
RAG stands for “retrieval augmented generation”. RAG is intended to allow a “large language model” (LLM) to use additional information provided by a user. LLMs are trained on large amounts of text, usually obtained from the Internet. However, it would be very interesting if they could answer questions relating to private documents of individuals and organizations, data on which they have not been trained.
One possible solution to this problem is to retrain the model. This involves modifying the internal parameters of the LLM by training it on the new documents. Unfortunately, this process is computationally very expensive: both the retraining process itself and the hardware needed to deploy a model are beyond the reach of most.
The RAG aims to augment its capabilities with new data without these disadvantages, in a different way, by yielding in interactions the documentation needed to provide answers in new or particular contexts.
Fundamentals of RAG technique
Throughout the article we will refer to a private documentation, meaning an arbitrary collection of text documents, of any nature and format (a collection of PDFs of research articles, HTML of web pages, Markdown files of an internal Wiki, tickets in a work organization system, etc.).
The objective is to have an LLM answer questions related to this documentation, truthfully and reliably.
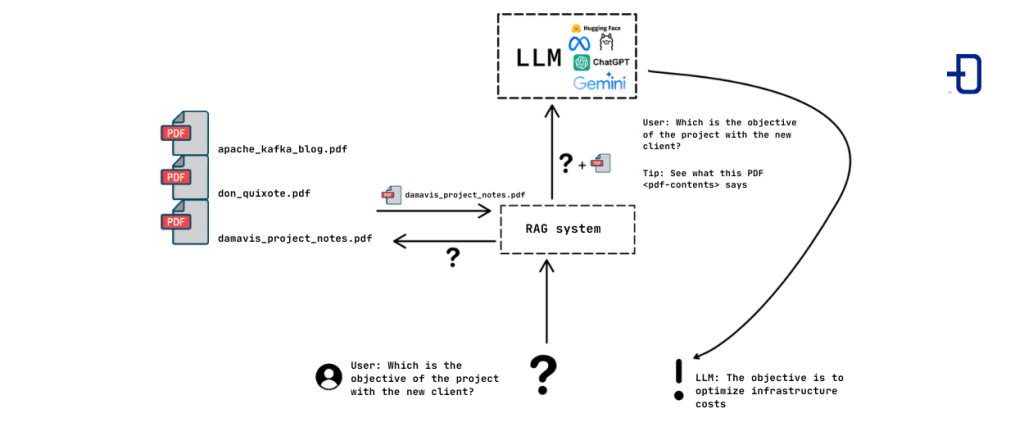
The basic idea of a RAG system is to provide the LLM with a context that allows it to respond to the user. Since the context that can be passed to an LLM is finite, it is neither feasible nor efficient to give it a whole documentation (e.g. thousands of PDFs) to try to build the answer from all of them. Therefore, we seek to obtain or retrieve (hence the R of retrieval) the most relevant documents to generate (G of generation) an appropriate answer, increasing the LLM’s ability to answer questions about the specific context provided by the user, not being able to answer otherwise since such information was not found in its training data.
While there are classical methods such as keyword searches extended with thesaurus or TF-IDF that partially solve this problem, it is possible to reuse the architecture of the language models themselves to articulate much more complex and accurate semantic searches.
Embedding
This technique is used to encode text into mathematical structures on which to apply algorithms or build models. Embedding consists of associating a vector of numbers to each word, sentence, paragraph or document of a given length, in a representation space where the text is considered “embedded”.
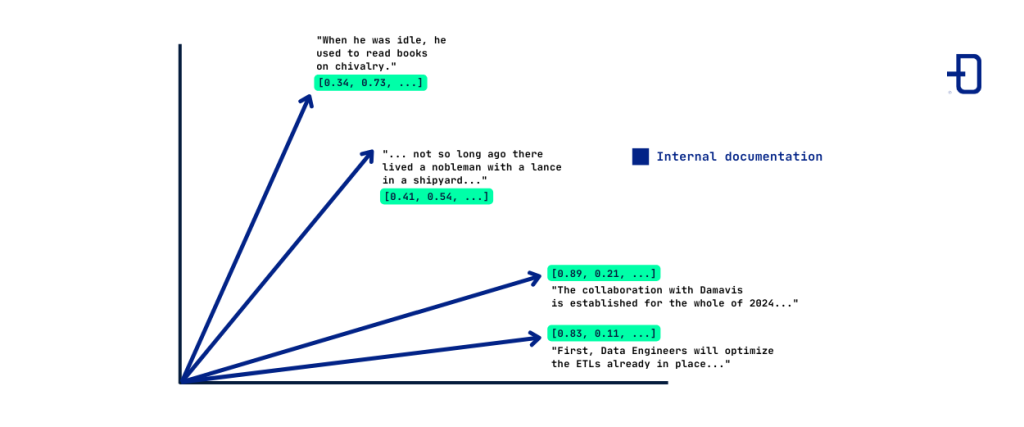
In the image we observe how four different paragraphs have been represented by four vectors, which for simplicity we assume live in a two-dimensional space. In practice, high dimensions are required; a usual embedding model such as text_embed_ada requires 1536 dimensions. The embedding model will be adequate if semantically related texts are mapped to vectors that are close. In practice, embedding models use a complex architecture and neural networks. They are trained on a large corpus of natural language text, seeking to translate semantic closeness into closeness of associated vectors.
The retrieval component of RAG systems is articulated in this way: we consider a set of textual documents (for example, a folder full of PDFs or Markdown files). First, these documents are “chunked” into smaller elements, of a preset maximum length, called “nodes”. Excessive node size will exceed the maximum LLM context, while very small nodes will fail to capture relevant information.
Once these nodes are obtained, their associated vectors are computed through an embedding model. These vectors can be stored in databases specially designed for this type of component-rich data (e.g. Pinecone, Milvus, the pg_vector extension of Postgres, etc.), which store them making an efficient memory management and allowing, through different indexing techniques, to improve the efficiency of the search for neighboring vectors.
When a user makes a query to a RAG system, the embedding corresponding to that query is calculated. The system then uses a closeness metric in vector space and selects the text nodes that are semantically closest to that query. A usual metric for this is cosine similarity.
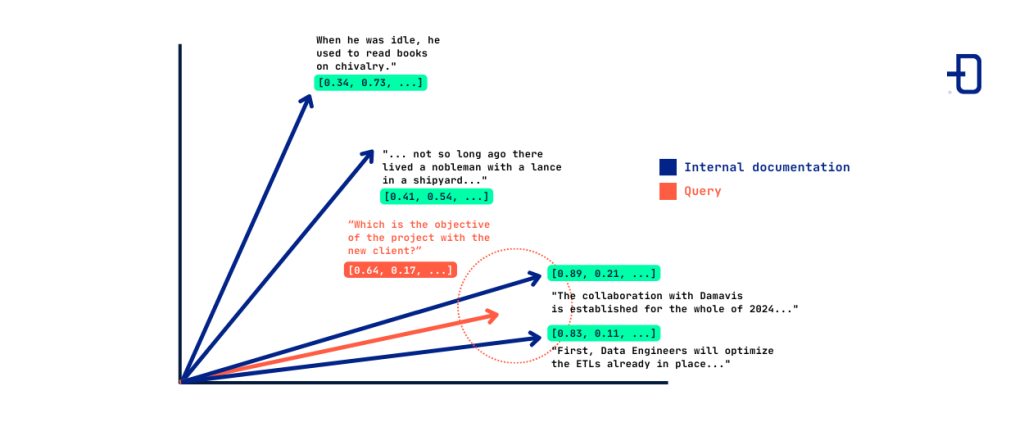
In this example, the question “What is the objective of the project with the new client?” is embedded in a vector (in red) that happens to be close to the vectors that correspond to text referring to projects with a hypothetical new Damavis client. The system will select the text corresponding to these two vectors to subsequently give an answer to the user.
The calculation of the closest vectors can be refined: systems and databases designed for RAG allow enriching the vectors with metadata (information such as date, source, document summary, keywords), making it possible to develop hybrid retrieval strategies between embedding and other classical filtering and keyword search techniques. In addition, it is usual to link different text nodes that have been obtained from the same document, at metadata level.
The computational cost of calculating the semantically closest vectors to a given query vector scales super-linearly (at best) with the size of the documentation, as will be familiar to those who have worked with the k-Nearest Neighbors algorithm.
There are techniques that modify the vector database architecture, allowing to implement approximate searches; this sacrifices the certainty of retrieving the closest documents in exchange for a notable decrease in computational cost, which is important when serving the system in a chatbot when the documentation is large and the admissible latency is low. An example of these approximate computation techniques is HNSW (Hierarchical Navigable Small Worlds).
Embedding is not limited to text; it is possible to compute, through convolutional neural networks (CNN), image embeddings, assigning to each image a vector in a high-dimensional space. Thus, similar images are translated into close vectors under some metric. This is the method that is at the basis of reverse image search tools, for example. Beyond images, embedding is applicable in different variants to other structured document formats (audio, video) and semi-structured (JSON objects, database schemas).
It is important to note that it is possible to use different metrics to measure the closeness between vectors. Some of them are the cosine similarity (angle formed between the vectors) or the L2 norm (the square root of the squares of the differences of the components); the choice of one or the other depends, for example, on the type of data. For text, it is usual to use cosine similarity (where the magnitude of the vectors is less relevant) while for images the L2 norm is used.
Generation
Once the most relevant documents (in a semantic sense) to answer the question have been retrieved, the RAG system must generate an answer based on them. Recall that, in general, the documentation is content that is not in the LLM training data that we will use for answer generation.
The generation implementations can be quite varied depending on the LLM used, the purpose of the RAG system, and the nature of the documentation. As the most basic example, an LLM is queried with the user’s original question, concatenated with the nodes in the documentation that happen to be closest, such as:
User Prompt:
A question follows, and subsequently, pertinent information that should be used to answer that question.
Question:
What is the goal of the project with the new client?
Information:
- “The collaboration with Damavis will extend throughout 2024, in which the Data Science and Data Engineering teams will be involved.”
- “First, Data Engineers will optimize the ETLs already implemented, and the Data Science team will propose new predictive models that will allow to obtain an improvement in the client company’s digital infrastructure costs.”
LLM response:
The goal of the project is to improve efficiency to decrease infrastructure costs.
RAG systems therefore combine advanced search techniques with prompt engineering, and different strategies for processing documents close to the query result in different behaviors, desirable depending on the objective of the system.
Conclusion
In this article the basics of the RAG technique are presented. We have discussed how to convert documents into vectors and how to use embedding models to perform semantic searches on them. This allows to dynamically rescue additional information for an LLM, increasing its capabilities with additional documentation provided by the user.
In a future post we will talk about RAG system implementations through a very popular library called LlamaIndex, as well as exposing some RAG extensions.
If you found this article interesting, we encourage you to visit the Data Science category to see other posts similar to this one and to share it on social networks. See you soon!
