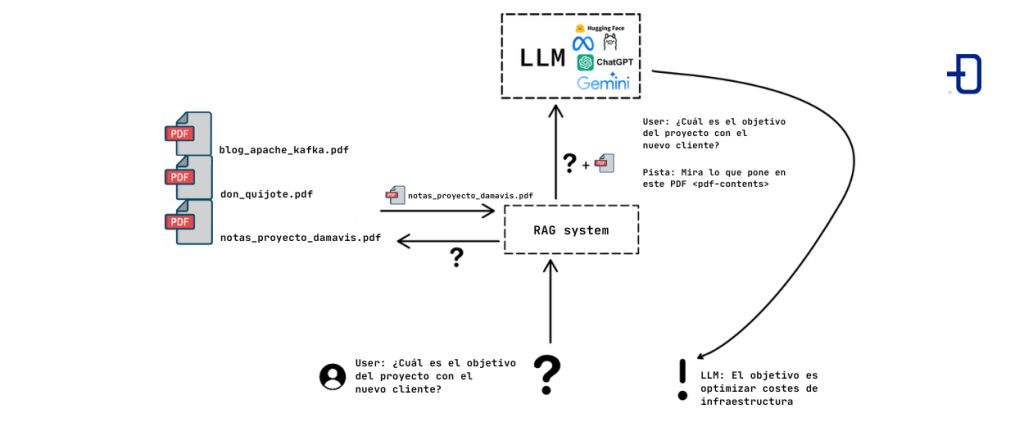
La idea básica de un sistema de RAG es proveer al LLM de un contexto que le permita responder al usuario. Ya que el contexto que se le puede pasar a un LLM es finito, no es viable ni eficiente darle toda una documentación (e.g. miles de PDFs) para que trate de construir la respuesta a partir de todos ellos.
Por tanto, se busca obtener o recuperar (de ahí la R de retrieval) los documentos más pertinentes para generar (G de generation) una respuesta adecuada, aumentando la capacidad del LLM de responder a preguntas sobre el contexto específico que provee el usuario, no pudiendo contestar de otra manera ya que dicha información no se encontraba en sus datos de entrenamiento.
Si bien hay métodos clásicos como búsquedas por palabras clave ampliadas con diccionarios de sinónimos o TF-IDF que permiten resolver parcialmente este problema, es posible reutilizar la arquitectura de los propios modelos de lenguaje para articular búsquedas semánticas mucho más complejas y precisas.
Embedding
El embebimiento o embedding es una técnica de codificación de texto en estructuras matemáticas sobre las que aplicar algoritmos o construir modelos. El embedding consiste en asociar a cada palabra, frase, párrafo o documento de longitud determinada un vector de números, en un espacio de representación donde dicho texto se considera “embebido”.
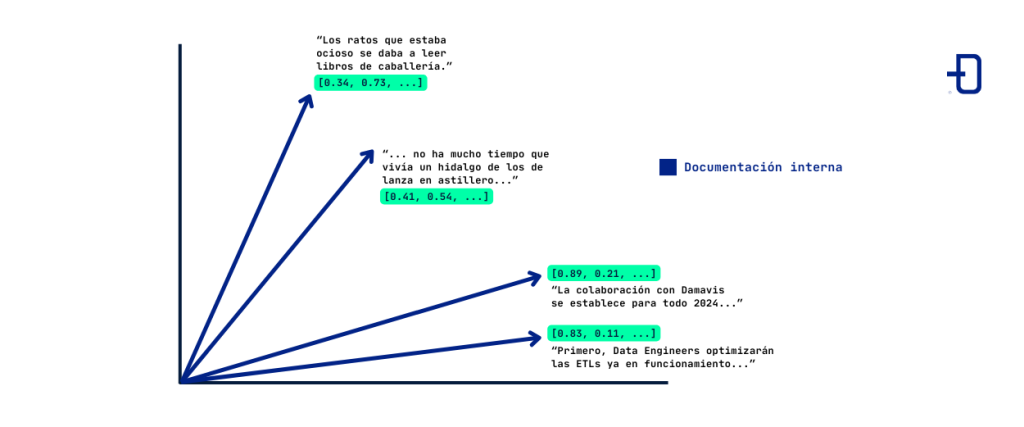
En la imagen observamos cómo cuatro párrafos distintos han sido representados por cuatro vectores, que por simplicidad asumimos viven en un espacio de dos dimensiones. En la práctica, se requieren dimensiones altas; un modelo de embedding usual como text_embed_ada requiere 1536 dimensiones.
El modelo de embedding será adecuado si textos semánticamente relacionados se asignan a vectores que sean cercanos. En la práctica, los modelos de embedding utilizan una arquitectura compleja y redes neuronales. Son entrenados en un extenso corpus de texto en lenguaje natural, buscando trasladar cercanía semántica en cercanía de los vectores asociados.
La componente de recuperación (o “retrieval”) de sistemas de RAG se articula, pues, de esta manera: consideramos un conjunto de documentos textuales (por ejemplo, una carpeta llena de PDFs o ficheros Markdown). En primer lugar, se “trocean” estos documentos en elementos más pequeños, de una longitud máxima prefijada, llamados “nodos”. Un tamaño excesivo de nodos sobrepasará el contexto máximo del LLM, mientras que un tamaño muy pequeño de nodos fallará en la captura de información relevante.
Una vez obtenidos estos nodos, se calculan sus vectores asociados a través de un modelo de embedding. Estos vectores se pueden almacenar en bases de datos especialmente diseñadas para vectores de gran cantidad de componentes (e.g. Pinecone, Milvus, la extensión pg_vector de Postgres, etcétera), que los guardan haciendo una gestión eficiente de la memoria y permitiendo, a través de distintas técnicas de indexado, mejorar la eficiencia de la búsqueda de vectores vecinos.
Cuando un usuario hace una consulta a un sistema de RAG, se calcula el embedding correspondiente a dicha pregunta. El sistema utiliza entonces una métrica de cercanía en el espacio de vectores y selecciona los nodos de texto cuyos vectores son los más cercanos semánticamente a dicha pregunta. Una métrica usual para esto es la similitud coseno.
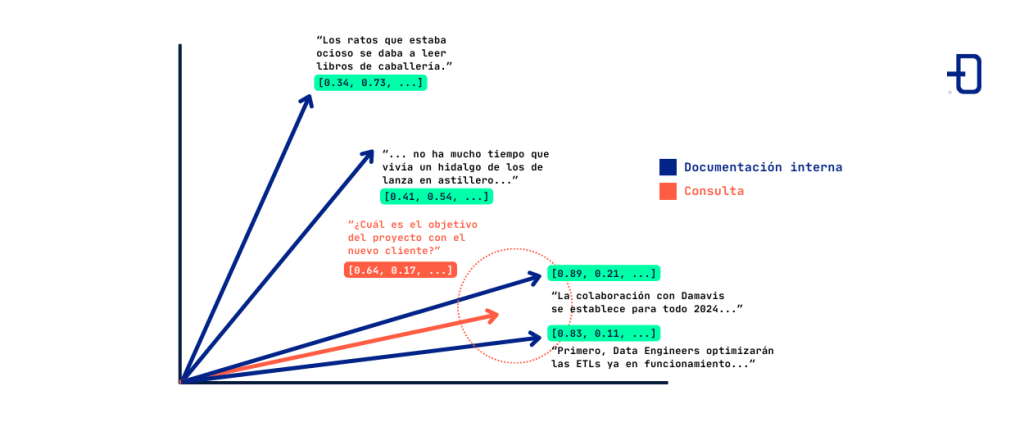
En este ejemplo, la pregunta “¿Cuál es el objetivo del proyecto con el nuevo cliente?” es embebida en un vector (en rojo) que resulta ser cercano a los vectores que corresponden a texto referido a proyectos con un hipotético nuevo cliente de Damavis. El sistema seleccionará el texto correspondiente a estos dos vectores para posteriormente dar una respuesta al usuario.
El cálculo de los vectores más cercanos puede refinarse: los sistemas y bases de datos pensadas para RAG permiten enriquecer los vectores con metadatos (información como fecha, fuente, resumen del documento, palabras clave), permitiendo desarrollar estrategias de recuperación híbridas entre el embedding y otras técnicas clásicas de filtrado y búsqueda por palabras clave. Además, es usual enlazar distintos nodos de texto que hayan sido obtenidos a partir del mismo documento, a nivel de metadatos.
El coste computacional de cálculo de los vectores más cercanos semánticamente a un vector de consulta dado escala super-linealmente (en el mejor de los casos) con el tamaño de la documentación, como será familiar a quienes hayan trabajado con el algoritmo k-Nearest Neighbors.
Hay técnicas que modifican la arquitectura de la base de datos vectorial, permitiendo implementar búsquedas aproximadas; esto sacrifica la certeza de recuperar los documentos más cercanos a cambio de una notable disminución en el coste de cálculo, lo cual es importante a la hora de servir el sistema en un chatbot cuando la documentación es extensa y la latencia admisible es baja. Como ejemplo de estas técnicas de cálculos aproximados podemos citar HNSW (Hierarchical Navigable Small Worlds).
El embedding no está limitado a texto; es posible calcular, a través de redes neuronales convolucionales (CNN, por sus siglas en inglés), embeddings de imágenes, asignando a cada imagen un vector en un espacio de altas dimensiones. Así, se traducen imágenes similares en vectores cercanos bajo alguna métrica. Este es el método que está a la base de herramientas de búsqueda inversa de imágenes, por ejemplo. Más allá de imágenes, el embedding es aplicable en distintas variantes otros formatos de documentos estructurados (audio, vídeo) y semi-estructurados (objetos JSON, esquemas de bases de datos).
Es importante notar que es posible utilizar distintas métricas para medir la cercanía entre vectores. Algunas de ellas son la similitud coseno (ángulo formado entre los vectores) o la norma L2 (la raíz cuadrada de los cuadrados de las diferencias de las componentes); la elección de una u otra depende, por ejemplo, del tipo de datos. Para texto, es usual utilizar la similitud coseno (donde la magnitud de los vectores es menos relevante) mientras que para tratar con imágenes se utiliza la norma L2.
Generación
Una vez se han recuperado los documentos más pertinentes (en un sentido semántico) para responder a la pregunta, el sistema de RAG debe generar una respuesta basada en los mismos. Recordemos que, en general, la documentación es de contenido que no está en los datos de entrenamiento del LLM que usaremos para la elaboración de respuestas.
Las implementaciones de generación pueden ser muy variadas en función del LLM usado, el objetivo del sistema de RAG y de la naturaleza de la documentación. Como ejemplo más básico, se consulta a un LLM con la pregunta original del usuario, concatenada con los nodos de la documentación que resultan ser más cercanos, como por ejemplo:
Prompt de usuario:
A continuación sigue una pregunta, y posteriormente, información pertinente que debe ser utilizada para responder a dicha pregunta.
Pregunta:
¿Cuál es el objetivo del proyecto con el nuevo cliente?
Información:
- “La colaboración con Damavis se extenderá a lo largo de 2024, en la cual se verán involucrados los equipos de Data Science y Data Engineering”.
- “Primero, Data Engineers optimizarán las ETLs ya implementadas, y el equipo de Data Science propondrá nuevos modelos de predicción que permitan obtener una mejora en los costes de infraestructura digital de la empresa cliente”.
Respuesta del LLM:
El objetivo del proyecto es mejorar la eficiencia para disminuir costes en infraestructura.
Los sistemas de RAG combinan por tanto técnicas de búsqueda avanzadas con ingeniería de consultas (“prompt engineering”), y distintas estrategias de procesar los documentos cercanos a la consulta dan lugar a distintos comportamientos, deseables en función del objetivo del sistema.
Conclusión
En este artículo se exponen las bases de la técnica del RAG. Hemos abordado cómo convertir documentos en vectores a través de modelos de embedding que posibilitan hacer búsquedas semánticas sobre la base documental. Esto permite rescatar dinámicamente información adicional para un LLM, incrementando sus capacidades con una documentación extra provista por el usuario.
En un post futuro hablaremos de implementaciones de sistemas de RAG a través una librería muy popular llamada LlamaIndex, además de exponer algunas extensiones del RAG.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Science para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
